テーブル結合の仕組みを理解する:SQL実践講座(5)
今回掲載の内容
- 前回使用したサンプルを解析する
- 結合が必要になる理由
今回は、前回に引き続き、SQL文での結合の仕方(JOIN)について説明します。まずは、前回の例題3の仕組みをさらに解説していきましょう。
前回使用したサンプルを解析する
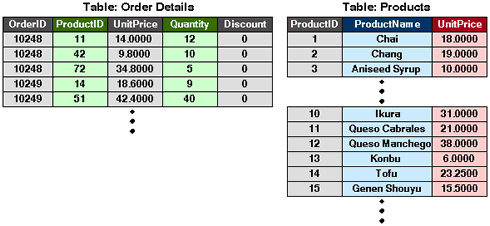 図1 前回の例3で使用した2つのテーブル
図1 前回の例3で使用した2つのテーブル前回(「異なるテーブル同士を結合する『JOIN』句」)の例題3で使用した「Order Details」テーブルと、「Products」テーブルの一部を図1にピックアップしてみました。この2つのテーブルに対して、以下のSQLを発行しました。
【前回の例題3】
SELECT OrderID, Prd.ProductID, ProductName, Prd.UnitPrice, Quantity, Discount FROM "Order Details" Ord INNER JOIN Products Prd ON Ord.ProductID=Prd.ProductID
このSQLが処理される過程を順に見てみましょう。
まず、「Order Details」の1行目をピックアップし、結果リストに埋め込みます。
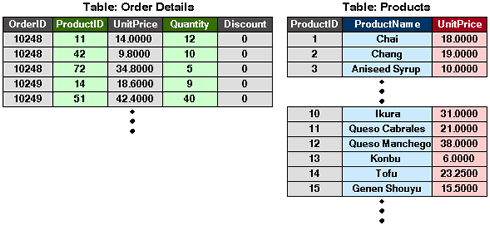
 図2 Order Detailsテーブルから1行目を抽出してきた結果(
図2 Order Detailsテーブルから1行目を抽出してきた結果(次に、「Products」テーブルを検索し、ProductIDが「11」であるものをピックアップし、結果リストに埋め込みます。
 図3 ステップ1の結果に、さらにProductsテーブルの中からProductIDが11であるものを抽出してきた(
図3 ステップ1の結果に、さらにProductsテーブルの中からProductIDが11であるものを抽出してきた(次に、「Order Details」テーブルの2行目をピックアップし、結果リストに追加します。
 図4 同様の操作で2行目も追加する(
図4 同様の操作で2行目も追加する(そしてまた、「Products」テーブルを検索し、ProductIDが「42」の行をピックアップし、結果リストに埋め込みます。
 図5 同様の操作でProductIDが42の行も追加する(
図5 同様の操作でProductIDが42の行も追加する(このような処理が、「Order Details」テーブルのデータがなくなるまで繰り返され、前回の例3の結果リストは完成します。
結合が必要になる理由
そもそも、なぜこのように、複数のテーブルでデータを管理する必要があるのでしょうか? もともと1つのテーブルにすべてのデータが入っていれば結合をする必要もなく、SQL文もシンプルで済むのではないでしょうか?
これは、RDBMSがカード型DBと大きく考え方が違う部分です。詳しい言及はここでは避けますが、概要を説明しましょう。
RDBMSは、1つのデータは1カ所で集中管理するべきだ、という考え方に基づいています。これは、データの整合性を保証するために必要な考え方の1つです。
例えば、例3で使用した「Order Details」と「Products」は、図5の結果リストのように、すべてのOrder Detailsデータに対してProductNameが保存されていても何ら問題がないように思えます。
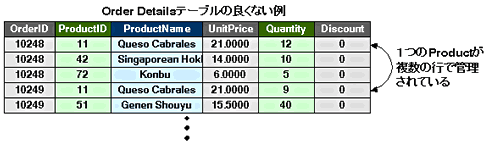 図6 Order Detailsテーブルのよくない例
図6 Order Detailsテーブルのよくない例ただし、このようなテーブル構成にしてしまうと、もしProductIDが11の「Quest Cabrales」の単価が「$21」から「$24」に変更になった場合に、すべてのOrder Detailsに含まれるProductIDが11の行に対して、UnitPriceの更新をしなくてはなりません。また、ほかのテーブルにも同様にProductIDが11のProductのUnitPriceが保存されている場合、それらのテーブルもすべて変更の必要が生じてしまいます。
このように1つのデータが複数の場所に分散している構成だと、データベース全体でデータの整合性を保証するのが、規模が大きなデータベースになるほど難しくなります。これを回避する手段の1つが「1つのデータは1カ所で集中管理するべき」というRDBMSの考え方につながっています。
ここで、「1つのデータ」を抽出する作業のことを、「正規化」と呼びます。例えば、Productを1つのデータの単位と考えて「Products」テーブルを作成する、という作業がこれにあたります。
今回のまとめ
今回は、「結合の仕組み」を紹介しました。次回は、より複雑なJOINの例と、JOINのバリエーションについてを予定しています
- SQL Serverで「デッドロック」を回避する
- トランザクションの一貫性を保証するロック
- トランザクションを用いて注文登録をする
- トランザクションでデータの不整合を防ぐ
- テーブルで複数の処理を実行させるトリガー
- ユーザー定義関数を作成するストアドファンクション
- ストアドプロシージャによる繰り返し処理
- 条件分岐のあるストアドプロシージャ
- ストアドプロシージャの作成
- システム・ストアドプロシージャを用いたロールの詳細設定
- ロールを利用したグループ単位での権限設定
- SQL Serverのオブジェクトに権限を設定する
- Enterprise Managerによるビューの作成
- 作成したSELECT文をDBに登録する「ビュー」
- データの更新と主キーの重要性
- テーブル中のデータ識別に必要な主キーを定義する
- データの登録を行うINSERT文
- CREATE文をさらに使いこなそう
- CREATE文でテーブルを作成する
- SELECT文を統合する「UNION」
- サブクエリーの応用「相関サブクエリー」
- SELECT文の結果を抽出条件に使う
- テーブル結合のバリエーションを増やす
- テーブル結合の仕組みを理解する
- 異なるテーブル同士を結合する「JOIN」句
- 集計を行う「GROUP BY」句
- SELECT文で並べ替えを行うには?
- SQLの基礎 「SELECT」文を覚えよう
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。