第5章 C#のデータ型:連載 改訂版 C#入門(3/4 ページ)
5-6 値型と参照型
ここまで、System.Int32などを紹介してきたが、あえてクラスとは呼んでいなかった。メソッドなどがあるのだから、当然クラスだろうと思った人もいるだろう。ところが、実はこれらはクラスではない。そうではなく、これは構造体と呼ばれるものなのである。構造体は、構造体からの継承ができないなどの制約を除けば、見かけ上はクラスにそっくりである。宣言するためにclassキーワードではなくstructキーワードを使う。
structというと、C/C++の経験者なら「ああ、それなら知っている」と思うかもしれないが、C#のstructは、C/C++のstructとはまったくの別物である。注意されたい。
C#での構造体とクラスの違いは、それが値型であるか参照型であるか、という機能面での違いなのである。
値型とは、情報を引き渡すときに情報をコピーする方式のデータ型である。例えば、本章の冒頭の表で紹介したデータ型はみな値型である。これに対して参照型とは、データの実体がある場所を保存しておき、情報を引き渡す必要がある場合は、データの本体をコピーせず、データの場所だけを伝えるという方式である。この2つは、動作も微妙に違うが、それ以上に大きく違うのが処理効率である。情報を渡すときにいちいちコピーするとなると、小さなデータなら問題ないのだが、大きなデータでは処理速度の低下という問題を招いてしまう。逆に、データが十分に小さいとすると、データの場所を渡すというような回りくどい方法を採るよりも、データそのものをコピーするほうが素早いということもある。そのため、どちらが正解ということはない。主にデータ量という観点で使い分けることが好ましい。
さて、処理の効率が違うといっても、具体的にどれぐらいの差が出るのだろうか? 同じ処理をクラスと構造体で処理する一例を以下に示す。まずはクラスを使った例からである。List 5-5を見てほしい。
1: using System;
2:
3: namespace Sample005
4: {
5: public class Test
6: {
7: public int v;
8: }
9: class Class1
10: {
11: [STAThread]
12: static void Main(string[] args)
13: {
14: Console.WriteLine( DateTime.Now );
15: int count = 10000000;
16: Test [] test = new Test[count];
17: for( int i=0; i<count; i++ )
18: {
19: test[i] = new Test();
20: test[i].v = i;
21: }
22: int sum = 0;
23: for( int i=0; i<count; i++ )
24: {
25: sum += test[i].v;
26: }
27: Console.WriteLine( DateTime.Now );
28: }
29: }
30: }
処理内容は単純である。整数を1個だけ保持するクラスを宣言し、それを1000万個持つ配列を確保して、中に数値を入れて、シンプルな計算を実行するだけである。ちなみに計算の内容に意味はない。
14行目と27行目のDateTime.Nowは、現在時刻を返すプロパティである。これを使って、処理前と処理後の時刻を表示させ、処理に要した時間を調べようというわけである。
これを実行した結果はFig.5-5のとおりである。
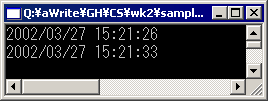 Fig.5-5
Fig.5-5デバッグ・ビルドでの所要時間は約7秒(Pentium 4/1.5GHz、メモリ512Mバイトにて)である。また、メモリ256MバイトのPCで実行すると、仮想記憶が激しくハードディスクにアクセスする。メモリ消費量も大きいのである。
では、構造体を使うとどうなるだろうか? List 5-6に、構造体を使用する形で書き直したソースを示す。
1: using System;
2:
3: namespace Sample006
4: {
5: public struct Test
6: {
7: public int v;
8: }
9: class Class1
10: {
11: [STAThread]
12: static void Main(string[] args)
13: {
14: Console.WriteLine( DateTime.Now );
15: int count = 10000000;
16: Test [] test = new Test[count];
17: for( int i=0; i<count; i++ )
18: {
19: test[i] = new Test();
20: test[i].v = i;
21: }
22: int sum = 0;
23: for( int i=0; i<count; i++ )
24: {
25: sum += test[i].v;
26: }
27: Console.WriteLine( DateTime.Now );
28: }
29: }
30: }
これを実行した結果はFig.5-6のとおりである。
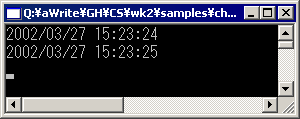 Fig.5-6
Fig.5-6デバッグ・ビルドでの実行時間、わずか1秒未満(Pentium 4/1.5GHz、メモリ512Mバイトにて)。クラスを用いた場合の7秒とは大きな違いである。しかも、実は、このソース・コードの19行目はなくてもまったく問題ないものである。これを取り去れば、差はもっと開く。メモリ256Mバイトのマシンでもスムーズに動くので、メモリ消費量も大きくないことが分かる。
どうして、これほど大きな差がつくのか? その理由は、処理の過程で確保されるメモリの個数の差にある。クラスを用いる場合、1個のインスタンスは、1つの独立したメモリとして確保される。つまり、メモリ確保という処理が1000万回実行されるのである。これに対して、構造体の場合は、配列を作成した時点で1000万個分の構造体を収めるたった1個の巨大なメモリを確保している。つまり、小さな処理を1000万回行うか、大きな処理を1回行うかの差が、この結果なのである。
実は、構造体は、C#がJavaに対して先進的といえる機能の1つである。Javaには、C#のクラスに相当する機能しかなく、そのため、小さなオブジェクトからなる巨大な配列の処理は、効率がよくない。巨大なメモリを1個だけ確保して無数のインスタンスが利用することはC++でも可能なことであり、C#がそれを実現したことは、C#がJavaではなくC++の進化形と考えれば素直に納得できることである。
反面、構造体の利用は危険も伴う。構造体は、制限の厳しいクラスのようなものだが、クラスそのものではない。クラスと思い込んで扱ってしまうと、思わぬトラブルが起きる場合もある。例えば、巨大な構造体を作成してしまうと、構造体は値型なので、別の変数に代入する場合などには、丸ごと中身をコピーする羽目になり、処理効率を著しく落とす。構造体はツボにはまれば効率アップできるが、一歩間違えると処理効率を大きく下げかねない危険があるという事実をよく認識しておいていただきたい。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。