―分かっているようでホントは知らない―実践! ネットワーク・トラブルシューティング:ネットワーク運用管理入門(4)
本連載は「ネットワーク運用管理の基礎」について紹介していきます。読者の皆さんは、「ネットワーク運用管理」と聞くと、多分「あ、あんなことかな?」と、その実作業については何となく理解していることかと思います。この連載では、その「何となく」をもう少し体系立て、まとめることを目的とします。第4回では、さまざまなトラブルケースごとに、トラブルシューティングの考え方や方法を紹介します。
トラブルの原因を絞り込むにはどうする?
【ケース1】
エンドユーザーより、「ネットワークがつながらない」との連絡があった。
対処方法
ネットワークのトラブル事例で最も多いのが、このようなケースです。ここで問題となるのが、「このままでは対応のしようがない」ということです。ただ単に「つながらない」といわれても、その原因は無数に考えられます。その1つ1つを片っ端からつぶしていくなど時間の無駄です。まずは「何が」「どのように」つながらないのかを明確にする必要があります。そのためには連絡をしてきたエンドユーザーに、以下のような質問をします。
- どのような現象から「つながらない」と判断したのか?
- 例えばPCにおけるある操作からそのように判断したとして、同じPCでの、ネットワークを使用する別の操作では結果はどうなるのか?
- 同じ操作を、例えば別のPCで行った場合の結果はどうなるのか?
これらの質問によって、おおよその障害の状態、場合によっては障害の位置が特定できますので、続いてそれをさらに詳細に切り分けていきます。詳細な切り分けのために用いる手段(例えばツールなど)は、障害の状態や位置によってそれぞれ異なりますが、その中でもよく利用されるのがpingコマンドです。
例えば以下のような順番でpingを打っていく(実行する)ことによって、障害個所を絞り込んでいけます。
- localhost(127.0.0.1)へのping
- pingを打った機器自体の動作/設定に異常がないかを確認
- 自端末へのping
- デフォルトゲートウェイへのping
- (上記に加え)
- デフォルトゲートウェイのIPアドレス/サブネットマスク設定に異常がないかを確認のIPアドレス/サブネットマスク設定に異常がないかを確認
- デフォルトゲートウェイのルーティングテーブル設定に異常がないかを確認
- リモートホストへのping
- (上記に加え)
- リモートホストのIPアドレス/サブネットマスク設定に異常がないかを確認
- リモートホストのルーティングテーブル設定に異常がないかを確認
またpingとともによく利用されるのがtraceroute(またはtracert)です。tracerouteによって、ターゲット端末までのネットワーク経路(ルート)が想定どおりのものか、または正常に機能しているか否かの確認を行うことができます。
ただ、pingにせよtracerouteにせよ、確認ができるのはIPのレベル(OSIでいうところのネットワーク層)であり、それより下位の階層(データリンク層や物理層)でのより詳細な確認を行うためには、プロトコルアナライザやケーブルテスタなどを用いる必要があります。
ネットワーク経路とは別に、各ネットワーク機器の詳細な状態の確認が必要な場合は、SNMPを用いて行うことも検討します。
エラーフレームがネットワーク内にあふれてしまう≫
【ケース2】
エンドユーザーより「ネットワークが遅い」との連絡があったためいろいろと調べた結果、ネットワーク内にエラーフレームが多発していることが分かった。
対処方法
エラーフレームとは、プロトコルアナライザなどで見た場合、本来のフレームデータよりも短く途中で切れたように見えたり、CRCのエラーなどと表示されるものを指します。エラーフレーム発生には、以下のような原因が考えられます。
NICが動作異常を起こしている場合、しばしばフレームの送出途中で送信をやめてしまうことがあります。結果としてネットワーク内にエラーフレームがあふれるような状態になるわけです。送出中断の理由はいろいろですが、例えば、コリジョンの誤検出などが挙げられます。送出途中で何らかの信号をコリジョン発生と誤認し、そこで送出をやめてしまうわけです。
上記はNICの不具合によって、発生していないコリジョンが発生したと誤認してしまったことによる問題事例ですが、これとは別に、同じくNICの不具合で実際にコリジョンが多発する問題事例もあります。原因はNICが通常持っているオートネゴシエーション機能にあります。これは伝送速度や伝送モード(ハーフまたはフル)を接続相手とネゴシエートするための機能です。何らかの原因でオートネゴシエーションがうまく働かず、その結果、接続している機器同士で異なる伝送速度、伝送モードになってしまうと、通信がうまくできない、またはコリジョンの発生として現れたりします。
ネットワークケーブルの不具合は、ケーブルの品質の低下を意味します。品質が悪くなり過ぎると完全に通信不能になるので、逆に障害としてもはっきり分かるのですが、規格ぎりぎりの品質の場合はやっかいです。つながったりつながらなかったりと、ネットワークは非常に不安定な状態になります。NICの不具合の場合と同様に、CRCエラーなどが大量に検出されるようになります。ただNICの不具合の場合と異なるのは、エラーとなるフレームを送出する機器が、NIC不良の1台の機器だけには限定されずに、問題のケーブル周辺の機器すべてとなる点が異なります。
リピータやシェアードHUBも、その内部構造はケーブルの集合体ですので、それらが不具合を起こせば、結果はケーブルの不具合の場合と同様になります。
ネットワークが非常に不安定な状態になる
【ケース3】
ネットワーク機器がいきなり再起動やハングアップをしてしまい、ネットワークを安心して使っていられない。
対処方法
メーカーによるフルサポートが受けられる状況であればよいのですが、予算的、スケジュール的に難しい場合もあるでしょう。そのような場合は、以下のようにトラブルシューティングを自力で行わなければなりません。
1.再現性の確認
まずどのような条件で発生するのかを明確にします。例えば、
- 特定のコマンドを実行したとき
- 特定のプログラムが起動したとき
- 特定の日時に至ったとき
- 特定の状況(使用率が一定のいき値を上回った/下回った、など)に至ったとき
2.過去事例の確認
1で確認した再現の条件から、同一機種における過去事例を確認します。
3.対応方法の確認/実施
2で過去事例が確認できたトラブルであり、併せて対応方法に関する情報もあれば、それに基づいて対応を行えばよいわけですが、過去事例がない、または対応方法の情報がない場合、自力で対応方法を考える必要があります。
通常考えられる方法として、1つは機器自体の交換があります。ただ機器交換は高いコストの発生ともなるので、その前にもう1つの対応方法として、機器の内部で使用しているソフトウェアのバージョンアップを検討します。例えばルータやスイッチなどは、その内部に、処理制御に必要なプログラム(ソフトウェア)を持っています。このソフトウェアの不具合(バグ)によって、機器自体の動作異常が引き起こされている可能性がありますので、不具合(バグ)が改修された、より新しいバージョンのものに換えてみることを検討します。
機器不具合における基本的な2通りの対応方法とは別に、もう少し大掛かりな対応が必要になることもあります。例えば、ネットワークの構造から見直しが必要な場合です。機器不具合の原因(再現の条件)が機器自体の問題ではなく、その機器を使用している環境(ネットワークの構造)にあると、問題を発生させる機器を別のもの(別機種、別メーカー製)に交換して、その場をなんとかしのぐような対応では、将来どこかにしわ寄せがくることが多いものです。できればネットワーク構造を根本から見直すことを考えた方がよいでしょう。
ネットワーク機器内のパケット消失(ロスト)
【ケース4】
エンドユーザーより、「ネットワークが遅い」との連絡があったため、いろいろと調べた結果、スイッチ内でパケットが消失していることが分かった。
対処方法
ネットワーク機器におけるパケットの消失(ロスト)には、以下のような原因が考えられます。
- ネットワーク機器がエラーフレームと判断して破棄
- ネットワーク機器の性能不足による破棄
パケットをエラーフレームと判断して破棄する動作は、スイッチなどのネットワーク機器が持つ基本動作なので、破棄されたパケットが実際にエラーフレームである以上は、問題はエラーフレームを発生させている別のネットワーク機器にあることになります。実際にはエラーフレームでないのにもかかわらず、スイッチがエラーと判断して破棄しているような場合には、なぜそのような判断となってしまうのか、スイッチを中心にさらに調べる必要があります。
スイッチやルータなどのネットワーク機器は、受信ポートで受信したパケットを送信ポートへコピーして送信し直す過程で、フィルタリングチェックやルーティング計算などの各種処理を行っています。このような処理を、機器を通過するパケットごとに行うためそれなりの時間がかかり、一定の時間内に処理(通過)できるパケット数には限りがあります。仮に、トラフィックの集中などで、処理できるパケット数の上限を超えるような状態になれば、処理しきれないパケットが破棄される事態になります。
性能不足によるパケットロストは、ロストを引き起こしているスイッチやルータなどのネットワーク機器だけの問題とも限りません。それらの機器に接続されているネットワーク回線が、そもそも域幅不足であってもロストが発生します。
また、スイッチではその内部に、スイッチに接続している各ネットワーク機器のMACアドレスを記憶しておくためのテーブルバッファを持ちますが、ここに保存できる数以上のネットワーク機器が存在した場合、テーブルバッファに収まりきらずバッファオーバーフローとなり、結果的にパケットロストを引き起こすこともあります。
ブロードキャスト・ストームの発生
【ケース5】
ある日停電が発生し、電力復旧後にネットワークが使用できない状態になった。調べてみると、ネットワークを構成しているスイッチのパイロットランプ(データ送受信時に点滅)が点灯したままの状態であった。
対処方法
このケースの場合、ネットワーク構成は以下のようになっているとします。
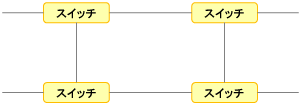 図1 問題が発生したネットワーク構成
図1 問題が発生したネットワーク構成通常、データ送受信時に点滅するはずのパイロットランプが点灯したままという状態から、(ブロードキャスト)ストームが発生していることが考えられます。ストームとは、ループ状に構成されたネットワーク内を、ブロードキャストなどのあて先指定のないフレームが際限なく回ってしまう状態を指します。そのため送受信を表すパイロットランプが点灯したままの状態となるわけです。
ネットワークがループ状に構成されていれば、そのような状態になるのは当たり前といえば当たり前なのですが、このような構成は、回線の障害対策の1つである冗長化を図るうえで必要な措置でもあります。そこで通常は、スイッチの機能の1つである「スパニングツリー」によって、わざとネットワークの一部を使用不能の状態にしておきます。
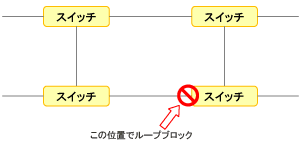 図2 スパニングツリーの状況
図2 スパニングツリーの状況つまりスイッチのうちの1台(場合によっては複数台)の特定のポートを、スイッチ自体がブロック状態(ブロッキング/送受信不能状態)にし、ネットワークがループ状になることを回避します。もちろん、いざ回線の障害が発生した際に、せっかくの迂回(うかい)路が使用できないのでは意味がないので、障害発生が感知できたと同時に、ブロックしていたポートは使用可能な状態(フォワーディング)にされます。
このような、ポートのブロック/ブロック解除をスイッチ自体で行えるようにしているのが、「スパニングツリープロトコル」です。そして当トラブルケースの原因は、このスパニングツリープロトコルでのスイッチ間の情報のやりとりが、うまくいかなかったことによるものです。
各スイッチは、どのスイッチのどのポートをブロック状態にするのか、スパニングツリープロトコルによる情報のやりとりで相談しながら決定します。当トラブルケースのような、停電発生→スイッチダウン→電力回復→スパニングツリープロトコルによるネゴシエート、というような一連の動作の途中では、各スイッチの状態は不安定であり、時としてネットワークがループとなってしまう場合があり、結果として当トラブルケースのようにストームが発生してしまうわけです。
また停電でなくても、単純にスイッチの電源を頻繁にON/OFFする(それによってスパニングツリーが機能し、ネットワークのトポロジ変更が行われる)ことでも、不安定な状態となってしまいます。
スパニングツリーがうまく働かずストームが発生したような場合は、スイッチのポートからケーブルを抜き差しすることによって問題が解消することがあります。
上記のトラブルケースは、スイッチにより構成されたネットワークにおいて起こり得るものですが、同様なトラブルは、複数台のルータにより構成されたネットワークにおいても起こり得るものです。ルーティングのためにルータが内部に持つルーティングテーブルの情報更新は、スイッチにおけるスパニングツリープロトコルと同様にネットワークを通してプロトコルで、より正確に述べるならばルーティングプロトコルによって行われます。このルーティングプロトコルによる情報のやりとりが、場合によってうまくいかなかったり、またルーティングプロトコル自体のそもそもの仕様によって、思ったとおりの動きをしない場合もありますので、注意する必要があります。
今回は代表的なネットワーク・トラブルとその対処法について、5つのケースを取り上げて解説しました。本連載は今回で最終回です。ご愛読いただき、ありがとうございました。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。