―分かっているようでホントは知らない―ネットワーク健全化の実作業はこれだけある:ネットワーク運用管理入門(3)
本連載は「ネットワーク運用管理の基礎」について紹介していきます。読者の皆さんは、「ネットワーク運用管理」と聞くと、多分「あ、あんなことかな?」と、その実作業については何となく理解していることかと思います。この連載では、その「何となく」をもう少し体系立て、まとめることを目的とします。第3回は、ネットワーク運用管理で行うべき日々の業務内容を紹介していきます。
運用管理業務は「監視」から始まる
ネットワーク運用管理で行うべき日々の業務は、まず何よりも「監視」ありきです。第1回の記事でも紹介したとおり、そもそも運用管理業務とは、「日々物事を滞りなく、うまく活用すること」ですので、それがうまくいっているか否かの監視が必要です。
ネットワークを監視した結果に基づいて、その後に以下のような3つの業務を行うことになります。
- 障害管理業務
- 性能管理業務
- セキュリティ管理業務
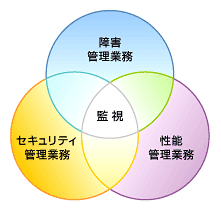 図1 管理業務と監視の相互関係
図1 管理業務と監視の相互関係監視は、各業務目的に沿ったそれぞれの方法で行う必要がありますので、実際の監視方法については、各業務の一環として紹介します。
また各管理業務は、図1にあるように一部が重複したものです。例えば、「ネットワークが遅い」という事象は、基本的には性能管理業務の範囲事象ですが、考えようによっては障害管理業務で扱うべきものかもしれません。
それぞれの管理業務ごとに行うべき内容を解説していきましょう。
障害管理業務は「早期発見」「早期解決」「再発防止」
障害管理業務の主な目的は以下の3つになります。
- 障害の早期発見
- 障害の早期解決
- 障害の再発防止
障害の早期発見
ネットワークの障害は、ネットワークを利用しているユーザーが最初に気が付くものです。そこで通常は、ユーザーからの障害連絡がトリガとなって「発見」となるわけですが、それとは別に、管理者の側でも、障害を早期に発見するための仕掛けを用意しておきたいものです。
障害発見の方法は、発見すべき障害の種類によって異なります。発見すべき障害は、事前にポリシーとして定めたものがこれに当たります(ポリシー策定については、第2回「ネットワーク健全化のポリシーを作ろう」を参照してください)。
例えば、ネットワークを構成している機器が、単純に起動しているか否かを確認するためによく用いられるのがpingコマンドです。pingを各機器に定期的に打つ(送信する)ことによって、該当の機器が「生きて」いるか「死んで」いるかの判別がつきます。
もう少し細かく各機器の状況を把握するためにはSNMPを用います。単純に障害発生だけを検知するのであれば、機器からの状態通告(TRAP)を拾い上げる仕組みを用意し、その結果を何らかの形で警告メッセージとして出力し、管理者に知らせるようにします。障害発生時にいきなり知るのではなく、事前に「予測」できるようにするには、定期的に各機器に対しSNMPによる問い合わせ(GET REQUEST)を行い、そこから得られた情報によって予測します。
障害の早期発見において考慮が必要なのは、何をもって「障害」と見なすのかという点です。完全にネットワークが使用できないケースであれば、それはもちろん障害ですが、それに対して「取りあえず接続はできるが何となく遅い」などのケースは厄介です。どこまでが正常であり、どこからが障害なのかを、あらかじめポリシーによって、明確な数値で判別できるように定めておきます。
障害の早期解決
障害が発見されたら、今度はそれをいかに早く、かつ確実に解決するかがポイントとなります。その際にまず重要なことは「慌てないこと」です。とはいうものの、いざ事が起こってみると、ユーザーからは「早く何とかしろ」とせっつかれ、慌てて対応した結果、余計に問題を複雑にしてしまったり……。
そんな事態にならないためには、あらかじめ対応手順を決めておくことが必要です。基本的には発生が予想される障害ごとに、発生した場合を想定して手順を決めておきます。例えば次のようなフロー図に基づいた手順で考えます。
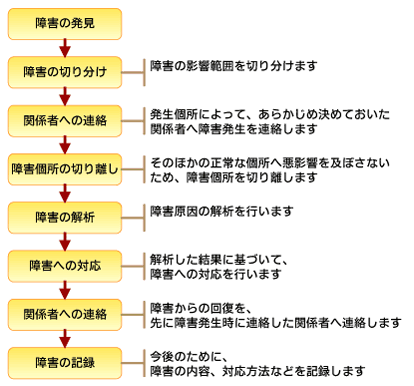 図2 障害発生時の対応手順フロー図
図2 障害発生時の対応手順フロー図例えば、図2の「障害への対応」部分では、機器の故障であれば正常なものと入れ替えるなど、障害の種類によってある程度、手順を決めておけます。考慮が必要なのは、障害の切り分けや対応において、通信事業者やメーカーとの連絡体制をどうするかという点です。障害発生時の連絡先として通信事業者やメーカーを含めておき、障害の切り分けから任せるのか、またはある程度の切り分けを行ったうえで対応だけ任せるのかを明確にしておきます。
また障害の切り分け自体にも考慮が必要です。前述したとおり、障害はまずユーザーによって発見されます。そこから「解決」が始まるわけですが、なにぶんユーザーによる障害発見の報告は系統立てたものではなく、必要な情報がそろっていません。「ネットワークがつながらないのだけど」といわれただけでは、障害の切り分けや解析はできません。ユーザーから必要な情報を引き出すための方策が必要です。具体的には、質問事項をチェックリストにまとめておき、ユーザーからの障害連絡があったら、このチェックリストに沿って質問を行い、必要な情報を収集します。
障害の再発防止
障害の再発防止ではまず、すでに発生してしまい、その対応を行った障害に対し、再発を防止するための対策を立てることから始めます。今回の対応が一時的なものであればもちろん、そうでない場合も、そのほかの個所で同様な障害が発生するか否かの検討を含め、システムの全体的な再発防止策を検討します。
まだ発生していない障害でも、未然に防ぐにはどうしたらよいかを考えることも必要です。具体的には以下のような作業を行っていきます。
- 各機器やソフトウェアの構成情報の管理
- 変更履歴の記録
- 機器や環境の定期的な調査
- 十分なリソース配分
- 機器の追加や構成変更前の稼働確認
- 重要なネットワーク機器や回線の冗長化
- ネットワーク管理システムの導入
性能管理業務は「性能維持」「拡張対応」
性能管理業務の主な目的は以下の2つになります。
- ネットワーク性能の維持
- ネットワークの拡張対応
ネットワーク性能の維持
性能管理業務の主な目的は、ネットワーク性能の維持にあります。つまりネットワークのパフォーマンスを一定のレベルに維持することが目的です。具体的には、さまざまな性能管理項目について、あらかじめ基準値を定めておき、その基準値を超えたり、または下回らないように、その対応を行うことになります。性能管理項目には、次の表で示されるような各項目があります。
| 分類 | 管理項目 | 概要 |
|---|---|---|
| ネットワーク自体に関する項目 | レスポンスタイム | データ端末の応答時間(秒) |
| スループット | 単位時間当たりの情報伝達量 | |
| トラフィック量 | ルートごと、区間ごとの通信量 | |
| トラフィック分布 | 時間分布、暦年分布、地理的分布 | |
| 回線使用率 | 通信回線の使用率(%) | |
| bit誤り率 | 伝送途中のエラー率(%) | |
| ルートビジーカウント | 網ふくそうの回数 | |
| 仮想経路数 | パケット交換網でいうVCの数 | |
| 機器に関する項目 | CPU使用率 | ネットワーク機器のCPU使用率(%) |
| バッファ使用率 | ネットワーク機器内部のバッファ使用率(%) | |
| キューチェーンバッファ数 | ネットワーク機器内部のキューチェーンデータの数 | |
| パケット処理 | 単位時間当たりのパケット処理数(PPS) | |
| 交換処理 | 単位時間当たりの交換処理数(CPS) | |
| 表1 ネットワークの直接的な性能項目 | ||
上記の表の各項目は、ある程度直接的に性能を表すものですが、これらのほかに、統計情報として、間接的に性能を表す項目もあります。
| 項目 | 統計数値 |
|---|---|
| 送受byte数 | 一定時間に流れたbyte数 |
| 送受フレーム数 | 一定時間に流れたフレーム数 |
| 送受フレーム種類 | 上記フレームの種類 |
| 送受パケット数 | 一定時間に流れたパケット数 |
| 送受パケット種類 | 上記パケットの種類 |
| エラーカウント | CRCエラー、送信アンダーランなどのエラー |
| 表2 ネットワークの間接的な性能項目 | |
対応方法としてまず考えられるのが、ネットワークトラフィックを監視するためのツールを用いて、現状でネットワーク内にどのようなトラフィックがあるのかを調べることです。トラフィック量の異常な増加によってパフォーマンスが低下しているのであれば、ツールで調べることによって、すぐに解明できます。
その際に、ネットワーク内を流れているトラフィックのうち、通常あり得るものと、そうでないものを判別するための基礎的な情報が必要となります。各サーバやクライアントから、いつ、どのようなトラフィックが発生するのかを把握しておく必要があります。
そのうえで、通常あり得ないトラフィックとその発生元を突き止め、なぜそのような状態になったのか原因を調査します。
ネットワークの拡張対応
ネットワークを取り巻く環境は常に変動しています。変動の中でも特に大きなものは、新たに社員が入社したなどのユーザーの増加がこれに当たります。ユーザーの増加分だけネットワークトラフィックも増え、それまでのネットワーク性能を維持することが困難になる場合があるわけです。
あらかじめ判明しているイベントであれば、それに備えることも可能となります。組織内の連絡体制を確立し、組織内で予定されているイベントの情報を取得します。それとは別に、環境の変動に伴うネットワークの挙動を予測するための基礎データを収集しておきます。例えば、現状のユーザー数当たりのトラフィック量や、各機器当たりの使用率などの情報です。
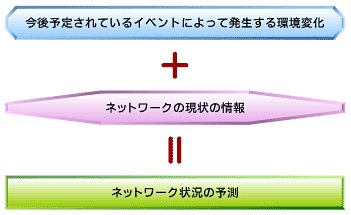 図3 ネットワークの状況を予測するためのフロー図
図3 ネットワークの状況を予測するためのフロー図ユーザー数の増加だけでなく、新たなシステムの稼働などによってもトラフィック量が増加します。新たなシステムが、いつ、どのようなトラフィックをどのくらいの量だけ出すのかの情報を収集します。
セキュリティ管理業務は「クライアント」「サーバ」「ネットワーク」の維持
セキュリティ管理業務の主な目的は以下の3つになります。
- クライアントセキュリティの維持
- サーバセキュリティの維持
- ネットワークセキュリティの維持
いずれもあらかじめ「(セキュリティ)ポリシー」として、組織単位に決定し、文書化されたものに従って行う業務です。
共通的な業務作業
クライアント、サーバ、およびネットワークのそれぞれに対するセキュリティ管理業務に共通な作業があります。
セキュリティ情報の収集/配布
セキュリティを維持していくうえでは、どのような脅威(リスク)があるのか、またそれによってどのような脆弱性があるのかを常に認識していなければなりません。そして脅威と脆弱性は日々新たなものが登場・発見されています。常に最新の情報を入手し、それに基づく対応が必要となります。
また収集したセキュリティ情報は、セキュリティ担当者だけが認識していればよいものではありません。セキュリティ対策は担当者だけでなく、一般ユーザーをも巻き込んだものでなければなりません。入手した情報のうち、一般ユーザーにも公開すべき情報は、すぐにそれを何らかの方法で公開していきます。
攻撃の発見・対応・記録・改善
セキュリティ的な事象(インシデント)が発生した場合、つまり何らかの攻撃が行われたと判明した場合、それに対応する必要があります。対応は作業フローに基づいて行うべきですが、基本的には前述した「障害発生時の作業フロー」と同じになります。
クライアントセキュリティの維持
クライアントコンピュータ、およびそれを利用するユーザーのセキュリティを維持します。
ユーザーのセキュリティ意識の向上
まず行うべき業務は、ユーザーのセキュリティ意識の向上です。セキュリティの維持は、セキュリティ担当者だけではなく、ユーザー1人1人に「セキュリティ対策は重要」という意識がないと実現できません。ユーザーに求めるのはあくまでも意識の問題であり、技術的な知識を要求するものではありません。
啓もう的な講習会を実施したり、メールマガジンなどで定期的にセキュリティ情報を公開して、日々、ユーザーのセキュリティ意識の向上に努めます。
業務以外のWeb参照禁止
これもユーザー意識によるところが大きいのですが、業務要件以外のWeb参照を禁止することが必要です。これを行わず、ユーザーに好き勝手にネットワークを利用させると、例えば、ネットワーク帯域を浪費することになり、また、ウイルスの感染や機密情報の漏えいにつながります。プロキシがあれば、URLやキーワードなどでフィルタをかけて、アクセスをブロックし、その際にログを記録し、後でユーザー自身、またはその上司などに提示することによって抑止効果を狙います。
パッチの適用
OSやアプリケーションの脆弱性を突く脅威が日々登場してきています。セキュリティ情報の収集を怠らず、その結果に基づいて必要なパッチの選択、適用を行います。
ただ、この作業を個々のユーザーに行わせるのか否かという点は考慮が必要です。ユーザーのITリテラシ、スキルにもよりますが、ユーザーに作業を任せると均一な適用は望めず、結果的にネットワーク全体のセキュリティ強度を低下させることにもなります。強制的、統括的な何らかの仕組みを用いることが必要です。
アンチウイルス(定義ファイル)
パッチとともに重要になるのが、アンチウイルスソフトの利用です。特にウイルス定義ファイルの更新が重要です。せっかくアンチウイルスソフトがインストールしてあっても、定義ファイルの更新が行われていないと、対応できないウイルスの数がそれだけ多くなり、感染の危険性も高まります。
これに関しても、個々のユーザーに任せると、正しく行われないこともありますので、何らかの強制的な仕組みが必要です。
ヘルプデスク
ユーザーからの問い合わせや、インシデント連絡の窓口となります。セキュリティ対策がユーザーを巻き込んだものとなる以上、このような窓口が必要です。
違法クライアントのチェック
ウイルスの侵入経路の1つとして、ユーザー所有のコンピュータ、特にノート型コンピュータの企業ネットワークへの無断接続があります。また、不正ユーザーが企業ネットワークへ無断接続したうえで、サーバなどに不正侵入する可能性もあります。
このような脅威を防ぐ意味で、ネットワークに接続中のコンピュータの洗い出しチェックを定期的に行ったり、スイッチなどのネットワーク機器による無断接続の防止措置を施す必要があります。
アカウント管理(パスワード使用期限)
不正侵入の1つの手法として、ユーザー詐称があります。不正ユーザーは、まずは正規のユーザーアカウントとパスワードの情報を取得しようと試みます。特にパスワードについては、頻繁に変更することが対抗措置となります。あらかじめ使用期限を設け、それに従って、ユーザーに変更を促します。
サーバセキュリティの維持
サーバコンピュータのセキュリティを維持します。各サーバがどのような用途でどのように利用されているのか、各サーバ上でどのようなサービス(デーモン)が動いているのかを把握しておく必要があります。
パッチの適用
クライアントコンピュータと同じく、OSやアプリケーションに関するセキュリティ情報の収集を怠らず、その結果に基づいて必要なパッチの選択、適用を行います。
アンチウイルス(定義ファイル)
こちらもクライアントコンピュータと同じく、特にウイルス定義ファイルの更新が重要です。
バックアップ
いかにセキュリティの防御を固めておいたにせよ、いつかは破られてしまうとの前提に立ち、その事態に備えておくことが必要です。具体的にはシステムやデータが破壊されてしまってもよいように、バックアップを用意しておきます。単純なデータバックアップだけでなく、機器や回線までも含めた、システム全体でのバックアップ(デュアルシステム)を行っておけば、回復までのタイムラグを短縮できます。
ログチェック
サーバは特に攻撃対象にされがちです。サーバに対する攻撃が行われたのか、または行われつつあるのかを把握するために、サーバ上のさまざまなイベントをログに記録し、それを定期的にチェックします。
ログには、サーバで稼働しているOSのログと、OS上で稼働している各種のサービス(デーモン)のログがあります。OSログでは、システムの起動、ユーザーのログイン/ログオンの記録、コマンドやプログラムの実行記録などをチェックします。サービス(デーモン)のログでは、サービス(デーモン)自体の起動の記録、コンフィグ(設定)の記録などに注意します。
データ改ざん/破壊チェック
サーバには通常、ユーザーが共有するデータなどがあります。このデータが改ざんされたり、破壊されたりすると業務が停止し、損害が発生します。
サーバ上のデータは、改ざんや破壊されていないことを定期的に確認する必要があります。そのためにはデータファイルのタイムスタンプやサイズをチェックしたり、チェックサムによる改ざんチェックなどを行います。
ネットワークセキュリティの維持
ネットワーク全体のセキュリティを維持していきます。内部ネットワークと外部ネットワークをつなぐ経路にはどのようなものがあるのかを把握しておく必要があります。
IDS(Intrusion Detection System)ログチェック
ネットワーク型IDSとホスト型IDSを、それぞれ必要な場所に設定しておきます。その結果ログを定期的にチェックし、侵入の有無を調べます。
ファイアウォール・ログチェック
ファイアウォールの動作ログを定期的にチェックします。特に通過をブロックしたパケットに注意します。
ネットワーク機器(ルータなど)ログチェック
ルータなどのネットワーク機器が有しているログ機能を利用して、アクセスコントロールの記録やコンフィグ(設定)の記録、および機器の再起動記録などを定期的にチェックします。
今回はネットワークの監視に基づいて発生する管理業務の具体的な内容を解説しました。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。