ThreadとHashMapに潜む無限回廊は実に面白い?:現場から学ぶWebアプリ開発のトラブルハック(10)(3/3 ページ)
【第五章】机上(シミュ)る
この手の机上シミュレーションでは、問題をどれだけ抽象化できるかが腕の見せどころとなる。3つの抽象化観点を紹介しよう。
- シミュレーション対象プログラムの抽象化
- プロセスの抽象化
- データの抽象化
■【1】シミュレーション対象プログラムの抽象化
シミュレーション範囲を限定し、プログラムの各実行ステップをひとまとめにしてブロック化する。それにより、シミュレーションの探索範囲を小さくできる。このときのポイントは、更新される可能性のある共有情報の参照や更新を1つのブロックとし、それ以外のローカル情報の参照や更新をブロック内に含めることだ。
まずは、シミュレーション範囲を主に、先ほどの「リスト2 HashMapのtransferメソッド」の9〜13行目の繰り返しと限定した。「e.next」が更新および参照の対象となるため、「e.next」関連の処理を独立したブロックとする必要がある。それ以外については、近隣のブロックに含めて問題ない。ここでは、次のようにブロック化を行った。
 図3 ブロック化されたプログラム
図3 ブロック化されたプログラム■【2】プロセスの抽象化
対象プログラムを実行するプロセスを抽象化する。ここでは単純に、動作するスレッド数を2と限定する。今回の問題では、2スレッドで循環リストが生成されることを示せれば、3スレッドでも4スレッドでも問題が発生するといい切れるためだ。
また、プロセスは3つの変数を持つものとし、それぞれ、現在処理中の要素e、次に処理する予定の要素next、要素を格納する先であるテーブル「tbl」とする。
■【3】データの抽象化
処理対象のデータを抽象化する。ここでは、処理対象のデータを同じハッシュ値を持つ2つの要素と限定した。また、格納されているキーと値は考慮しないものとする。要素をそれぞれA、Bとし、Aの次要素をB、Bの次要素はnullとする。ポイントは、同じハッシュ値を持たせることだ。そうすることによって、新しい格納先のインデックスも同じになり、シミュレーションが簡易化する。
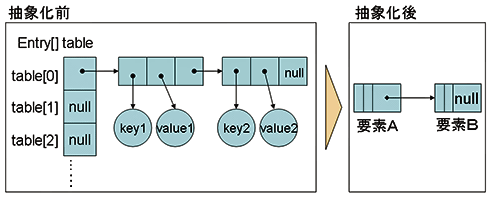 図4 データの抽象化前と後
図4 データの抽象化前と後まとめると、要素が2つのリストの順序を2つのスレッドで同時に入れ替える処理として扱う。同一ハッシュ値を持つ2つのオブジェクトがHashMapに格納されており、かつ2つのスレッドが同時にtransferメソッドを呼び出したとき、ということになる。
■机上シミュレーション開始!
それでは、机上シミュレーションを始めよう。
■初期ステップ
 図5 初期状態
図5 初期状態図5は、各スレッドが実行したステップによって、状態がどのように変化していくかを時系列で表している。スレッドの変数としてe、next、tblを、要素の次要素としてnextをそれぞれテーブルのカラムとして表現している。現在は初期ステップにいるため、スレッド1およびスレッド2の現在処理中の要素をA、要素Aの次要素をBとし、それ以外はすべてnullである。
■1ステップ目
 図6 1ステップ目実行直後
図6 1ステップ目実行直後スレッド1がステップ1を実行した様子である。ステップ1では、スレッド1のeに格納されている要素のnextを、自身のnextに格納する。図6では、どの要素のnextにアクセスするかを決定する変数の値を赤色太文字で表現している。
■2ステップ目
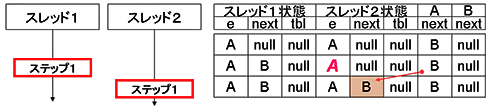 図7 2ステップ目完了直後
図7 2ステップ目完了直後スレッド2がステップ1を実行したときの様子である。これも、1ステップ目の処理と同等のことが、スレッド2の状態で発生している。
■3ステップ目
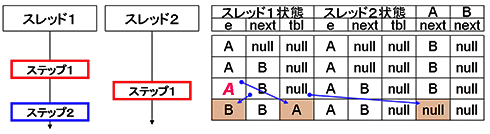 図8 3ステップ目完了直後
図8 3ステップ目完了直後スレッド1がステップ2を実行したときの様子である。ステップ2では、nextの値をeに、eの値をtblに、tblの値をeが指し示す要素のnextに格納する。ここでは、eの値がAであるため、Aのnextにtblの値を格納している。
■そして、Nステップ目へ
このように、あるパターンに沿ってスレッド1およびスレッド2を実行していくと……。
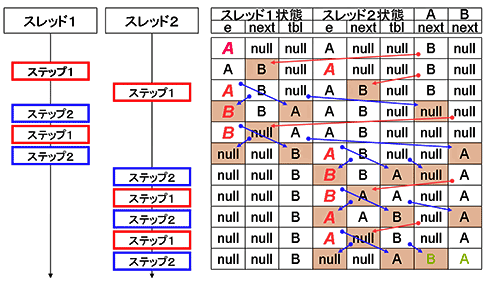 図9 循環参照ができるパターン
図9 循環参照ができるパターンあっけなく循環参照ができてしまった。なぜこんなにも簡単に循環参照が生まれてしまったかというと、スレッド1がAからBに対する参照を、BからAへと変更したにもかかわらず、スレッド2のローカル状況では、Aの次要素がBであると認識してしまっている点であろう。
【最終章】防止(ふせ)ぐ
今回は、同期化せずにHashMapを利用したために発生したトラブルハックを紹介したが、いかがだっただろうか。
■並列性を意識せずともプログラムが書けてしまう時代
普段から業務や趣味でプログラムを書いている人にとっては、同期化せずにHashMapを利用すること自体、信じられないことかもしれない。しかし、サーブレットを直接記述していた時代とは違い、何らかのフレームワーク上で動作するプログラムを記述し、並列性を意識せずともプログラムが書けてしまう最近の流れのおかげか、この手のトラブルが増えてきているように感じている。
■スレッド周りのトラブルは見え方が多岐にわたる
同時に、何度もいうがスレッド周りのトラブルは解析が難しい。今回は、事象として目に見えているため、比較的解析しやすいトラブルだったと感じている。しかし、メモリの問題とは異なり、スレッド周りのトラブルは見え方が多岐にわたるため、迷宮入りしてしまう場合も少なくない。
今回のバグは、ソースコード規約にて制限するか、ソースコードレビューにより発見されることが理想だった。しかし現実には、利用するすべてのクラスについてスレッドセーフか否かを判断することは難しく、またドキュメントに記載されていない場合もあるため、確実に防ぐことはできない。
■スレッド周りの故障を効率よく解析するための実験
今回のトラブルハックをきっかけに、スレッド周りの故障を効率よく解析できないか、技術動向をあらためて追っている。現在は、プログラム解析技術および形式的検証(モデル検査)技術が最有力と感じており、前者ではWALA、後者ではspinおよびJava PathFinderに注目していろいろな実験を行っている。成果が出次第、この場を借りて発表したい。
■最後に一言、最初の一歩
最後に、一言。「トラブルが起きたら、再起動する前にスレッドダンプは取っておこう」迷宮入りを防ぐ、最初の一歩だ。
【補足】そのほかのマルチスレッド・トラブル
冒頭で挙げた3つのトラブルのうち、前半2つについて、簡単に補足する。興味のある方は参照されたい。
■【1】ロックやリソース取得の競合による性能劣化
| 症状 | ハードウェアリソースに余裕があるにもかかわらず、性能が十分に出ていない |
|---|---|
| 発見方法 | 性能試験。本番環境でかつ実サービスに近い高負荷状況を作り出し、システムが十分な性能で動作することを確認する |
| 解析方法 | 競合部分の発見。処理ごとの実行時間を計測する、待機時間の多い処理を検出する、実行シーケンスから処理が直列化されている部分を特定する、などが考えられる |
| 対策方法 | 競合部分の高速化。直列化されている部分を並列動作できるように変更する、もしくは、直列化部分を小さくする。オブジェクトプールなどでは、プール数を大きくする |
| 有効なツール | スレッドダンプ、プロファイラ、負荷生成ツール |
リソースに余裕があるにもかかわらず性能が出ない場合、競合による性能劣化を疑おう。この場合、スレッドダンプ解析を行い、競合部分を特定することが解決への道となる。この問題は、正しく性能試験を行っていれば発見することができる。
また、測定データと解析ツールがあれば容易に問題部分を特定できるため、解決までの道のりは平坦だ。ただし、その道のりは長い場合が多いため、十分な人的リソースと時間的リソースが必要となる。
■【2】ロック取得不整合によるデッドロックやウェイトリーク
| 症状 | ハードウェアリソースに余裕があるにもかかわらず、レスポンスがない |
|---|---|
| 発見方法 | 性能試験。ただし再現性が低い場合があるため、シナリオを変えて複数回実施し、すべてのリクエストに対してレスポンスが存在することを確認する |
| 解析方法 | 停止スレッドおよび停止部分の特定。スレッドダンプを複数回取得し、同一スタックトレースで停止し続けているスレッドがないかを確認する |
| 対策方法 | ロック取得方法を見直す。ロック取得順序や保持中のロックが必要性を再検討する。オブジェクトが待機状態になる際には、必ず1つのロックのみ取得するようプログラムを変更する |
| 有効なツール | スレッドダンプ、負荷生成ツール、プログラム静的解析ツール |
突然レスポンスが戻らなくなる場合、デッドロックやウェイトリークの問題が発生している可能性がある。この場合も、スレッドダンプの解析が解決の道のりとなる。注意すべき点としては、複数回時間をかけてスレッドダンプを解析することだ。
プロフィール
茂呂 範(もろ すすむ)
株式会社NTTデータ 基盤システム事業本部所属。入社時よりOSSを用いたWebシステムの開発支援にかかわる。最近では、トラブルシューティングとその際のノウハウの収集・展開に日々従事している。
- 数百キロのコードでブルー - ドクターTomcat緊急救命
- DB操作の“壁”を壊すJPAが起こした「赤壁の戦い」
- アプリ開発でも、よ〜く考えよう。キャッシュは大事だよ
- スレッドダンプの森で覚えた死のロックへの違和感
- ThreadとHashMapに潜む無限回廊は実に面白い?
- JavaのGC頻度に惑わされた年末年始の苦いメモリ
- 肥え続けるTomcatと胃を痛めるトラブルハッカー
- 【トラブル大捜査線】失われたコネクションを追え!
- 【真夏の夜のミステリー】Tomcatを殺したのは誰だ?
- OutOfMemoryエラー発生!? GCがあるのに、なぜ?
- DBアクセスのトラブルは終盤で発覚しがち……
- 【実録ドキュメント】そのログ本当に必要ですか?
- “Stop the World”を防ぐコンカレントGCとは?
- Webアプリの問題点を「見える化」する7つ道具
関連記事
- Mapインターフェイスの実装クラスの違いを知る
- [Analysis]素数ゼミとハッシュテーブル
 Javaのマルチスレッドによるリソース競合から守る
Javaのマルチスレッドによるリソース競合から守る
Javaパフォーマンスチューニング(4) Javaはルチスレッドを容易に使えるというメリットを持つ。しかし、マルチスレッドはパフォーマンス低下の原因でもあるのだ- HotSpot VMの基本構造を理解する
チューニングのためのJava VM講座(前編) パフォーマンスチューニングに関わるエンジニアのためのJava VM講座。2回に渡ってHotSpot VMの基礎知識を解説します - 事例に学ぶWebシステム開発のワンポイント
現場のエンジニアの経験から得られた、アプリケーション・サーバをベースとしたWebシステム開発におけるノウハウ、注意点について解説 - 第1回 クラスタ化すると遅くなる?
- 第2回 キャッシュが性能劣化をもたらす謎を解く
- 第3回 クラスタは何台までOK?
- 第4回 マルチスレッドのいたずらに注意
- 第5回 クラスタによるアプリケーションの動的アップデート
- 第6回 APサーバからの応答がなくなった、なぜ?
- 第7回 低負荷なのにCPU使用率が100%?
- 第8回 文字化け“???”の法則とその防止策
- 第9回 メモリは足りているのに“OutOfMemory”のなぞ
- 第10回 レスポンスキャッシュでパフォーマンス向上
- 第11回 JDBC接続を高速化―PreparedCacheの活用
- 第12回 ブラウザキャッシュでパフォーマンス向上
- 第13回 ファイルアップロード/ダウンロードに潜むわな
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。