memcached亄PostgreSQL偱幚尰偡傞 僴僀僷僼僅乕儅儞僗Web傾僾儕働乕僔儑儞峔抸丗memcached偺巊偄曽乮1乯乮2/4 儁乕僕乯
memcached偺巇慻傒偲怴婡擻
丂偙偙偐傜偼memcached偺巇慻傒偦偺傕偺偲丄嵟嬤偺僶乕僕儑儞偱幚憰偝傟偨婡擻偵偮偄偰尒偰偄偒傑偟傚偆丅
memcached偺巇慻傒
丂memcached偺巇慻傒傪3偮偺晹暘偵暘偗偰愢柧偟傑偡丅
1丗捠怣娗棟偲僀儀儞僩張棟
2丗僨乕僞憖嶌乮曐懚丄専嶕丄嶍彍乯
3丗儊儌儕娗棟
1丗捠怣娗棟偲僀儀儞僩張棟
丂捠怣娗棟偲僀儀儞僩張棟偼儔僀僽儔儕libevent傪棙梡偟偰偄傑偡丅偙傟傪巊偭偰僨乕僞偺庴怣偐傜僐儅儞僪偺夝愅丄僨乕僞憖嶌丄寢壥偺憲怣傑偱僐儞僷僋僩偵幚憰偟偰偄傑偡丅
丂libevent偼戝検偺摨帪傾僋僙僗傕寉乆偙側偡崅惈擻側儔僀僽儔儕偲偟偰桳柤偱丄memcached偺儗僗億儞僗偺崅懍壔偵傕婑梌偟偰偄傑偡丅
2丗僨乕僞憖嶌
丂僨乕僞憖嶌偼曐懚丄専嶕丄嶍彍偺3庬椶偵戝暿偱偒傑偡丅
丂乮1乯曐懚偺応崌
丂僨乕僞偺曐懚傪峴偆add僐儅儞僪偑memcached偵撏偔偲丄乮僉乕偲僨乕僞偺慻偱偁傞乯item傪曐懚偡傞椞堟傪妋曐丄僉乕偺僴僢僔儏抣傪媮傔丄僴僢僔儏僥乕僽儖偵捛壛偟傑偡丅
丂娙扨側椺傪巊偭偰愢柧偟傑偟傚偆丅導挕強嵼抧傪僉乕丄搒摴晎導柤傪僨乕僞偲偡傞item傪曐懚偟傑偡丅
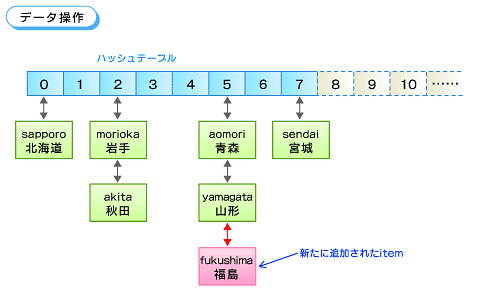 恾1丂僨乕僞憖嶌
恾1丂僨乕僞憖嶌丂偙偙偱丄僉乕乽sapporo乿偺僴僢僔儏抣偼0丄乽aomori乿偼5丄乽morioka乿偼2丄側偳偲偟傑偡丅
丂怴偨偵item乮僉乕乽fukushima乿丄僨乕僞乽暉搰乿乯傪曐懚偡傞応崌丄嵟弶偵乽fukushima乿偺僴僢僔儏抣5傪媮傔丄師偵僴僢僔儏僥乕僽儖偺5偵摉偨傞梫慺偺儕僗僩偵捛壛偟傑偡丅偙偙偱偼偡偱偵item乮乽aomori乿丄乽惵怷乿乯偲item乮乽yamagata乿丄乽嶳宍乿)偑儕僗僩偵側偭偰偄傞偺偱丄偦偺枛旜偵捛壛偟傑偡丅
丂乮2乯専嶕偺応崌
丂僨乕僞偺専嶕傪峴偆get僐儅儞僪偑撏偔偲丄僉乕偺僴僢僔儏抣傪媮傔丄僴僢僔儏僥乕僽儖傪弴偵専嶕偟偰堦抳偡傞僉乕偺僨乕僞傪曉偟傑偡丅
丂僉乕乽fukushima乿傪専嶕偡傞偵偼丄僉乕偺僴僢僔儏抣5傪媮傔丄僴僢僔儏僥乕僽儖偺5偵摉偨傞梫慺傪弴偵専嶕偟傑偡丅嵟弶偺item偺僉乕偼乽aomori乿丄偦偺師偼乽yamagata乿側偺偱僗僉僢僾偟傑偡丅偦偺師偺item偺僉乕偼乽fukushima乿偱堦抳偡傞偺偱僨乕僞乽暉搰乿傪曉偟傑偡丅
丂曐懚偟偰偄傞item偺憤悢偑僴僢僔儏僥乕僽儖挿偺1.5攞傪挻偊傞偲丄僴僢僔儏僥乕僽儖傪2攞偵奼挘偟丄item偺徴撍偑昿敪偡傞偙偲傪杊偓傑偡丅弶婜忬懺偺僴僢僔儏僥乕僽儖挿偼65536乮2偺16忔乯丄師偼131072乮2偺17忔乯丄偦偺師偼262144乮2偺18忔乯偲攞乆偵怢傃偰偄偒傑偡丅
丂偙傟偑丄朿戝側悢偺僨乕僞傪曐懚偟偰傕専嶕惈擻偑楎壔偟側偄戝偒側棟桼偱偡丅
丂乮3乯嶍彍偺応崌
丂専嶕偲摨條偵僉乕偺僴僢僔儏抣偐傜item傪専嶕偟丄媮傔偨僨乕僞傪嶍彍偟傑偡丅
3丗儊儌儕娗棟
丂愭偵item偺曐懚帪偵偼椞堟傪妋曐偡傞偲愢柧偟傑偟偨偑丄曐懚偡傞搙偵OS偐傜儊儌儕椞堟傪妋曐偡傞偺偱偼帪娫偑偐偐傝偡偓傑偡丅
丂偦偙偱memcached偼僗儔僽乮slab乯偲偄偆1Mbyte偺椞堟傪帠慜偵弨旛偟丄僗儔僽撪晹傪懡悢偺彫偝側椞堟偱暘妱偟偰偍偒傑偡丅偙偺彫椞堟傪chunk偲屇傃丄僨乕僞偺曐懚帪偼僗儔僽撪偺傑偩巊偭偰偄側偄chunk偵曐懚偟偰偄偒傑偡丅
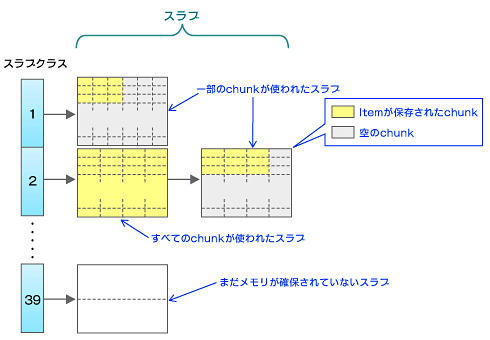 恾2丂儊儌儕娗棟
恾2丂儊儌儕娗棟丂僗儔僽偼僗儔僽僋儔僗乮slabclass乯偲偄偆攝楍偱娗棟偝傟偰偄傑偡丅弶婜忬懺偱偼slabclass[1]偐傜slabclass[39]傑偱偁傝丄昁梫偵墳偠偰僗儔僽偑儕儞僋偝傟傑偡丅僗儔僽偼1儁乕僕丄2儁乕僕偲悢偊傑偡丅
丂slabclass[1]偵懏偡傞僗儔僽偺chunk僒僀僘偼88bytes偱11,915屄偺chunk傪娷傫偱偄傑偡丅slabclass[2]偱偼chunk僒僀僘偑112bytes偱9,362屄丄slabclass[3]偱偼chunk僒僀僘偑144bytes偱7,281屄偲丄弴偵chunk僒僀僘偑戝偒偔側傝丄slabclass[39]偵懏偡傞儁乕僕偺chunk僒僀僘偼489,032bytes偱2屄偺chunk偐傜惉傝傑偡丅
丂item傪曐懚偡傞応崌丄僉乕偲僨乕僞丄偍傛傃偄偔偮偐偺晅懏忣曬偺崌寁僒僀僘偵傛偭偰丄偳偺僗儔僽僋儔僗偺僗儔僽偵曐懚偡傞偐偑寛傑傝傑偡丅
丂椺偊偽僉乕偑乽fukushima乿僨乕僞偑乽暉搰乿側傜88bytes偺chunk偵廂傑傞偺偱丄slabclass[1]偵懏偡傞僗儔僽撪偺傑偩巊傢傟偰偄側偄chunk偵曐懚偝傟傑偡丅
丂僗儔僽偵偁傞掱搙偺悢偺item偑曐懚偝傟傞偲丄怴偟偄僗儔僽偑儊儌儕忋偵妋曐偝傟偰僗儔僽僋儔僗偵捛壛偝傟傑偡丅
丂埲忋傪摜傑偊偰丄僴僢僔儏僥乕僽儖偲僗儔僽僋儔僗丄偍傛傃僗儔僽偲chunk偺娭學傪傕偆堦搙昤偒捈偡偲師偺傛偆偵側傝傑偡丅
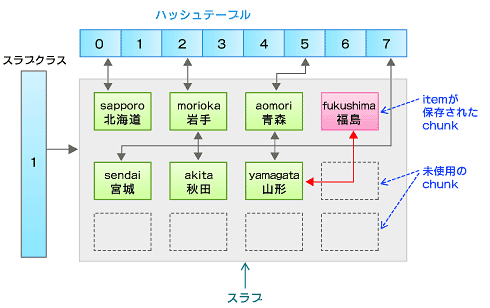 恾3丂僴僢僔儏僥乕僽儖丄僗儔僽僋儔僗丄僗儔僽丄chunk偺娭學
恾3丂僴僢僔儏僥乕僽儖丄僗儔僽僋儔僗丄僗儔僽丄chunk偺娭學怴婡擻偲儀儞僠儅乕僋寢壥
丂memcached偼2003擭5寧30擔偵僶乕僕儑儞1.0.0偑儕儕乕僗偝傟偰偐傜弴挷偵僶乕僕儑儞傾僢僾偑懕偒丄嵟怴僶乕僕儑儞偼2008擭3寧4擔儕儕乕僗偺僶乕僕儑儞1.2.5偱偡丅
丂偙傟傑偱偱堦斣戝偒側曄峏偺偁偭偨僶乕僕儑儞偼2007擭12寧6擔儕儕乕僗偺僶乕僕儑儞1.2.4偱丄曐懚偲専嶕偺僐儅儞僪偑4偮捛壛偝傟丄僒乕僶僾儘僙僗偺儅儖僠僗儗僢僪壔偵傛偭偰張棟惈擻偑戝暆偵岦忋偟傑偟偨丅
| 僐儅儞僪 | 僶乕僕儑儞1.2.3傑偱 | 僶乕僕儑儞1.2.4偐傜 |
|---|---|---|
| 曐懚 | set丄add丄replace | set丄add丄replace丄append丄prepped丄cas |
| 専嶕 | get | get丄gets |
| 嶍彍 | delete丄flush_all | delete丄flush_all |
| 摑寁忣曬 | stats | stats乮弌椡崁栚偺捛壛乯 |
| 昞3丂僶乕僕儑儞傾僢僾偵敽偄捛壛偝傟偨僐儅儞僪 | ||
丂嶐崱偼僨儏傾儖僐傾丄僋傾僢僪僐傾偺CPU傪搵嵹偟偨僴乕僪僂僃傾傕捒偟偔偁傝傑偣傫丅偙偆偟偨僴乕僪僂僃傾偱memcached傪儅儖僠僗儗僢僪偱壱摥偝偣傟偽暲峴丒暲楍張棟偑壜擻側偺偱丄1.2.4埲崀偺僶乕僕儑儞偱偼傛傝崅懍側儗僗億儞僗偑婜懸偱偒傑偡丅
丂埲壓偵丄庤尦偺僒乕僶乮Intel Core2Quad 9660 2.4GHz乯忋偱峴偭偨僶乕僕儑儞1.2.5偺儀儞僠儅乕僋寢壥傪帵偟傑偡丅
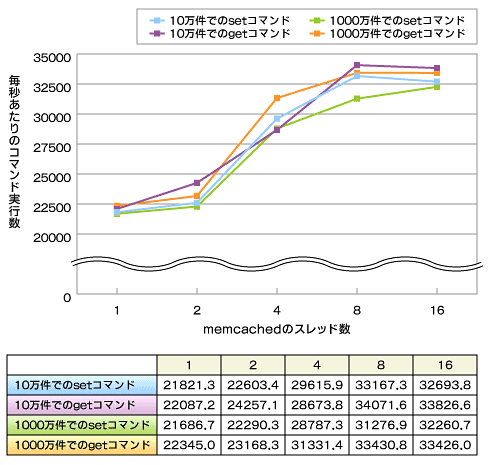 恾4丂僶乕僕儑儞1.2.5偺儀儞僠儅乕僋寢壥
恾4丂僶乕僕儑儞1.2.5偺儀儞僠儅乕僋寢壥丂廲幉偼枅昩偺僐儅儞僪幚峴悢偱偡丅memcached偵懳偟偰160偺僋儔僀傾儞僩偑摨帪暲峴偵set僐儅儞僪丄傕偟偔偼get僐儅儞僪傪憲怣偟丄1昩娫偵壗僐儅儞僪幚峴偱偒傞偐傪寁應偟偨寢壥偱偡丅墶幉偼memcached偺僗儗僢僪悢偱偡丅偦傟偧傟1丄2丄4丄8丄16偺5僷僞乕儞偱婲摦偟傑偟偨丅傑偨丄婲摦捈屻偵10枩審偍傛傃1,000枩審偺僨乕僞傪曐懚偟偰偐傜寁應偡傞偙偲偱丄曐懚偟偰偄傞僨乕僞悢偵傛傞塭嬁傕挷傋傑偟偨丅側偍丄set僐儅儞僪偱憲怣偡傞僨乕僞偼100bytes丄僉乕偼1偐傜100,000偺娫偺悢偱偡丅
丂堦尒偟偰儅儖僠僗儗僢僪壔偵傛傞惈擻岦忋偑撉傒庢傟傑偡丅儅儖僠僗儗僢僪壔偟偰偄側偄応崌乮僗儗僢僪悢亖1乯偲斾妑偟偰丄嵟戝偱50亾掱搙張棟惈擻偑岦忋偟偰偄傑偡丅傑偨丄set僐儅儞僪偲get僐儅儞僪偱傎偲傫偳張棟惈擻偵堘偄偑側偄偙偲丄曐懚偝傟偰偄傞僨乕僞悢偵傛傞塭嬁傕偁傑傝側偄偙偲偑撉傒庢傟傑偡丅
僐儔儉2丗僨乕僞曐懚偵娭偡傞Tips
仧曐懚偱偒傞僨乕僞偺嵟戝僒僀僘
丂僉乕偺嵟戝挿偑250bytes偱偁傞偙偲偼傛偔抦傜傟偰偄傑偡丅偱偼曐懚偱偒傞僨乕僞偺嵟戝僒僀僘偼偄偔傜偱偟傚偆偐丠
丂寢榑偐傜偄偊偽丄曐懚偱偒傞僨乕僞偺嵟戝僒僀僘偼僉乕偺挿偝偵埶懚偟丄僉乕偲僨乕僞偺崌寁偑1,048,521bytes傑偱曐懚偱偒傑偡丅
丂memcached偺僨乕僞曐懚偺扨埵偼chunk偱丄嵟戝偺chunk僒僀僘偼栺1Mbyte偱偡丅偮傑傝1儁乕僕偑傑傞偛偲1偮偺chunk偵側傝傑偡丅
丂chunk偵偼僉乕傗僨乕僞傗expire帪娫側偳僋儔僀傾儞僩偐傜憲傜傟偨忣曬埲奜偵丄嵟屻偵傾僋僙僗偝傟偨帪崗側偳偺忣曬偑曐懚偝傟傑偡丅偝傜偵僗儔僽帺懱偺忣曬傕曐懚偝傟傑偡丅偙傟傜偺忣曬傪嵎偟堷偔偲丄僉乕偲僨乕僞偵梌偊偆傞嵟戝僒僀僘偼1,048,521bytes偲側傝傑偡丅
仧嵟戝儊儌儕検傪挻偊偨応崌偺僨乕僞曐懚
丂 婲摦僆僾僔儑儞乽-m乿偱丄儊儌儕忋偵曐懚偱偒傞僨乕僞偺憤検傪愝掕偱偒傑偡丅僨僼僅儖僩偼64Mbytes偱偡偑丄傕偟傕曐懚偟偰偄傞僨乕僞偑64Mbytes傪挻偊偨傜偳偆側傞偱偟傚偆偐丠
丂memcached偼LRU乮Least Recently Used乯偲偄偆傾儖僑儕僘儉偱chunk傪娗棟偟偰偄傑偡丅娙扨偵偄偊偽乽屆偄弴偵徚偊偰偄偔乿偲偄偆傕偺偱丄僨乕僞偑偄偭傁偄偵側偭偨傜屆偄傕偺傪徚偟偰怴偟偄僨乕僞傪曐懚偟懕偗傑偡丅儊儌儕偑偄偭傁偄偱傕僄儔乕偼曉傜側偄偺偱拲堄偑昁梫偱偡丅
丂傛偭偰丄memcached傪挿婜娫塣梡偡傞応崌偼expire帪娫傪昁偢愝掕偟丄僑儈偲偟偰巆傜側偄傛偆偵偟側偗傟偽側傝傑偣傫丅
丂傑偨丄塱懕揑偵棙梡偟偨偄僨乕僞傪memcached忋偵抲偔応崌偼丄戝杮偺僨乕僞傪僨乕僞儀乕僗偵曐娗偟丄掕婜揑偵僨乕僞偺嵞搊榐傪峴偆側偳偺岺晇偑昁梫偱偡丅
Copyright © ITmedia, Inc. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅