文字列の中から効率良くキーワードを探し出せ:コーディングに役立つ! アルゴリズムの基本(7)(3/4 ページ)
BM法
力任せ法、KMP法のどちらのアルゴリズムも、検索ワードの先頭から比較をしていました。逆に、末尾から比較をすることで効率を上げるのがBM法です。BM法も考案した人の名前(Boyer-Moore)の頭文字です。
末尾の文字が不一致であれば、検索ワード全体としても不一致になります。そこで、次のマッチングでは検索ワードの文字数分全部ずらしてしまってもよさそうです。このように一気にジャンプできるので効率がよさそうです。
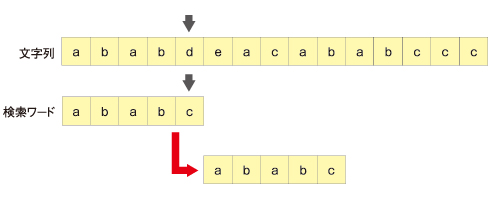
ただし、不一致になったとき、文字列側の文字が検索ワードに含まれる文字だった場合、全部ずらしてはいけません。途中でマッチする可能性があります。
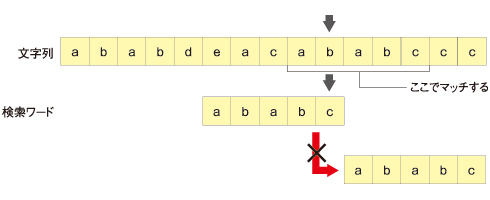
従って、不一致になったときの文字の種類ごとに、検索ワードを何文字シフトするかをあらかじめ計算しておきます。
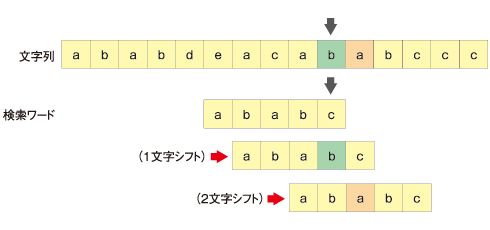
シフト文字数は次のようになります。
- 検索ワードに含まれる文字の場合(末尾の文字除く)→検索ワードの末尾から見て何番目にあるか
- 検索ワードに含まれない文字の場合→検索ワードの文字数
下図に示した例では、'a'=2、'b'=1、それ以外は5になります。シフトした後、文字列のポインタがあった場所の文字と検索ワードの文字が一致することに注目してください。
BM法の実装
先ほどのプログラムの49行目、「末尾2」というコメントがある行の下に以下のプログラムを追加してください。
<script type="text/javascript">
function BMSkip(str) {
var skip_offset = new Array();
for (var i = 0; i < str.length-1; i++) {
skip_offset[str.charCodeAt(i)] = str.length - i - 1;
}
this.skip = function(text, pos) {
var offset = skip_offset[text.charCodeAt(pos)];
return (offset != undefined) ? offset : str.length;
}
}
String.prototype.findBM = function(str) {
var bm_skip = new BMSkip(str);
var last = str.length-1;
for(var pos = last; pos < this.length; pos += bm_skip.skip(this,pos)) {
var i = pos;
var j = last;
while (j >= 0) {
if (this.charAt(i) != str.charAt(j)) { break; }
i--;
j--;
}
if(j < 0) { return i+1; }
}
return null;
}
function findTextAreaBM(text_id, search_id) {
var text = getStringById(text_id);
var search = getStringById(search_id);
alert(text.findBM(search));
}
</script>
<input type="button" onClick="findTextAreaBM('area1','search');" value="findBM">
<!-- 末尾3 -->
プログラムを解説します。
2〜13行目
文字ごとのシフト文字数を計算する関数です。BMSkipはオブジェクト的に使うようになっています。引数strには検索ワードが入ります。
3行目
シフト文字数を格納する配列を定義しています。
5〜7行目
検索ワードのそれぞれの文字について、後ろから何文字目かを計算して入れています。検索ワードの文字に重複がある場合、後から計算したもので上書きされます。つまり、後ろの方の文字が優先されます。
9〜12行目
実際の探索を行っているときにシフト文字数を取得する関数です。skip_offsetに値が設定されていればその文字数を返し、なければ検索ワードの文字数を返します。
15〜29行目
BM法の文字列探索を行う関数です。
16行目
シフト文字数を計算します。
18行目
変数posは文字列側のポインタです。
21〜25行目
文字列と検索ワードを後ろから比較していきます。
26行目
全部一致したらjが-1になるので一致した文字の位置を返します。
デバッガで様子を見る場合は、18行目のfor文にブレークポイントを置くとよいでしょう。posの値が1ずつでなく、多数増えながら検索している様子が分かると思います。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。