大相撲のアノーマリー (1):実践! Rで学ぶ統計解析の基礎(7)(2/2 ページ)
Google Refine
さて、大相撲の勝敗データさえあれば、それを解析する方法があることは分かっていただけたと思いますが、ここで問題が生じます。
大相撲のデータは、世界銀行のRESTインターフェイスのような、洗練したデータリポジトリから簡単に入手できるわけではない、ということです。そこで今回は、前述したように、Yahoo! Japanスポーツの大相撲の取り組み結果をスクレイピングして、データを入手することにします。そのために用いるのが、Google Refine です。
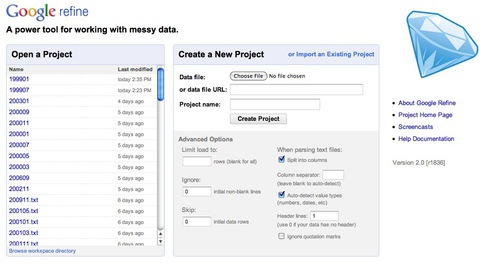
Google Refineは汚いデータをクリーニング/クレンジングするツールとしてGoogleのFreebaseチームがリリースしたオープンソース・ソフトウェアです。モットーが「Google Refine, a power tool for working with messy data」とあるように、汚い混乱したデータをキレイにするツールなのです。
Google Refineの特徴を列挙すると以下のようになります。
- Google Refineはローカルマシンで動作するWebサーバであり、クライアントにブラウザを利用する。
- Javaベースである。
- クリーニングにはスクリプトも利用するが、そのスクリプトにはPython(Jython)、Clojureに加えて、独自の言語、Google Refine Expression Language(GREL)が利用できる。
- インタラクティブに結果を見ながら、探索的にデータクリーニングができる。
- Google Refineを利用したデータクリーニングの実際は、スプレッドシートにフィルタを書けたり、Microsoft Excelで言うところのピボットテーブルを配置するイメージではあるが、もっと分かりやすくインタラクティブなインターフェイスである。
- スクリプトを書けば、リアルタイムにドライラン(試しに少数例を実行してくれる)して、その結果を例示してくれる。
- クリーニングの手順はJSONとして記録され、JSONのテキストとして入手できる。それを別のプロジェクトに適用することも可能。
- クリーニングの手順はどのステップにも戻ることができるし、Undo、Redoも自在である。
- スクリプト上にあるオブジェクトは、すべてJSON経由で外部のWeb Service APIを利用することができる。例えば住所のカラムがあるときに、それをGoogle Map APIを利用して、セルにある住所から位置情報を取得するということが容易にできる。
- クライアント・サーバ間の通信はWeb技術の標準であるHTTPであり、JSONを利用して構造データを受け渡しする。
- データのクラスタリングアルゴリズムが組み込まれていて、文字列の一致検索だけではなく、類似検索もできる。
- Google Freebaseのスピンアウトプロジェクトであるためか、Freebaseと相性がかなり良く、Freebaseからのインプット・アウトプットが容易である。
Google Refineはテータクリーニングに使うために開発されたツールですが、この柔軟で強力なツールをHTMLのWebスクレイピングには使わない手はありません。ここでは、まずはイントロとしてGoogle Refineの手習いをしましょう。
Google Refineのダウンロードは以下のURLから行います。
http://code.google.com/p/google-refine/wiki/Downloads
ぞれぞれのOSに対応したアーカイブをダウンロードし、アーカイブされたファイルを解凍して適切なフォルダに配置し、Refine.exeをダブルクリック(MacならGoogle Refine.appをダブルクリック、Linuxは“./refine”でコマンドラインから起動)すれば、Google Refineのサーバがローカルマシン上で立ち上がります。後は、http://127.0.0.1:3333/ にアクセスすれば、Google Refineにアクセスできます。
以下では起動できたと仮定して、実際にRefineを使ってYahoo!スポーツの大相撲取り組みデータを「クリーニング」する手順の概略を説明します。といっても、Refineの操作はほとんどGUIですので、ここで詳細に文章で記述をしても分かりづらいと思います。そこで、今回のRefineを使って探索的にYahoo!スポーツの大相撲取り組み表をスクレイピングする模様を動画にしましたので、それをご覧ください。
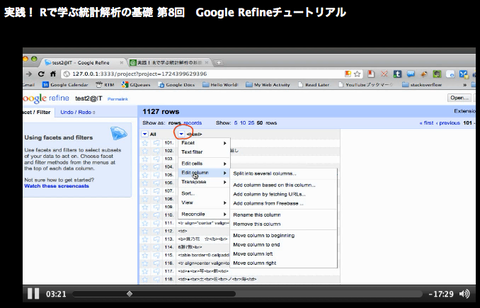
動画で使用したHTMLファイルは、こちらにあります。
このファイルをRefineに読み込み、新規プロジェクトとして登録したのちに、以下のJSONスクリプトを「Undo/Redoタブ>Apply...」ボタンで出現するテキストエリアにコピーして、実行すれば必要なデータを手に入れることができます。
https://github.com/yutakashino/atmarkIT/raw/master/sumo/codes/refineSumoJson.txt
基本的にこのJSONスクリプトがあれば、Yahoo!スポーツの取り組み表HTMLから必要なデータを抽出できます。しかし、HTMLの数は、1999年1月から2010年9月まで1年あたり7場所ありますから計71個になります。これを手でやるのはさすがに大変なので、これを自動化できないかと考えるのが自然です。
幸い、Google RefineはHTTPを受け取るWebサーバですので、HTTPを話すスクリプトを置きさえすれば、Refineを外から操作することは容易なのです。それをこの後に解説したいのですが、今回は紙幅の関係でここで一旦中断して、HTMLクリーニングの自動化は次回に持ち越しすることにします。
次回について
次回もこの「大相撲のアノーマリー」をテーマにしたいと思います。次回は、今回行ったGoogle Refineによるクリーニング作業を自動化し、外のスクリプトから操作させ、目的のデータを入手することを中心に行います。それでは、またお会いましょう。
Index
大相撲のアノーマリー (1)
Page1
今回の前口上
汚いデータをどうする?
Yahoo! Japanスポーツの大相撲の取り組み結果
7勝8敗が少なく8勝7敗多い、大相撲の不自然
Page2
Google Refine
次回について
関連記事
 いまさらアルゴリズムを学ぶ意味
いまさらアルゴリズムを学ぶ意味
コーディングに役立つ! アルゴリズムの基本(1) コンピュータに「3の倍数と3の付く数字」を判断させるにはどうしたらいいか。発想力を鍛えよう- Zope 3の魅力に迫る
Zope 3とは何ぞや?(1) Pythonで書かれたWebアプリケーションフレームワーク「Zope 3」。ほかのソフトウェアとは一体何が違っているのか? - 貧弱環境プログラミングのススメ
柴田 淳のコーディング天国 高性能なIT機器に囲まれた環境でコンピュータの動作原理に触れることは可能だろうか。貧弱なPC上にビットマップの直線をどうやって引く? - Haskellプログラミングの楽しみ方
のんびりHaskell(1) 関数型言語に分類されるHaskell。C言語などの手続き型言語とまったく異なるプログラミングの世界に踏み出してみよう  ちょっと変わったLisp入門
ちょっと変わったLisp入門
Gaucheでメタプログラミング(1) Lispの一種であるScheme。いくつかある処理系の中でも気軽にスクリプトを書けるGaucheでLispの世界を体験してみよう
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。