夏の異常気象をオープン・データで確認:実践! Rで学ぶ統計解析の基礎(6)(1/2 ページ)
今夏は異様に暑かったですよね。でも、どのぐらい暑かったと思いますか? オープン・データを利用し、Rで可視化してみましょう。
今回の前口上
今年は秋分の日を境に涼しくなり、一気に秋がきました。「暑さ寒さも彼岸まで」という言葉を今年ほど感じた年はなかったと思います。秋分の日までは、気温と湿度が高く、暑さのために生活することが本当に大変な夏でした。それがどれだけ大変だったかというのを、過去のデータと比較し、さらには地球全体ではどうだったのか、ということをオープン・データを利用してRで検証していきましょう。
ここであらかじめお断りすることがあります。筆者は気候学や気象学を専門として学んだことがないので、とんでもない過ちや勘違いをしている可能性があります。間違いを見付けられた場合は、ご指摘いただければ幸いです。
夏の異常気象:東京の気温データ
気象データといえば、やはり気象庁です。気象庁の以下の気象統計情報サイトには、過去のデータがあります。

観測地点を選び、データの属性を選択すれば、ドリルダウン形式で気象データを表示できます。以下では紙幅の都合上、東京だけを考察対象とし、1日24時間の平均気温を取った月別のデータである「観測開始からの月ごとの値」を利用することにしましょう。その条件の日平均気温データは1876年から現在までの値を表示することができます。

ただし、残念なことに、これは気象庁のサイトではHTMLとして表示されているだけで、このままでは再利用が大変です。こういうときは、表計算ソフトを使ってテーブル部分をコピー&ペーストでデータとして再利用できる形にする方法が一番早いと思います。こうした作業には、一番副作用が少ない表計算ソフトである、OpenOfficeの表計算アプリケーションを利用するとうまくいくことが多いです。それでは、表の部分だけを選択し、OpenOfficeの新しいスプレットシートにコピー&ペーストで持っていくことにします。

これをCSVファイルに保存すれば、Rで利用できる東京の月別日平均気温データを入手できたことになります。参考までに、このデータをGoogle DocsにCSVファイルとしてアップロードしておきました。
さて、何よりもまずデータの可視化が必要です。この日平均気温データを年でプロットしたものを、月別のファセットグラフにしてみましょう。ファセットグラフを描きたいので、今回もggplot2パッケージを利用します。ggplot2をインストールしていない読者の方は、install.packagesでインストールすることをお願いします。
read.csvで日平均気温CSVデータを読み込んで、データの形を見ます。
> library(ggplot2)
> data <- read.csv("http://spreadsheets.google.com/pub?key=0AlBuJgqcP5f3dDNCY0lFSEVJQXhDOWt5YkUtNTdLUHc&hl=en&output=csv", > > header=TRUE)
> head(data)
year Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec Average
1 1876 1.6 3.4 8.1 12.2 16.9 18.4 24.3 26.7 22.6 14.8 9.1 4.8 13.6
2 1877 2.9 3.3 6.0 13.5 16.4 21.9 26.2 25.7 21.1 15.6 9.3 5.7 14.0
3 1878 2.1 2.2 7.0 11.4 18.0 19.9 25.9 24.4 22.6 15.5 9.5 5.0 13.6
4 1879 3.1 5.2 7.9 12.2 17.9 21.4 26.1 26.5 21.0 14.7 9.4 7.8 14.4
5 1880 2.3 5.6 8.2 12.1 17.4 19.7 24.1 25.3 22.1 16.4 9.9 3.6 13.9
6 1881 2.0 3.4 5.1 11.3 17.0 21.2 23.8 26.5 22.4 15.5 10.8 4.1 13.6
これを見ると行が年別で、列が月別および年平均の気温データとなっていることが分かります。ggplot2では月別のファセットにする場合、月を表すデータを1つのカラムに「溶かし込んで」一緒にする必要があります。これを実行するのがmelt関数で、その引数idには溶かし込んで一緒にしないカラムを指定します。meltを利用してみたのが次のコードです。
> data1 <- melt(data, id=c("year", "Average"))
> head(data1)
year Average variable value
1 1876 13.6 Jan 1.6
2 1877 14.0 Jan 2.9
3 1878 13.6 Jan 2.1
4 1879 14.4 Jan 3.1
5 1880 13.9 Jan 2.3
6 1881 13.6 Jan 2.0
> tail(data1)
year Average variable value
1615 2005 16.2 Dec 6.4
1616 2006 16.4 Dec 9.5
1617 2007 17.0 Dec 9.0
1618 2008 16.4 Dec 9.8
1619 2009 16.7 Dec 9.0
1620 2010 NA Dec NA
これを見ると、yearカラムとAverageカラム以外は、valueカラムに集めらられ、その識別子としてvariableカラムが新たに追加されていることが分かります。これをプロットしてみましょう。
> ggplot(data=data1, aes(x = year, y = value)) + geom_path() + facet_wrap( ~variable )
●東京の日平均気温月別ファセットグラフ

これを眺めるとすぐに分かるのは、100年前と今を比べてみると3〜5度ほど温度の絶対値が上昇しているのがトレンドだということです。これが都市化によるヒートアイランド現象を示すものなのか、それとも地球温暖化を示すものなのか、あるいは100年前から現在に比べて季節が少しずつずれた結果、月で区切ったときの見かけ上の気温が上昇して見えているだけなのか、よく分かりません。気温の時系列データは非常に取り扱いが難しいので、その原因についてはこれ以上ここでは議論するのをやめますが、時系列トレンドの定量的な扱いをどうしたらよいかということについては、連載が進んで回帰と時系列データを取り上げるときにまとめて取り上げたいと思います。
参考までに東京の日最高気温と日最低気温の月別ファセットグラフも提示しておきますが、やはり上昇トレンドになっています。
●東京の日最高気温月別ファセットグラフ

●東京の日最低気温月別ファセットグラフ

さて、話を元に戻します。
今回調べたいのは今年の暑さは「例年」に比べてどの程度暑かったのか、ということです。そのために、まず「例年」というものを決めなければなりません。ここでは後半の地球全体の表面温度の話と合わせたいので、NASA Goddard Institute for Space StudiesのSurface Temperature Analysisが採用している尺度に合わせて、1951年から1980年までの30年間の算術平均気温を「例年気温」とします。そして例年気温と調べたい気温の差を「気温アノーマリー」という言葉で言い表しましょう。
ここで注意点があります。本来、気温アノーマリーとは、純粋に気候学・気象学の見地からみて特異的である値のことで、都市化の効果や観測点の環境変化そして観測機器の発達による測定感度変化などの気候・気象に関係ない効果を測定温度からすべて排除する必要があります。しかし、ここではそれらの気候・気象に関係ない効果も含めて人間が体感する温度がアノーマリーかどうかということを見たいという動機から、上記の日平均気温と例年気温の差を取るという大雑把な定義をアノーマリーに採用したいと思います。
さて、まず例年気温である1951年から1980年までの30年間の算術平均気温を求めておきましょう。これにはsubsetを利用します。夏の気温だけを見たいので、6月、7月、8月の3カ月だけを見れば十分でしょう。ここでは8月だけと、6、7、8月の3カ月を合わせた夏という、2つのパターンを見てみます。
> base <- subset(data, year>1950 & year<=1980, c(Jun, Jul, Aug))
> head(base)
Jun Jul Aug
76 21.2 24.3 26.7
77 21.3 24.3 26.8
78 20.6 24.7 25.0
79 18.3 22.3 27.0
80 22.7 27.6 26.3
81 22.3 24.2 25.4
> baseAug <- mean(base$Aug)
> baseAug
[1] 26.71667
> baseSummer <- sum(mean(base))/3
> baseSummer
[1] 24.47444
ここでは1951年から1980年までの8月の平均気温、つまり「8月の例年日平均気温」をbaseAugとし、1951年から1980年までの6月から8月を一緒にした夏の平均気温、つまり「夏の例年日平均気温」(baseSummer)としました。
まず、8月の例年日平均気温と1981年以降の8月の日平均気温との差を取ったものをプロットすると次のようになります。
> dataAug <- subset(data, year>1980, c(year, Aug)) > ggplot(data=dataAug, aes(x=year, y=Aug-baseAug)) + geom_path()
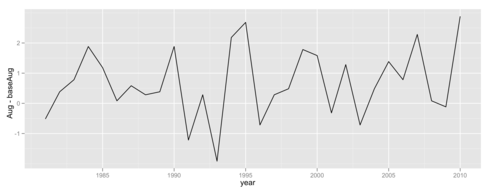
これを見るとたしかに2010年の8月は例年に比べて高くはなっています。しかし、1995年の8月と同程度のアノーマリーに過ぎないことが分かります。
次に、夏の例年日平均気温と1981年以降の夏の日平均気温との差を取ると次のようになります。データフレームの形の関係上cbindで夏の例年日平均気温を結合するという、ちょっとした細工を行いました。
> dataSummer <- subset(data, year>1980, c(year, Jun, Jul, Aug))
> dataSummer2 <- (dataSummer$Jun+dataSummer$Jul+dataSummer$Aug)/3
> dataSummer <- cbind(dataSummer, dataSummer2)
> colnames(dataSummer) <- c("year", "Jun", "Jul", "Aug", "sumAverage")
> ggplot(data=dataSummer, aes(x = year, y=sumAverage - baseSummer)) + geom_path()
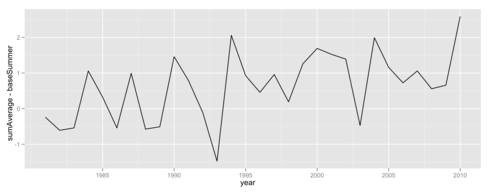
これを見ると明らかなのは、3カ月の日平均気温を考えた場合、過去30年で見ても今年はダントツで暑かった、ということです。数値で確認してみたのが以下のコードで、3カ月の日平均気温が例年より今年は2.6度も高かったのです。なるほど、暑かったはずです。
> dataSummer$sumAverage - baseSummer [1] -0.2411111 -0.6077778 -0.5411111 1.0588889 0.3255556 -0.5411111 0.9922222 -0.5744444 -0.5077778 [10] 1.4588889 0.7922222 -0.1077778 -1.4744444 2.0588889 0.9255556 0.4588889 0.9588889 0.1922222 [19] 1.2588889 1.6922222 1.5255556 1.3922222 -0.4744444 1.9922222 1.1588889 0.7255556 1.0588889 [28] 0.5588889 0.6588889 2.5922222
以上、東京だけに絞って議論をしましたが、この傾向は全国的にも同様だったそうです。この暑さの原因は3つのあるとして、気象庁は「夏の異常気象分析」で発表しています。
- エルニーニョ現象、およびラニーニャ現象の合わせ技で北半球中緯度の対流圏の気温が高くなった
- 夏の気象をもたらす太平洋高気圧の勢力がとても強かった
- 涼しい気象をもたらすオホーツク海高気圧が南下しなかった
今年の東京の気候は、まるで台北や香港、マニラにいるかのようでした。そのために例年に比べて知的生産量が減ったというグチを知人や友人から頻繁に聞きましたし、筆者も残念ながらそのような状態になってしまいました。そして、これからもこのような夏が続くなら移住を考えざるをえないな、と筆者は強く思いました。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。