インターリュード: TwitterとR:実践! Rで学ぶ統計解析の基礎(5)(1/2 ページ)
今回はTwitterという身近な題材を使って、Rによるデータ収集と可視化をやってみます。Rの豊富なライブラリを使えば意外に手軽にできます。
今回は間奏的にIT寄りの話題を
この連載は@ITの連載でもかなり毛色の違う内容です。それにもかかわらず前回までの4回は、統計的検定をいきなり導入したり、日本政府や世界銀行の経済統計にアクセスしてみたり、さらにはWikiLeaksの暴露データを統計解析してみたりと、かなりハードコアな内容に走ってしまいました。
第4回の「あとがき」では同じ路線で突っ走ろうということを申し上げていたのですが、今回は間奏(インタリュード)として、より@ITらしく、IT寄りの話題を取り上げたいと思います。
TwitterとR
Twitterの人気は世界的にまだまだ続いているようです。2010年8月後半に発表された2010年6月分の統計によれば、現在はインドネシアやブラジル、ベネズエラなどの新興国の伸びがすごいそうです。
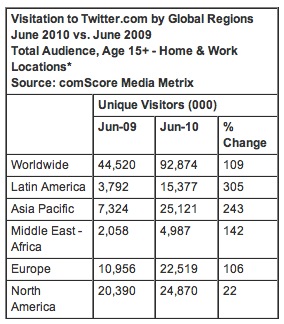
日本でもまだ17%という急成長を続けています。米国ではTwitterの成長が止まったという論考が何度も出ていますが、実はモバイルを含めた統計を見ると、こちらもまだまだ伸び代が十分なようです。
さて、その人気のTwitterですが、このようにユーザーの数や利用頻度が大きくなってくると、だんだんと日常生活に欠くことのできない社会関係資本(social capital:社会において人々が持つ人間関係や信頼関係のこと)のインフラストラクチャーのような存在になってきていると言えるでしょう。ある面では、個人の嗜好(しこう)や選好、社会の現在のトレンドなどが格納されている、人間関係及び個人の嗜好の簡易的なデータベースと考えることもできそうです。そのように考えると、Twitterのユーザー同士の関係や日々やりとりされる膨大なtweetをデータマイニングやデータ解析に利用することで有用な情報を得ることができないか、という考えが出てくることと思います。今回の記事では、ハードコアなデータマイニングやデータ解析は行いませんが、そのマイニングや解析をする入り口までのアプローチを提示することを目的とします。
Twitterをデータベースとして利用し、Rを使ってそのデータ解析をするためには、RとTwitterを連携させる必要があります。そのためのパッケージがCRANにあります。それがtwitteRです。twitteRはTwitterのREST APIをラッピングしているパッケージで、これを利用するとRをTwitterのクライアントにすることができます。
ここからは、twitteRを利用して、Twitterから引き出せる情報の可視化とテキストマイニングのイントロダクションを行いたいと思います。
まずtwitteRをインストールします。Rの対話プロンプトからinstall.packages関数を呼び出します。CRANサイトについては、例えば“Japn(Tukuba)”を選択してください。
> install.packages("twitteR")
今回はこのtwitteR以外にも、igraphとRMeCabを利用します。これもここでインストールしてしまいましょう。ただし、RMeCabについては、install.packages関数でインストールできません。これは、後ほど記述しますが、ダウンロードサイトよりバイナリファイルをダウンロードして、ローカルディスクからインストールすることになります。
> install.packages("igraph")
friendsとfollowersを可視化する
さて、このtwitteRの利用方法ですが、普通のクライアントと同じように、Twitterのアカウント(アカウント名とパスワード)が必要です。まず、twitteRをTwitterクライアントをスタートさせるためにセッションを開始する必要があります。それにはinitSession関数を利用します。
> library(twitteR)
> session <- initSession("YOURNAME", "YOURPASS")
> session
An object of class “CURLHandle”
Slot "ref":
<pointer: 0xa50000>
YOURNAMEとYOURPASSにはそれぞれ、ご自身のTwitterアカウント名とパスワードを利用してください。initSession関数から返されるのはUnixのCURLコマンドをラップした“CURLHandle”オブジェクトで、twitteRの関数を利用するときにこのオブジェクトを引数に渡してやる必要があります。
Twitterを特徴的にしているものの1つに、Twitterの参加者の間でfollowing/follwer関係という膨大な社会関係がインターネット上に構築されている、ということが挙げられると思います。その意味で、Twitterは社会関係資本(social capital)のインフラストラクチャーになり得ると、この稿の冒頭で述べました。ここではそのTwitterのfollwing/follower関係を可視化したいと思います。
twitteRでは、自分や他の人間のfollowingしている人物をターゲットとして、そのターゲットのリストを得るにはuserFriendsを利用します。第1引数には調べたいアカウントをストリングかtwitteRのuserオブジェクトを入れ、第二引数には最大値、第三引数には先ほど取得したセッションオブジェクトを入れます。ユーザのリストが返されます。ここで注意点ですが、第二引数のnを100以下にしても100個のリストが返るような仕様になっているようです。
> target <- "hatoyamayukio" > friends.obj <- userFriends(target, n = 100, session) > head(friends.obj) [[1]] [1] "barthkoch" [[2]] [1] "rimaruko" [[3]] [1] "sean_fuji" [[4]] [1] "gu_cci" [[5]] [1] "usavich3" [[6]] [1] "amanecs"
実際に読者の皆さんの画面に表示された結果は、上のものとは異なるかも知れません。それは、Twitterにおける関係は時々刻々変化しているためです。同様にfollowersを取得するには、userFollowersを利用します。さて、ここでターゲットのfollowingとfollowerのリストを取得し、そのデータをグラフ表現で視覚化したいと思います。そのために、follwingとfollwersのアカウント名を1つのデータフレームに格納します。userFriendsやuserFollowersから返されるリストオブジェクトの中身を見てみると以下のようになっています。
> str(friends.obj) List of 100 $ :Formal class 'user' [package "twitteR"] with 14 slots .. ..@ description : chr "" .. ..@ statusesCount : num 17 .. ..@ followersCount: num 20 .. ..@ favoritesCount: num(0) .. ..@ friendsCount : num 80 .. ..@ url : chr(0) .. ..@ name : chr "barthkoch" .. ..@ created : chr "Thu Aug 20 21:03:33 +0000 2009" .. ..@ protected : logi FALSE .. ..@ verified : logi FALSE .. ..@ screenName : chr "barthkoch" .. ..@ location : chr "Brazil" .. ..@ id : num 67424072 .. ..@ lastStatus :Formal class 'status' [package "twitteR"] with 10 slots ...
どうやら、screenNameがユーザのアカウント名のようです。ここで@で始まるものがリストに格納されている属性オブジェクトで、属性オブジェクトは「キー」と「値」のペアになっています。属性オブジェクトから属性値を取り出すには、そのキーを関数として適用します。試しにリストから1つ目の属性オブジェクトだけを取り出して、そのキーscreenNameを関数として適用してみましょう。
> screenName(friends.obj[[1]]) [1] "barthkoch"
これで、userFriendsやuserFollowersから返されるリストオブジェクトに格納されているアカウント名を取り出す方法が分かりました。これを全てのリストに適用し、wつのデータフレームに統合するには次のようにします。followersのリストもついでに取得しておきました。
> followers.obj <- userFollowers(target, n = 100, session)
> friends <- sapply(friends.obj, screenName)
> followers <- sapply(followers.obj, screenName)
> relationsdf <- merge(data.frame(User = target, Follower = friends),
+ data.frame(User = followers, Follower = target),
+ all = T)
> head(relationsdf)
User Follower
1 hatoyamayukio 178REIJI
2 hatoyamayukio 3hit
3 hatoyamayukio 921_u3u3
4 hatoyamayukio a_ikenag
5 hatoyamayukio ace_champ
6 hatoyamayukio achora
> tail(relationsdf)
User Follower
195 YoshidaFumitaka hatoyamayukio
196 yoshitada9646 hatoyamayukio
197 ysugihara1221 hatoyamayukio
198 yuki70424b hatoyamayukio
199 yunikonnyaku hatoyamayukio
200 yutakakanagawa hatoyamayukio
ここで、followingリストオブジェクトとfollowersリストオブジェクトにscreenNameを一括適用するためにsapplyを利用しました。また、データフレームを作成するにはdata.frame、作成した2つのデータフレームを統合するにはmeargeを利用しました。
headとtailで最初の方と最後の方のUser-Follower関係をみますと、正常にデータフレームができているようです。
次はこのUser-Follwer関係の視覚化です。これはUser -> Follower関係になっているので、グラフ理論の概念でいうところの有向グラフです。Rで有向グラフを視覚化するにはigraphパッケージを利用するのが一番手っ取り早いです。
igraphパッケージを利用するしてグラフを描画するには、通常のデータフレームを頂点と辺の属性を付け加えたデータフレームに変換する必要があります。これを行うのがgraph.data.frameです。
> library(igraph)
> g <- graph.data.frame(relationsdf, directed = T)
> g
Vertices: 201
Edges: 200
Directed: TRUE
Edges:
[0] 'hatoyamayukio' -> '178REIJI'
[1] 'hatoyamayukio' -> '3hit'
[2] 'hatoyamayukio' -> '921_u3u3'
[3] 'hatoyamayukio' -> 'a_ikenag'
...
今回はgraph.data.frameにdirected = Tという方向付けオプションを指定したので、User -> Follower関係が表現できました。このgがigraphで利用するデータフレームですが、頂点オブジェクトと辺オブジェクトを取り出すには、VとEを利用します。Vは"V"ertec(頂点)、Eは"E"dge(辺)を意味します。頂点のオブジェクトの名前を取り出すには$nameにより取り出します。
> head(V(g))
Vertex sequence:
[1] "20100912pm3" "24KinKiKids51" "313so" "9_nanatuki" "Airi0419" "ak3161"
> head(E(g))
Edge sequence:
[1] hatoyamayukio -> 3hit
[2] hatoyamayukio -> 921_u3u3
[3] hatoyamayukio -> a_ikenag
[4] hatoyamayukio -> ace_champ
[5] hatoyamayukio -> achora
[6] hatoyamayukio -> ahoneko_tom
> head(V(g)$name)
[1] "hatoyamayukio" "20100912pm3" "24KinKiKids51" "313so" "9_nanatuki" "Airi0419"
> V(g)$label
NULL
> V(g)$label <- V(g)$name
最後のコードは、グラフを書いたときに記述される頂点のラベル$labelに$name属性にあるアカウント名をそのまま入れました。これでグラフを描く準備をが整いました。グラフを描くのは実はすごく容易で、一番簡単なグラフはplot関数をグラフデータフレームに適用するだけです。

しかし、100以上の頂点オブジェクトがある場合、オブジェクトが重なってしまいこれではよく分かりません。そこで比較的高機能のグラフ描画関数であるtkplotを利用してみます。これはtkグラフィックライブラリ上に作成されたグラフプロットライブラリです。
> tkplot(g)
tkplot関数では、、“Layout”メニューからグラフの配置を変更することができます。例えば、Kawada-Kawaiアルゴリズムを選んでプロットすると以下のようなグラフになります。

このtkplotで描かれたグラフ上のオブジェクトはマニュアルで配置が変更できます。また辺を選べばその辺がハイライトしますし、頂点を選べば頂点がハイライトし、頂点間の関係がある程度分かるようになっています。
以上が、Twitterの社会関係を視覚化するために、twitteRから取得したfollwing/followerのリストをグラフ化しする一連の手順です。
Index
インターリュード: TwitterとR
Page1
今回は間奏的にIT寄りの話題を
TwitterとR
friendsとfollowersを可視化する
Page2
Twitterテキストマイニングの入門の入門
次回について
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。