開発者が知っておくべき、ドキュメント・データベースの基礎:特集:MongoDBで理解する「ドキュメント・データベース」の世界(前編)(3/3 ページ)
柔軟で容易なスケールアウト(Sharding)
MongoDB、RavenDBなどのドキュメント・データベースは、データ量の増加に伴う分散化やスケールアウト(scale-out)に配慮されており、シャーディング(Sharding)(=1つのデータベースを分割し、複数に分散させて管理・運用すること)やレプリケーション(Replication)(=データベースのレプリカを作成すること)が容易に実現可能という点も特長の1つだ。今回は、シャーディングを例に、簡単に見て行こう。
●MongoDBのシャーディング(Sharding)
MongoDBにおけるシャーディングは、RavenDBのそれと比べて自動化されている要素が多く、そのトレードオフとして構成が若干、難しくなっている。
MongoDBのシャーディングでは、最低限、シャーディングによってデータ分割を行う複数台のシャード(Shard)サーバ(厳密には、複数個のmongodプロセス)と、構成やデータベースの情報などのシャード(Shard)サーバ間をまたがる共通情報を管理する構成(Config)サーバ(=構成管理用のmongodプロセス)、そしてクライアントからの接続ポイントとなるMongosサーバ(=mongosプロセス)が必要となる。
しかし、今回は、セットアップ方法を理解してもらうことが目的ではないので、下の図のとおり、あらかじめ、ポート「28001」「28002」「28003」の3つのシャード・サーバ(Shard server)と、ポート「28021」のMongosサーバ(Mongos server)が構成されていると仮定して以降の説明を行う(シャーディングのセットアップ方法の詳細は、「mongoDB.org - Shardingの設定」を参照してほしい)。
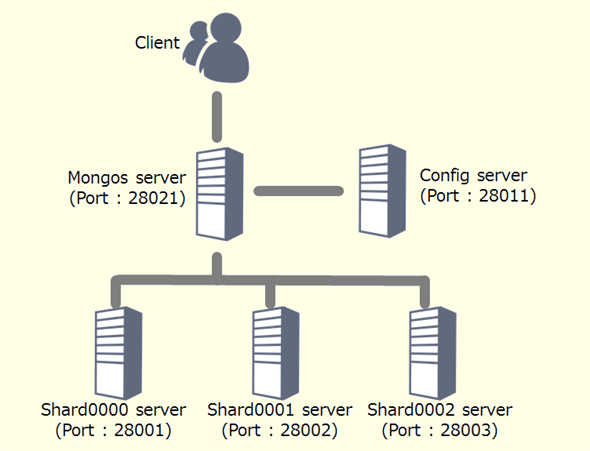 MongoDBにおけるシャーディング環境の一例
MongoDBにおけるシャーディング環境の一例まず、ここまでの例で使用しているtestdbデータベースのOrdersコレクションに対してシャーディングの設定を行ってみよう。これには、Mongosサーバ(ポート:28021)にログインして、下記のとおりのコマンドを入力する。ここでは、Nameフィールドの値を基にシャーディングの設定を行っている(下記のコマンド入力により、Nameフィールドには、自動的にインデックスが設定される)。
mongo localhost:28021/admin
> db.runCommand({enablesharding :"testdb"});
> db.runCommand({shardcollection:"testdb.Orders", key:{Name:1}});
Ordersコレクションに対してシャーディングの設定を行うコマンドライン入力例
このシャーディングの設定を行った直後に、シャーディングの状態を確認すると、下記のように出力される。ここでは、下記のコードにおける太字部分が重要だ。
この出力結果では、Nameフィールドの全ての値(=最小値から最大値までの全ての値)について、ポート「28001」のシャード・サーバ(shard0000)へ振り分けを行う設定となっているのだ。すなわち、既定の状態では、シャーディングによる振り分けは行われない。
> db.printShardingStatus();
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shard0000", "host" : "localhost:28001" }
{ "_id" : "shard0001", "host" : "localhost:28002" }
{ "_id" : "shard0002", "host" : "localhost:28003" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "testdb", "partitioned" : true, "primary" : "shard0000" }
testdb.Orders chunks:
shard0000 1
{ "Name" : { $minKey : 1 } } -->> { "Name" : { $maxKey : 1 } } on : shard0000 Timestamp(1000, 0)
シャーディングの状態を確認(既定ではシャーディングによる振り分けは行われない)
実際、数件のデータを登録して確認すると、データは全てポート「28001」のシャード・サーバに振り分けられているのが分かる(下記の出力結果を参照)。
mongo --port 28021
> use testdb;
> db.Orders.save({ Name:"bread", Price:100, Category:"food"});
> db.Orders.save({ Name:"drill", Price:2000, Category:"material"});
mongo --port 28001
> use testdb;
> db.Orders.count();
2
mongo --port 28002
> use testdb;
> db.Orders.count();
0
mongo --port 28003
> use testdb;
> db.Orders.count();
0
数件のデータを登録して各シャード・サーバのデータ件数を確認(既定ではシャーディングによる振り分けは行われないことを確認)
しかし、ここに10万件分のデータを投入した場合には、下記のとおりとなる。
mongo --port 28001
> use testdb;
> db.Orders.count();
34953
mongo --port 28002
> use testdb;
> db.Orders.count();
32352
mongo --port 28003
> use testdb;
> db.Orders.count();
32695
10万件件のデータを登録して各シャード・サーバのデータ件数を確認(既定でもシャーディングによる振り分けが行われることを確認)
MongoDBのシャーディングでは、データは「Chunk」と呼ばれる一定のサイズのブロック(今回の場合は、1 Mbytesとした)に分割され、偏りが生じると、自動的にシャード(Shard)サーバの振り分けが行われるようになる。
なお上記は、あくまでも例であり、Chunkの値やデータによってばらつきは異なってくるので注意してほしい(特に、Nameフィールドの値が「bread1」「bread2」……などと偏りがある場合、上記のようにきれいに分散されないので注意してほしい)。
●シャーディング状態の確認
また、printShardingStatusメソッドでシャーディングの状態を確認すると、下記のコマンド例のとおり、シャード(Shard)サーバの設定が行われているのが分かる(下記も同様にサンプルで、必ずしも同様にならないこともあるので注意してほしい)。
> db.printShardingStatus();
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shard0000", "host" : "localhost:28001" }
{ "_id" : "shard0001", "host" : "localhost:28002" }
{ "_id" : "shard0002", "host" : "localhost:28003" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "testdb", "partitioned" : true, "primary" : "shard0000" }
testdb.Orders chunks:
shard0001 4
shard0002 3
shard0000 4
{ "Name" : { $minKey : 1 } } -->> { "Name" : "coffee" } on : shard0000 Timestamp(2000, 0)
{ "Name" : "coffee" } -->> { "Name" : "fuel" } on : shard0001 Timestamp(3000, 6)
{ "Name" : "fuel" } -->> { "Name" : "ice cream" } on : shard0002 Timestamp(3000, 10)
……省略……
{ "Name" : "zoo ticket" } -->> { "Name" : { $maxKey : 1 } } on : shard0000 Timestamp(1000, 4)
printShardingStatusメソッドでシャーディングの状態を確認
●シャーディングしているデータベースの検索
また、この状態でNameフィールドを使って検索を行うと、下記の例のように、シャード(Shard)サーバの設定を使用して、単一のサーバのみにアクセスを行う。また、シャード(Shard)サーバをまたがった検索(例えばOR検索など)も、並列に実行される。すなわち、シャーディングを強く意識して、検索の最適化が行われる。
> db.Orders.find({Name:"bread"}).explain();
{
"clusteredType" : "ParallelSort",
"shards" : {
"localhost:28001" : [
{
"cursor" : "BtreeCursor Name_1",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 1,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 1,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"Name" : [
[
"bread",
"bread"
]
]
},
"server" : "machine01:28001"
}
]
},
"cursor" : "BtreeCursor Name_1",
"n" : 1,
"nChunkSkips" : 0,
"nYields" : 0,
"nscanned" : 1,
"nscannedAllPlans" : 1,
"nscannedObjects" : 1,
"nscannedObjectsAllPlans" : 1,
"millisShardTotal" : 0,
"millisShardAvg" : 0,
"numQueries" : 1,
"numShards" : 1,
"indexBounds" : {
"Name" : [
[
"bread",
"bread"
]
]
},
"millis" : 0
}
シャーディングしているデータベースを検索
次回の後編で説明するが、RavenDBにもシャーディングの概念は存在するが、こうした動的なスケールアウト(具体的には自動シャーディング(auto sharding))はMongoDBにおける大きな特長の1つだ。特に大量データを扱う場合、設計の最初の段階から、データのばらつきに関する正確な予測を行うことは難しいが、MongoDBではこうした課題に対する現実的な手段を提供しているので魅力的だ。
●MongoDBのレプリケーションについて
なお、ここでは説明を省略するが、ドキュメント・データベースでは、こうしたスケールアウトの手段以外に、フェイルオーバーのためのレプリケーション(Replication)の仕組みも共通に持ち合わせている(もちろん、シャーディングとの併用も可能だ)。
以上、MongoDBを例に、「ドキュメント・データベースとは何か」が分かるよう、代表的な機能に絞って解説した。冒頭で説明した「パフォーマンス、大量データ、スケーラブルといった課題を克服するためのシンプルなセットを提供している」というドキュメント・データベースの最大の特長は理解していただけただろうか。
次回の後編では、データベースごとの設計思想を説明する。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。