OpenStack、インストール後につまずかない、考え方・使い方のコツ(その1)――OpenStackはどのように構成されているか:特集:OpenStack超入門(9)(2/3 ページ)
スモールスタート用OpenStackの構成例
OpenStackの基本的なプロセスの構成が分かったところで、実際にどうプロセスを配置していくかを紹介します。今回は「6台のサーバーからスタートして、ハイパーバイザーが100台程度までスケールする」ことを想定した「スモールスタート用の構成」を例にとります。仮想マシン、仮想ストレージと仮想ネットワークのバックエンドには、それぞれKVM、Ceph、VxLANを利用します。
これを実現するためのプロセス構成図が図3です。スモールスタートすることと、最大100ハイパーバイザー程度までのスケールを意識しているため、サーバーをコントローラーノードとコンピュートノードの2種類に分類して管理しています。
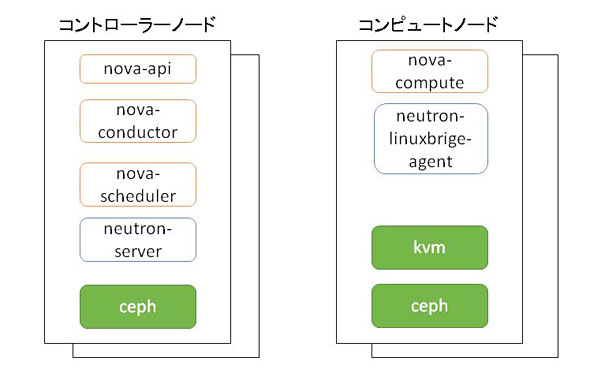 図3 スモールスタート用構成のプロセス構成概略
図3 スモールスタート用構成のプロセス構成概略ここで、前述したNovaの基本的な3つのプロセスをもう一度思い出してみましょう。
- ユーザーからのAPIリクエストを受け付けるプロセス: nova-api
- APIに合わせた非同期処理のタスクを管理するプロセス: nova-conductor, nova-scheduler
- 仮想化機構に対して実際の操作を行うプロセス: nova-compute
仮想化機構に対して実際に操作を行う「3」のプロセスは、操作する対象に対して1対1で配置する必要があります。そのため、nova-computeを各コンピュートノードに独立して配置しています。neutron-linux-bridge-agentもVMが接続するlinux bridgeを操作するため、同様に各コンピュートノードに配置しています。
対して、1、2のプロセスは、OpenStackのシステム内に最低1プロセス存在していれば問題ありません。そのため、プロジェクトの種類に関係なく、これらのプロセスは全てコントローラーノードで動作させています。この例のように、プロセスの役割を意識してサーバー上に配置することで、シンプルで管理しやすい構成にすることができます。
バックエンドに依存するプロセス構成
ただ、OpenStackで管理する仮想リソースとしては、仮想マシンと仮想ネットワークだけではなく、仮想ブロックストレージ(Cinder)や仮想マシンのイメージ(Glance)などもあります。これらのプロセスも、前述したNovaの3つのプロセスと同様に、役割に合わせてプロセスが分かれています。そのため、図3で示したnova-computeと同じく、「3」のプロセスについては、管理対象の仮想化機構に対して1対1で配置する必要があります。
しかしながら、前述のスモールスタート用の構成では、仮想ブロックストレージや仮想マシンのイメージを管理するCinderやGlanceのプロセスは、全てコントローラーノードの上で動作させています。スモールスタート用の構成では「仮想化機構を管理するプロセスは、仮想化機構に対して1対1で配置する必要があるためコンピュートノードで管理する」と述べたのに、なぜCinderなどのプロセスはコントローラーノードに配置しているのでしょうか?
理由は大きく2つあります。一つは仮想化機構にCephを利用しているため、コントローラーノードにこれらのプロセスをまとめることができるからです。つまり、Ceph自体が分散ストレージのソフトウエアであることから、CinderやGlanceによって管理する対象は、Cephという1つのサービスを操作すればよいため、1プロセスのみ存在すれば問題ないというわけです。よって コントローラーノードに配置しています。
参考リンク:分散ストレージCeph/RADOSとは?(@IT)
では、もしCephではなく「NFS(Network File System)」など別のバックエンドを利用した場合には、CinderやGlanceのプロセスをコンピュートノードに配置する必要があるのでしょうか? 答えはノーです。コントローラーノードにこれらのプロセスを集約している二つ目の理由は、スモールスタートを目的としており、100ハイパーバイザー程度までのスケールしか想定していないためです。
仮想ブロックストレージは、仮想マシンにボリュームとして接続してデータを書き込むことで、仮想マシン内の情報を永続化することに利用します。一方、Novaで作成した仮想マシンのOS起動領域などは、通常、仮想マシンが持つ揮発性のディスク領域に書き込まれるため、仮想マシンの削除とともになくなってしまいます。よって、仮想マシンを再作成した後も同じデータを利用したい場合などは、仮想ブロックストレージを利用することが多いかと思います。つまり、仮想マシンに比べてスケールする必要性が低いことから、1つにまとめてしまっているのです。
つまり、例として紹介している構成では、ストレージバックエンドにCephを採用したため、Ceph自体の利点によって、CinderやGlanceのプロセス配置をまとめてしまうことができたわけです。もちろん、NFSなど別のバックエンドを利用すると絶対にまとめられないというわけではありませんが、ポイントはバックエンドの実現方法によって制約の有無が変わってくるということです。
例えば、ストレージアプライアンスによっては、アプライアンスの機能で NFS領域を後から拡張できるものもあります。このようなアプライアンスを利用していれば、Cephと同じように問題は発生しません。対して、NFS領域を後から拡張できないものであれば、コントローラーノードにまとめられなくなる可能性があります。
関連記事
- OpenStackが今求められる理由とは何か? エンジニアにとってなぜ重要なのか?
スピーディなビジネス展開が収益向上の鍵となっている今、システム整備にも一層のスピードと柔軟性が求められている。こうした中、なぜOpenStackが企業の注目を集めているのか? 今あらためてOpenStackのエキスパートに聞く。 - OpenStackのコアデベロッパーは何をしているのか
@IT特集「OpenStack超入門」は日本OpenStackユーザ会とのコラボレーション特集。特集記事と同時に、日本OpenStackユーザ会メンバーが持ち回りでコミュニティの取り組みや、超ホットでディープな最新情報を紹介していく。第2回は日本OpenStackユーザ会メンバーで、OpenStack開発コミュニティ コアデベロッパーの元木顕弘氏が語る。 - ますます進化・拡大するOpenStackとOpenStackユーザーたち
@IT特集「OpenStack超入門」は日本OpenStackユーザ会とのコラボレーション特集。特集記事と同時に、ユーザ会メンバーが持ち回りでコミュニティの取り組みや、まだどのメディアも取り上げていない超ホットでディープな最新情報をコラムスタイルで紹介していく。第1回は日本OpenStackユーザ会会長 中島倫明氏が語る。 - 開発環境構築の基礎からレゴ城造り、パートナー交渉術まで〜OpenStack Upstream Trainingの内容とは?
OpenStack Summit Parisでは、数々の先進的な企業事例が登場した一方で、開発コミュニティ参加希望者に向けたオープンなトレーニングプログラムも企画されていた。OSSコミュニティのエコシステムの考え方まで考慮した2日間にわたるプログラムを、参加エンジニアがリポートします。 - OpenStack、結局企業で使えるものになった?
OpenStackを採用することで、企業のITインフラはどう変わるのか、導入のシナリオや注意点は何か。そんな問題意識の下で開催した@IT主催セミナー「OpenStack超解説 〜OpenStackは企業で使えるか〜」ではOpenStackの企業利用の最前線を紹介した。 - OpenStackとレゴタウンとの意外な関係
10月10、11日に東京で実施されたOpenStack Upstream Trainingでは、レゴを使った街づくりのシミュレーションが。レゴはOpenStackプロジェクトとどう関係するのか。 - いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
クラウドの可能性や適用領域を評価する時代は過ぎ去り、クラウド利用を前提に考える「クラウドファースト」時代に突入している。本連載ではクラウドを使ったSIに豊富な知見を持つ、TISのITアーキテクト 松井暢之氏が、クラウド時代のシステムインテグレーションの在り方を基礎から分かりやすく解説する。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。