Hadoop仺Redshift仺偦偺愭偼丠乗乗IoT乛僴僀僽儕僢僪帪戙偺嵟怴僩儗儞僪傪惍棟偡傞丗乬巇帠偱杮摉偵巊偊傞乭僋儔僂僪僨乕僞儀乕僗偺梫審 乮1/2 儁乕僕乯
恖娫傗婡夿偺妶摦傪僨乕僞偲偟偰庢傝崬傓IoT偺弌尰偱丄僋儔僂僪忋偺乽僨乕僞儀乕僗僒乕價僗乿傪僄儞僞乕僾儔僀僘偱傕棙梡偡傞応柺偑憹偊偰偒偨丅僨乕僞儀乕僗偲僋儔僂僪偺娭學丄僨乕僞妶梡偺儕傾儖傪丄IT僕儍乕僫儕僗僩 扟愳峩堦巵偺帇揰偱傂傕夝偔丅
乽僋儔僂僪僨乕僞儀乕僗乿乽價僢僌僨乕僞乿偼巊偊側偄僶僘儚乕僪偩偭偨偺偐
丂僔僗僥儉奐敪丒塣梡偺暿傪栤傢偢丄乽僋儔僂僪僼傽乕僗僩乿偲偄偆尵梩偑掕拝偟偮偮偁傞丅
丂偲偼偄偆傕偺偺丄傑偩僋儔僂僪壔偑愊嬌揑偵峴傢傟偰偄側偄偺偑僨乕僞儀乕僗偺椞堟偩傠偆丅僨乕僞儀乕僗偵媮傔傜傟傞偺偼僷僼僅乕儅儞僗傗僨乕僞偺尩枾側娗棟丄怣棅惈偺妋曐偱偁傞丅堦曽丄懡偔偺応崌偱僋儔僂僪偵媮傔傜傟傞偺偼丄壖憐壔傗摑崌丒廤栺丄僔僗僥儉偍傛傃僾儘僙僗偺昗弨壔傗儕僜乕僗嵟揔壔側偳偩丅偦傟屘丄僨乕僞儀乕僗偲僋儔僂僪娐嫬偲偱偼丄偄傑傂偲偮愜傝崌偄偑晅偐側偄偙偲傕彮側偔側偐偭偨丅
丂偟偐偟側偑傜偙偙嵟嬤偼丄悢懡偔偺僋儔僂僪忋偺僨乕僞儀乕僗僒乕價僗偑弌偰偒偰偄傞丅偳偆偄偭偨梫媮偑偁傞偲偒偵乽偳傫側僒乕價僗傪慖戰偡傟偽偄偄偺偐乿乽僋儔僂僪偲僆儞僾儗儈僗傪偳偆巊偄暘偗偨傜偄偄偺偐乿偼偐側傝柪偆偲偙傠偩丅
巊偊偦偆偱巊偊側偐偭偨Hadoop偲乽價僢僌僨乕僞乿
丂偲偙傠偱丄乽價僢僌僨乕僞乿偲偄偆尵梩偑擔杮偱巊傢傟巒傔偨偺偼2010乣11擭偛傠偩傠偆偐丅婛偵僋儔僂僪偼偁偭偨偑丄價僢僌僨乕僞張棟傪僋儔僂僪偱峴偆偙偲偼尰幚揑偱偼側偐偭偨丅側偤側傜丄摉帪丄價僢僌僨乕僞僜儕儏乕僔儑儞偺敪憐偼丄偐偮偰偺僨乕僞僂僄傾僴僂僗偺墑挿慄忋偵偁傞傕偺偩偭偨偐傜偩丅
丂偲偵偐偔僨乕僞検偑寘堘偄偵憹偊傞丅偦偟偰丄偦偺憹偊傞僨乕僞偵偼偝傑偞傑側旕峔憿壔僨乕僞傕擖偭偰偔傞丅寢壥丄戝梕検僗僩儗乕僕傗崅惈擻僒乕僶乕丄崅懍張棟偑偱偒傞僨乕僞儀乕僗偑昁梫偵側傞丅偙傟傜價僢僌僨乕僞張棟偵昁梫側峔惉傪僋儔僂僪娐嫬偱幚尰偡傞偺偼丄摉帪偼傑偩彮偟擄偟偐偭偨偺偩丅
丂偲偼偄偊丄價僢僌僨乕僞偼僗僩儗乕僕儀儞僟乕傗僨乕僞儀乕僗儀儞僟乕偑婌乆偲偟偰扴偓忋偘丄弖偔娫偵IT嬈奅偺僽乕儉偲側傞丅偙偺偲偒怴偨偵拲栚偝傟偨偺偑乽Hadoop乿偩丅旕峔憿壔僨乕僞傪戝検偵庢傝崬傒偨偄丅偦傟偼廬棃偺儕儗乕僔儑僫儖僨乕僞儀乕僗偱偼擄偟偔丄Hadoop偲Map Reduce偺傛偆側暘嶶僼傽僀儖僔僗僥儉偲NoSQL宆偺暘嶶張棟僄儞僕儞偑昁梫偲偄偆榖偵側偭偨丅
丂幚嵺偺偲偙傠丄偙偺棳傟偱價僢僌僨乕僞僽乕儉偼姫偒婲偙偭偨偑丄尰幚壔偟偨僔僗僥儉偼偦傟傎偳懡偔偼側偐偭偨偩傠偆*丅憹偊懕偗傞僨乕僞偵崌傢偣偰丄婇嬈偼偦偆娙扨偵僗僩儗乕僕傗僒乕僶乕傪憹傗偣傞傢偗偱傕側偔丄僗僩儗乕僕傗僒乕僶乕傪憹傗偣傞傢偗偱傕側偔丄壖偵戝検偵僨乕僞傪棴傔傞偙偲偑偱偒偰傕丄僨乕僞検偑懡偗傟偽懡偄傎偳庢傝弌偟偰暘愅偡傞偺偵偼庤娫傕僐僗僩傕妡偐傞偙偲偑暘偐偭偰偔傞偺偩丅
丂傑偨Hadoop偼100僲乕僪丄1000僲乕僪偲暘嶶壔偟偨峔惉傪斾妑揑埨壙偵峔抸偱偒偨偑丄幚嵺偵偦偺傛偆側懡僲乕僪峔惉偺僔僗僥儉傪塣梡偱偒傞懱椡丄媄弍儕僜乕僗傪帩偭偨婇嬈偼偦傟傎偳懡偔偼側偐偭偨丅堦晹愭抂媄弍偑岲偒偱僄儞僕僯傾偑帺傜庤傪壓偣傞傛偆側婇嬈傪彍偒丄Hadoop偺棙梡偼悢僲乕僪偐傜悢廫僲乕僪峔惉偱暘愅慜偺僨乕僞僋儗儞僕儞僌梡側偳偺僶僢僠張棟掱搙偵偲偳傑偭偰偄傞偙偲傕懡偄丅
* Hadoop偺棙梡偼丄Java傗HDFS丄暘嶶傾儖僑儕僘儉側偳傊偺棟夝偑昁梫偱偁偭偨偨傔丄堦晹偺愭恑揑側IT僄儞僕僯傾傪帩偮慻怐埲奜偱偺晛媦偼尷掕揑偱偁偭偨丅偙偺栤戣偵偮偄偰偼乽Hadoop偼乽擄偟偄丒抶偄丒巊偊側偄乿丠 墇偊傜傟側偄暻偑偁傞棟桼偲懪奐嶔傪惍棟偡傞乿乮仐IT乯偱傕尵媦偟偰偄傞丅
Redshift傪婡偵嬤偯偄偨僄儞僞乕僾儔僀僘IT偲僨乕僞儀乕僗僋儔僂僪
丂偙偺傛偆偵丄僋儔僂僪偲僨乕僞儀乕僗偲偺娫偵偼戝偒側妘偨傝偑偁傞忬嫷偑懕偄偰偄偨偺偩偑丄偙偺忬嫷傪曄壔偝偣傞偒偭偐偗偲側傞弌棃帠偑婲偒偨丅2012擭枛偵Amazon Web Services乮AWS乯偑敪昞偟偨乽Amazon Redshift乮Redshift乯乿偩丅Redshift偼丄戝検僨乕僞傪搳擖偟偰傕崅僷僼僅乕儅儞僗傪敪婗偡傞僆乕僾儞僜乕僗偺RDBMS偱偁傞乽PostgreSQL乿偲屳姺惈偑偁傞僨乕僞儀乕僗僒乕價僗偩丅僋儔僂僪忋偺RDBMS偱偁傟偽僗働乕儖傾僂僩偑梕堈偱偁傞偙偲偐傜丄Hadoop偱柍棟偵暘嶶偝偣側偔偰傕AWS偑僋儔僂僪偱奼挘惈偼妋曐偟偰偔傟傞丅乽庢傝偁偊偢價僢僌僨乕僞傪帋偟偨偄乿偲偄偆儐乕僓乕偵偼嵟揔側娐嫬偑惗傑傟偨偺偩丅
丂Redshift搊応埲慜偼丄僋儔僂僪忋偺僨乕僞儀乕僗僒乕價僗偺懡偔偑丄僥僗僩傗奐敪梡搑丄偁傞偄偼彫婯柾側Web僒乕價僗偺儕億僕僩儕揑側棙梡偩偭偨偺偵懳偟丄Redshift側傜婇嬈偺僨乕僞僂僄傾僴僂僗傪僋儔僂僪偵抲偒懼偊傞偙偲偑偱偒丄偝傜偵僷僽儕僢僋僋儔僂僪偺儊儕僢僩偱丄偦傟傪偐側傝埨壙偵幚尰偱偒傞丅偙傟偼僄億僢僋儊僀僉儞僌揑側弌棃帠偩偭偨偲偄偊傛偆丅
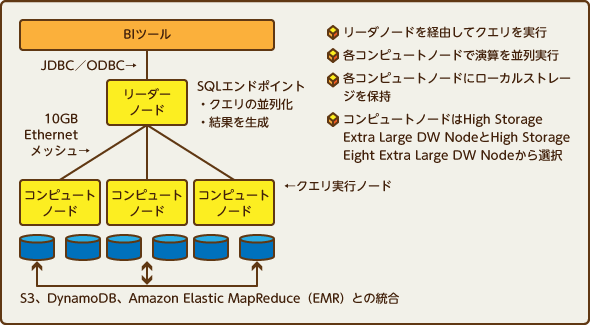 Amazon Redshift偺傾乕僉僥僋僠儍丂丂乽Redshift偑傕偨傜偡僨乕僞暘愅娐嫬偺怴帪戙乮Database Watch丂2013擭1寧斉乯乿傛傝丅僋儔僂僪忋偱僗僩儗乕僕傗僒乕僶乕僲乕僪偩偗偱側偔丄儕儗乕僔儑僫儖宆偺僨乕僞儀乕僗傪僒乕價僗偲偟偰棙梡偱偒傞傛偆偵側偭偨偙偲偱丄僨乕僞僂僄傾僴僂僗揑側價僢僌僨乕僞妶梡傪僋儔僂僪僨乕僞儀乕僗偱幚巤偟傛偆偲偄偆婡塣偑崅傑偭偨
Amazon Redshift偺傾乕僉僥僋僠儍丂丂乽Redshift偑傕偨傜偡僨乕僞暘愅娐嫬偺怴帪戙乮Database Watch丂2013擭1寧斉乯乿傛傝丅僋儔僂僪忋偱僗僩儗乕僕傗僒乕僶乕僲乕僪偩偗偱側偔丄儕儗乕僔儑僫儖宆偺僨乕僞儀乕僗傪僒乕價僗偲偟偰棙梡偱偒傞傛偆偵側偭偨偙偲偱丄僨乕僞僂僄傾僴僂僗揑側價僢僌僨乕僞妶梡傪僋儔僂僪僨乕僞儀乕僗偱幚巤偟傛偆偲偄偆婡塣偑崅傑偭偨丂偙偺帪婜偐傜丄僄儞僞乕僾儔僀僘梡搑偱棙梡偱偒傞僋儔僂僪忋偺僨乕僞儀乕僗僒乕價僗偑搊応偟巒傔傞丅椺偊偽丄儅僀僋儘僜僼僩偼IaaS乮Infrastructure as a Service乯忋偱偺SQL Server偺棙梡偩偗偱側偔丄PaaS偺乽Azure SQL Database乿偺惂尷傪娚榓偟丄僄儞僞乕僾儔僀僘梡搑偱傕巊偄傗偡偔偟偮偮偁傞丅傑偨AWS傕Redshift偵懕偄偰丄MySQL屳姺偱奼挘惈偲崅懍惈傪椉棫偡傞乽Aurora乿偺採嫙傪奐巒偟偨丅
丂IBM傕SoftLayer傪攦廂偟偰埲崀丄僋儔僂僪偱偺揥奐傪堦婥偵壛懍偟偰偄傞丅僨乕僞儀乕僗偺僒乕價僗偵偮偄偰傕DB2 BLU偺媄弍傪妶梡偡傞暘愅婎斦乽dashDB乿偺採嫙傪奐巒偟丄攦廂偵傛傝摼偨NoSQL偺乽Cloudant乿傕偁傞丅偝傜偵偼丄僆儔僋儖傕僷僽儕僢僋僋儔僂僪忋偱乽Database Cloud乿偺僒乕價僗傪奐巒偟偰偄傞丅
Copyright © ITmedia, Inc. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅