第4回 手を動かして強化学習を体験してみよう(自動運転ロボットカーDeepRacer編):AWS DeepRacer入門(2/3 ページ)
ステップ11: 学習状況の確認
学習(トレーニング)が開始されると、モデルのページ(例えば図15の[DeepInsiderEngine1]ページ)に遷移する。実際にシミュレーションが開始されるまでの準備処理に、6分程度の時間がかかり、そのあと、学習の様子が[Training]欄に表示されるようになる(図15)。

左側の[Reward graph](報酬グラフ)では、学習時の累積報酬や完走状況を視覚的に確認できる。また、右側の[Simulation video stream](シミュレーションのビデオストリーム)では、学習時の走行状況をビデオ映像で確認できる。それぞれ具体的な内容を紹介しよう。
報酬グラフ(報酬額)
グラフの下部にある[Reward](報酬)表示設定の、
- [Episode](エピソード): 散布図(点々)表示のオン/オフ
- [Average](平均): 折れ線グラフ表示のオン/オフ
をクリックして、いずれもオンに切り替えてみてほしい(※これらをオンにするときには、見やすさのため、後述の[Progress (percentage track completion)]表示設定はいずれもオフにした方がよい)。これにより、図16のように表示され、エピソード数が増えるに従って(=学習時間が増えるに従って)、累積報酬の額が大きくなっていっているのが分かる。

報酬グラフ(完走状況)
また、グラフの下部にある[Progress (percentage track completion)](コースの完走状況、%単位)表示設定の、
- [Episode](エピソード): 散布図(点々)表示のオン/オフ
- [Average](平均): 折れ線グラフ表示のオン/オフ
をクリックして、いずれもオンに切り替えてみてほしい(※これらをオンにするときには、見やすさのため、前述の[Reward]表示設定はいずれもオフにした方がよい)。これにより、図17のように表示され、エピソード数が増えるに従って(=学習時間が増えるに従って)、コース完走状況のパーセンテージが大きくなっていっているのが分かる。

シミュレーションのビデオストリーム(走行映像)
ビデオストリームには、学習時のシミュレーション映像が表示される。車の運転席の視点で動くので、ずっと見ていられる。
 図18 DeepRacer学習時のシミュレーション映像
図18 DeepRacer学習時のシミュレーション映像停止条件:最大時間(経過時間)
グラフ下部のさらに下には、[Stop condition](停止条件)で指定した[Maximum time](最大時間)の表示があり、図19のように経過時刻も表示される。

ステップ12: 学習(トレーニング)の完了
停止条件の最大時間になると、学習は自動的に停止する(図20)。なお、停止処理にも、開始時の準備処理と同様に、4分ほど時間がかかる。

学習中でも、左側の[Reward graph](報酬グラフ)は確認できたが、あらためて学習結果を確認してみよう(図21)。
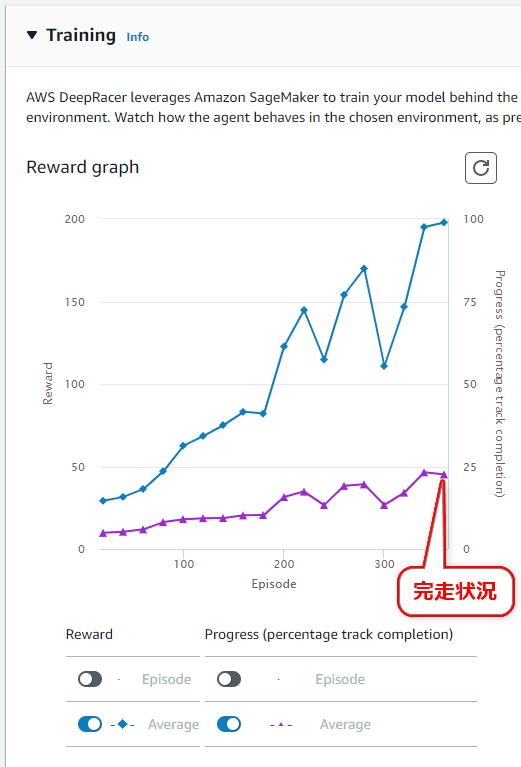 図21 学習結果の確認
図21 学習結果の確認図21を見ると、最終的な完走状況は25%弱というところで、つまり基本的にコースの4分の1程度走行したらコースアウトしてしまう。よって、まだまだ改善の余地が大きい走行エンジンとなっている。この場合、報酬関数やハイパーパラメーターをさらに調整して、モデルを再学習した方がよいだろう。
結果だけではなく、学習時のジョブ内容やログも閲覧できるので(※学習中に閲覧することも可能)、これらも紹介しておこう。
学習時のジョブ内容/ログの確認
実際に閲覧するには、[Stop condition]の下にある[Resources]欄にある各リンクをクリックすればよい(図22)。
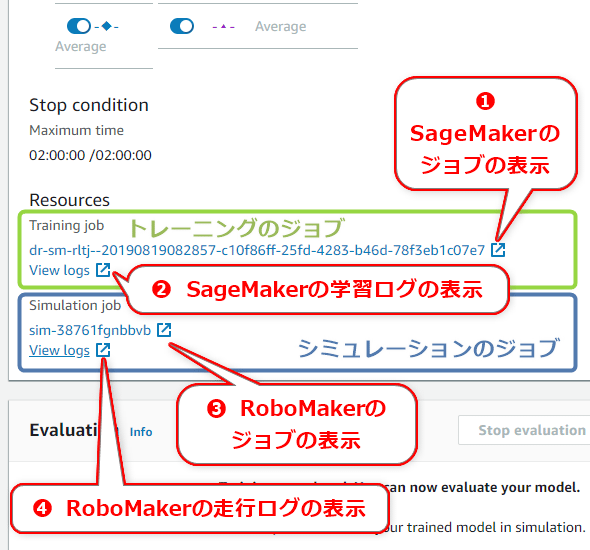 図22 学習時のジョブ内容/ログの確認
図22 学習時のジョブ内容/ログの確認それぞれ、以下のような内容が見られる。
- (1) SageMekerのジョブ: 例えばインスタンスのタイプや数、ディスク/メモリ/CPUの使用率(図23)など
- (2) CloudWatchに蓄積されたSageMekerの学習ログ: 例えばエピソード番号/累積報酬額/ステップ数(図24)など
- (3) RoboMakerのジョブ: 例えばシミュレーションアプリケーションで使用したソフトウェアや環境変数(図25)など
- (4) CloudWatchに蓄積されたRoboMakerの走行ログ: 例えばシミュレーションのトレースログ(図26)など




例えば(4)の走行ログを使うことで、さらに深く結果を分析することもできる(参考:「aws-deepracer-workshops/DeepRacer Log Analysis.ipynb at master · aws-samples/aws-deepracer-workshops」を使ったログ分析方法などがある)。
また、リスト1の報酬関数の実装コード内で、例えばprint("steering_angle: %.2f" % steering_angle)のような形でログ出力関数を呼び出せば、(4)の走行ログにその内容が出力される。「報酬関数が現実的にどのように挙動するか」を確認したい場合などで役立つだろう。
以上のようにして結果を確認してみて、全く学習がうまくいっていない場合は、ステップ2に戻ってモデルを新たに作成し直すか、後述の「学習済みモデルの再学習」に進んでほしい。
ある程度の結果が出ている場合は、モデルを評価してみよう。
学習済みモデルの評価
評価の設定と開始
モデルを評価するには、モデルのページ(本稿では[DeepInsiderEngine1]ページ)をスクロールして、[Training]欄の下にある[Evaluation]欄を開き、[Start evaluation]ボタンをクリックする。
![図27 [Evaluation]欄で、学習済みモデルの評価](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-27.gif)
ダイアログが表示され、シミュレーション環境であるレース会場の選択(前掲の図9と同じもの)が求められる。今回は、評価でも学習と同じ「re:Invent 2018」を選択しよう(図28)。
![図28 [Start evaluation]ダイアログで、シミュレーション環境であるレース会場の選択](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-28.gif)
さらにスクロールすると、[Specify stop condition](停止条件の設定)欄があり、その中に、
- [Number of trials](試行回数)欄: 3試行/4試行/5試行から選択。デフォルトは3試行
といった設定項目もある(図29)。これは「何回走行したら、評価を自動停止するか」という特定の基準を設定するためのものだ。
![図29 [Start evaluation]ダイアログで、試行回数の設定と評価の開始](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-29.gif)
ちなみに、自動停止以外にも、手動で停止することもできる(具体的には、後掲する図30の[Stop evaluation]ボタンをクリックすればよい)。
今回はデフォルト設定の「3 trials(試行)」のまま、右下の[Start evaluation]ボタンをクリックして、評価を開始しよう。
評価の実行
評価時の準備処理や終了処理にも、それぞれ数分の時間がかかる。評価の実行時には、図30に示すように、左側に[Simulation video stream](シミュレーションのビデオストリーム)、右側に「どれくらいの時間で(走行タイム)、コースの何%を完走したか(完走状況)」といった[Evaluation results](評価結果)が表示される。
![図30 [Evaluation]欄で、走行映像(左側)と評価結果(右側)と各リソースリンクの表示](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-30.gif)
評価が完了したら、[Evaluation]欄の下の方にスクロールすると、訓練時と同様に、
- (3) RoboMakerのジョブ(例:前掲の図25と同じ)
- (4) CloudWatchに蓄積されたRoboMakerの走行ログ(例:前掲の図26と同じ)
といったリンクが表示されるので、評価結果をさらに深く分析できる。
さらにその下には、[Training configuration]欄があり、学習時の設定情報を再確認できる(図31)。学習済みモデルを参考にして新たなモデルを作成したり、他の人に学習済みモデルの設定内容を説明したりする際に役立つだろう。
![図31 [Training configuration]欄で、学習設定の再確認](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-31.gif)
学習済みモデルの再学習
学習済みモデルを使って、設定をチューニングして再学習させたい場合は、モデルのページ(本稿では[DeepInsiderEngine1]ページ)のトップまでスクロールして、[Clone]ボタンをクリックする(図32)。

あとは、
- ステップ4: モデル名と説明の設定
- ステップ5: シミュレーション環境の選択
- ステップ6: 行動空間の設定(※参照はできるが、設定変更はできない)
- ステップ7: 報酬関数の実装
- ステップ8: ハイパーパラメーターの設定&調整
- ステップ9: 停止条件の設定
- ステップ10: 学習(トレーニング)の開始
- ステップ11: 学習状況の確認
- ステップ12: 学習(トレーニング)の完了
を繰り返すだけである(※全く同じなので説明は割愛する)。
学習が完了したら、
- 学習済みモデルの評価
- 学習済みモデルの再学習
をケースバイケースで実行すればよい。
バーチャルサーキットのレースリーグ(レース大会)への参加
バーチャルサーキットのレースリーグへの参加方法も紹介しておこう。
といっても、非常に簡単だ。具体的には、モデルのページ(本稿では[DeepInsiderEngine1]ページ)のトップまでスクロールして、[Submit to virtual race]ボタンをクリックするだけだ(図33)。

これにより、[Submit model to Shanghai Sudu](Shanghai Suduレース会場へのモデルの提出。※レース会場は月ごとなどで変更される可能性がある)ページが表示されるので、提出したいモデルが[Model]欄で選択されているのを確認して、[Submit model]ボタンをクリックする。これにより、学習済みモデル(本稿の例では「DeepInsiderEngine1」)が本当に提出される。
![図34 [Submit model to <レース会場>]ページで、モデルの提出(本当に提出)](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-34.gif)
提出すると、モデルが評価され、図35のように順位や走行タイムが表示される。
![図35 [Submit model to <レース会場>]ページで、モデルの提出(本当に提出)](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-35.gif)
お疲れさま。以上でDeepRacerの基本的な学習〜評価〜デプロイまでの作業は完了だ。最後に、リソースの削除をしておこう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。