第4回 手を動かして強化学習を体験してみよう(自動運転ロボットカーDeepRacer編):AWS DeepRacer入門(1/3 ページ)
強化学習が初めての人に最適な「AWS DeepRacerのコンソールとシミュレーション環境」を使って、ディープラーニングを体験してみよう。コンソール上で強化学習の各ハイパーパラメーターを設定してモデルに学習させ、さらに評価し、バーチャルレースにデプロイするまでの手順を解説する。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
AWS DeepRacerは、自律走行を行うロボットカーである(第1回詳しく説明した)。その走行エンジンの作成には、ディープラーニングの「強化学習」と呼ばれる手法が用いられる(第2回詳しく説明した)。強化学習による「学習」や「評価」は、シミュレーション環境(=シミュレーター)上で行えるようになっており、車の走り方、つまり強化学習のハイパーパラメーター(=学習を調整するための各種数値)などは、AWSコンソール(=各種操作をするためのWebページ)上で設定&調整できるようになっている(第3回詳しく説明した)。
本稿では、これまでの連載で解説した内容の実践編として、DeepRacerのコンソールを使ってモデルを学習&評価してバーチャルレースで走らせるまでの手順を解説する。前回解説した「コンソールの設定項目」の知識も必要となるため、必要に応じて前回の記事を参照してほしい。
初めてのDeepRacerモデルの作成と学習
DeepRacerコンソールを初めて使う人には、公式の日本語チュートリアルが非常に役立つ。しかしながら、ハイパーパラメーターなどの設定は読者任せになっているので、強化学習の初心者にとっては(不慣れでうまく学習させられないなど)つまずくケースも多いのではないかと思う(というか、筆者自身が最初はうまくいかずに苦労した)。
そこで本稿では、筆者が試してみて、比較的うまくいき、しかもシンプルだった設定内容を、読者にもまねてもらうことを想定して、DeepRacerコンソールの基本的な操作手順を解説する(※2019年8月19日時点の情報。今後、設定項目などが変わる可能性もあるので、ご了承いただきたい)。
ステップ1: AWS DeepRacerコンソールを開く
上記リンク先を開き、図1に示すように、右上の[コンソールにサインイン]ボタンをクリックして、AWSコンソールにサインインする。AWSアカウントを持っていない場合は、公式ドキュメント「AWS アカウント作成の流れ」を参考にするなどして、まずはアカウントを作成する必要がある。
![図1 [コンソールにサインイン]ボタンをクリック(AWS公式ホームページ)](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-01.gif)
コンソールのホームページが開いたら、図2に示すように、右上にあるリージョンを「米国東部 (バージニア北部)」(North Virginia)に変更した上で、[サービスを検索する]欄に「DeepR」(acer)などと入力し、表示される候補一覧から[AWS DeepRacer]を選択する。※執筆時点(2019年8月19日)では、バージニア北部以外の、例えば「アジアパシフィック (東京)」などは、AWS DeepRacerのコンソールをサポートしていなかったので注意してほしい。

ステップ2: モデルの作成を開始する
DeepRacerコンソールのホームページが開いたら、図3に示すように、左にあるメニューから[Reinforcement learning](強化学習)リンクをクリックする(もしくは中央にある[Get started]ボタンをクリックする)。

これにより、[Reinforcement learning]ページが開く(図4)。このページでは、作成済みのモデルの一覧が表示される(※現時点ではモデルは未作成なので表示されない)。また、ここから新規のモデルを作成することもできる。
今回はモデルを新規に作成したいので、[Create model]ボタンをクリックする。
![図4 [Reinforcement learning]ページで、[Create model]ボタンをクリック](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-04.gif)
ステップ3: DeepRacerリソースの作成
[Create model]ページが開いたら、トップに[Overview]欄がある。ここでは、DeepRacerの強化学習や、学習プロセス、学習後のデプロイについての概要が解説されている(本連載を読んできた読者なら、この内容は理解しているはずなので、読む必要はないだろう)。
その下にある[Account resources]欄の[Create resources]ボタンをクリックしよう(図5)。これにより、「IAMロール」やDeepRacerリソーススタック(具体的には「S3バケット」「Amazon SageMaker」「RoboMakerシミュレーションアプリケーション」など、DeepRacerに必要な関連リソース)が自動作成される。
![図5 [Create model]ページで、[Create resources]ボタンをクリック](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-05.gif)
作成には5分程度かかる。それぞれ作成が完了すると、図6の[You have valid IAM roles]/[You have a valid AWS DeepRacer resources stack]の左にあるような緑色のチェックマークが付く。
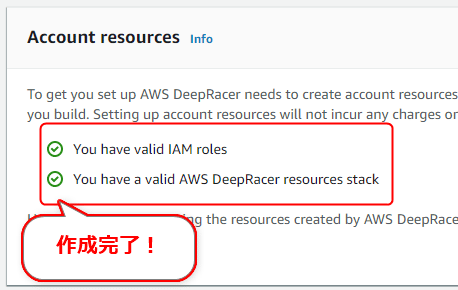 図6 関連リソースの作成完了
図6 関連リソースの作成完了【参考】自動作成されるサンプルモデル
ちなみに、この段階で図4の[Reinforcement learning]ページを開くと、図7のように、3つほどサンプルのモデル(Sample-Prevent-zig-zag/Sample-Stay-on-track/Sample-Follow-center-line)が生成されているのが確認できる。必要に応じて、これからクローン(=コピー)して新しいモデルを作成することもできる。

なお、以降の手順に進むには、再度、[Create model]ボタンをクリックして[Create model]ページを開き直すこと。
いよいよここから、モデル作成のための各種設定を行っていく。
ステップ4: モデル名と説明の設定
[Create model]ページの[Model details]欄までスクロールし、
- [Model name](モデル名)欄: 必須。64文字まで。アルファベットの大文字/小文字、数字とハイフン(-)が使える
- [Model description](説明)欄: オプション(=必須ではない)。255文字まで
の2箇所に、任意の値を入力する(図8)。
![図8 [Model details]欄で、モデル名と説明の設定](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-08.gif)
本稿では、
- [Model name]欄: DeepInsiderEngine1
- [Model description]欄: Deep InsiderのDeepRacerエンジン第1号です。
と入力したと仮定して、以降の話を進めていく。
ステップ5: シミュレーション環境の選択
次に、[Environment simulation]欄までスクロールし、
- re:Invent 2018
- Shanghai Sudu Training
- Empire City Training
- Kumo Torakku Training
- London Loop Training
- Bowtie Track
- Oval Track
- AWS Track
などからレース会場を選択する(図9)。
![図9 [Environment simulation]欄で、シミュレーション環境であるレース会場の選択](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-09.gif)
選択基準としては、カーブの多さなど走行の難しさを考慮して、今の自分の実力に合わせたものを選択するとよい。今回は、最も代表的で、初心者向きな、
- re:Invent 2018
を選択しよう。
ちなみに、報酬関数を個別のレース会場に合わせて実装することで、レースの成績を上げる手法もある。そのような手法を採用するケースでは、シミュレーション環境であるレース会場の選択は重要である。そのような手法の場合、レース会場を変えたとたんに、まともに走行できなくなる可能性も考えられる。
ステップ6: 行動空間の設定
続いて、[Action space]欄までスクロールして行動空間を設定する(図10)。
![図10 [Action space]欄で、行動空間の設定](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-10.gif)
行動空間とその設定指針については、前回、詳しく説明した。よく分からない場合は、前回の解説を一読してから、自分なりに適切な値を設定するとよい。今回は、シンプルかつ安定感のある走りを想定して、
- [Maximum steering angle](最大ステアリング角度)欄: 30 度(degrees)
- [Steering angle granularity](ステアリング角度の分割数)欄: 5 段階
- [Maximum speed](最大スピード)欄: 1 m/s
- [Speed granularity](スピードの分割数)欄: 1 段階
と設定しよう。
前回も説明したが、行動空間の設定は、モデルの新規作成時(つまり最初の1回)だけで、再学習の際に変更できない(※他の各種設定は、モデルの学習完了後に変更/調整して、モデルを再学習させられる)という点に注意してほしい。再学習時に行動空間の設定を変えたい場合には、学習済みモデルのクローン(=コピー)ではなく、別のモデルを新規に作成する必要がある。
ステップ7: 報酬関数の実装
さらに、[Reward function]欄までスクロールして報酬関数を実装する(図11)。
![図11 [Reward function]欄で、行動空間の設定](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-11.gif)
報酬関数やその実装方法についても、前回、詳しく説明した。よく分からない場合は、再度、前回の解説を一読してから、自分なりのロジックを考えて独自のPythonコードで実装するとよい。今回は、初めての人でもすぐに実装でき、(サンプルの中では)比較的、精度が高い、
- サンプルコード: Prevent zig-zag
を利用しよう。報酬関数を実装する手順の説明は前回行ったので、詳細は割愛するが、簡単にいうと[Reward function examples]ボタンをクリックして、[Prevent zig-zag]を選択し、最後に[Use code]ボタンをクリックするだけである(※前回の図8〜図9を参照)。
このサンプルコードの内容や各行の意味については、リスト1にあるコード中のコメントを参考にしてほしい。
def reward_function(params):
'''
ジグザグ走行を緩和するためにステアリングにペナルティを科す報酬関数の例
'''
# 入力パラメーター(車の各種情報)を読み込む
distance_from_center = params['distance_from_center'] # センターラインからの距離
track_width = params['track_width'] # コースの幅
steering = abs(params['steering_angle']) # ステアリング角度の絶対値
# センターラインからの距離を表す、3段階のコース幅のマーカーを計算する
marker_1 = 0.1 * track_width # コース幅の10%の距離
marker_2 = 0.25 * track_width # コース幅の25%の距離
marker_3 = 0.5 * track_width # コース幅の50%の距離
# 車がセンターラインに近ければ近いほど、高い報酬を与える
if distance_from_center <= marker_1:
reward = 1.0 # 10%幅内を走行中の場合は1.0ポイントの報酬
elif distance_from_center <= marker_2:
reward = 0.5 # 25%幅内なら0.5ポイント
elif distance_from_center <= marker_3:
reward = 0.1 # 50%幅内なら0.1ポイント
else:
reward = 1e-3 # それらよりも外なら1e-3(=0.001)ポイント
# クラッシュしたか、コースアウトに近い状態と見なすということ
# ペナルティを課す、ステアリング角度の閾値
ABS_STEERING_THRESHOLD = 15 # 絶対値で15度
# 行動空間の設定に応じて変更する。今回は、0/±15/±30度の3段階なので、
#(±15度より大きい)±30度のステアリングにのみペナルティを科す
# 車のステアリング角度が閾値より大きい場合には、報酬にペナルティを科す
if steering > ABS_STEERING_THRESHOLD:
reward *= 0.8 # ペナルティとして、報酬を20%カット(=80%付与)する
# 計算された報酬は、関数の呼び出し元にfloat値として返却する
return float(reward)
ステップ8: ハイパーパラメーターの設定&調整
次に、[Hyperparameters]欄までスクロールしてハイパーパラメーターを設定&調整する(図12)。[Hyperparameters]欄は閉じられている場合がある。その場合は、左上の[▼]ボタンをクリックして開いてほしい。
![図12 [Hyperparameters]欄で、ハイパーパラメーターの設定&調整](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-12.gif)
ハイパーパラメーターやその設定効果については、前回、詳しく説明した。よく分からない場合は、再度、前回の解説を一読してから、自分なりに適切な値を設定するとよい。今回は、初期設定のままで、
- [Gradient descent batch size](バッチサイズ)欄: 64
- [Number of epochs](エポック数)欄: 10
- [Learning rate](学習率)欄: 0.0003
- [Entropy](エントロピー)欄: 0.01
- [Discount factor](割引率)欄: 0.999
- [Loss type](損失タイプ)欄: Huber
- [Number of experience episodes between each policy-updating iteration](トレーニングごとの経験エピソードの数)欄: 20
を設定しよう。
ステップ9: 停止条件の設定
最後に、[Stop conditions]欄までスクロールして、学習を停止する条件を設定する(図13)。
![図13 [Stop conditions]欄で、停止条件の設定](https://image.itmedia.co.jp/l/im/ait/articles/1908/22/l_di-13.gif)
通常、ディープラーニングなどの学習では、「どこまで学習させるか」など、学習を停止させるための「特定の基準」を作る。例えば「何件のデータを何回学習させるか」や、「モデルの精度(=正確度など)が安定してきたら早めに学習を停止する」(早期停止:Early stopping)などの基準だ。
執筆時点(2019年8月19日)のDeepRacerコンソールでは、その基準の一つとして[最大時間]が設定できる。シミュレーション環境では何回でもレース会場を走れるので際限がない。そこで、時間を基準に学習を終了させようというわけである。
[最大時間]欄は、5〜480分(minutes)(つまり8時間まで)が設定可能で、デフォルトは「60 mins(分)」となっている。今回は、ほどよく学習が進むように、
- [Maximum time](最大時間)欄: 120 分
を設定しよう。
ステップ10: 学習(トレーニング)の開始
以上で、モデルの各種設定は完了だ。あとは、ページの最後までスクロールして、[Start training]ボタンをクリックすれば(図14)、いよいよ学習(トレーニング)が開始される。

続いて以下では、学習〜評価までの手順を見ていこう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。