データサイエンティストに優しいフレームワーク「Metaflow」、Netflixがオープンソース化:AWSと容易に連携できる
Netflixは、データサイエンスプロジェクトの構築や管理のフレームワークとして開発、利用してきた「Metaflow」をオープンソース化した。データサイエンティストに余分な負担を掛けずに利用できるよう設計されており、AWSを通じて大規模に展開しやすい。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
Netflixは2019年12月3日(現地時間)、データサイエンスプロジェクトを迅速かつ容易に構築、管理するためのフレームワーク「Metaflow」をオープンソースソフトウェアとして公開した。
MetaflowはNetflixが開発したPythonライブラリ。コンテンツ配信やビデオエンコーディングの最適化など、社内の何百ものユースケースに2年間、Metaflowを用いてデータサイエンスを適用してきたという。

なぜMetaflowを開発したのか
Metaflowの開発が始まる前、Netflixの機械学習インフラチームはデータサイエンティストに対して社内では何が困難なのかをインタビューした。大規模なデータの扱いやモデル作り、最新GPUに関した回答が集まると当初は考えていたものの、予想は外れた。
最も困難だったのは、「バージョン1」のローンチに到達するまであまりにも時間がかかることだったという。原因はありふれたソフトウェアエンジニアリングにあった。
そこで伝統的な統計から最新のディープラーニングまで、要求の厳しい幅広いプロジェクトに取り組むデータサイエンティストの生産性を高めるためにMetaflowを開発したのだという。使い勝手を重視して開発しており、同社はMetaflowを「人間中心のデータサイエンスフレームワーク」とも呼んでいる。
多くのデータサイエンティストは、プロジェクトに最適なモデリング手法を自由に選択できることが重要だと感じている。多数のモデルについて特徴量エンジニアリングが重要であることを認識しており、モデル入力と特徴量エンジニアリングロジックのコントロールを維持したいと考えている。多くの場合、データサイエンティストは、独自のモデルを使うことに非常に熱心だ。理由はモデルのトラブルシューティングと繰り返しの高速化が可能になるからだ。
その一方で、データウェアハウスの性質や、モデルを訓練してスコアリングするコンピューティングプラットフォーム、ワークフロースケジューラーについて、あまり重視していないことが分かった。
だが、例えば開発中にエラーが発生した場合は、明快なエラーメッセージが必要だ。明快なとは、作業の状況に応じてエンジニアが理解しやすいという意味だ。
Metaflowの魅力とは?
データサイエンティストは「PyTorch」「TensorFlow」「SciKit Learn」など、お気に入りのデータサイエンスライブラリとともにMetaflowを使って、普段使い慣れているPythonコードでモデルを作成できる。
Metaflowを使うために新たに学ぶべきことは少ない。例えば、冒頭の図では、データとモデルが通常のPythonインスタンス変数として格納されている。Metaflowがデフォルトでサポートしている分散コンピューティングプラットフォーム上でコードを実行した場合でも、問題なく動作するように設計されている。
他の多くのフレームワークでは、成果物のロードとストアはユーザーが工夫しなければならない課題として残っている。ユーザーは何を永続化すべきか、何を永続化すべきでないかを判断しなければならない。Metaflowではこのような負担がない。
Metaflowは、ワークフローの設計はもちろん、大規模な実行や本番環境へのデプロイまでを支援する。全ての実験とデータについて、自動的にバージョン管理とトラッキングが実行されて、「ノートブック」でワークフロー結果を簡単に検証できる。
AWSと連携するクラウドネイティブなフレームワーク
Metaflowはクラウドネイティブを特徴とするフレームワークであり、コンピュートとストレージの両方でクラウドの弾力性を利用するように設計されている。
技術的には、任意のクラウドと連携が可能だが、現時点では、リモートバックエンドとしてAmazon Web Services(AWS)のみをサポートしている。Netflixが長年にわたるAWSユーザーであり、その運用ノウハウを蓄積してきたことが背景にある。
NetflixはMetaflowのオープンソース化に当たってAWSと協力し、MetaflowとAWSのさまざまなサービスのシームレスな連携を可能にした。両者の連携の概要は以下の通り。
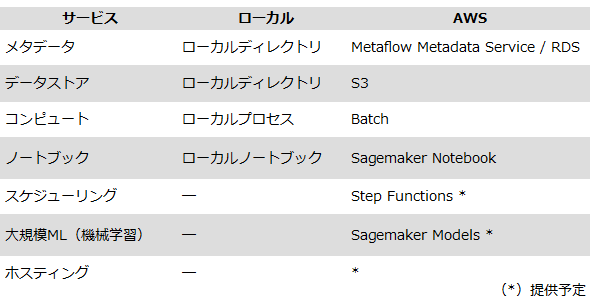 MetaflowとAWSの関係(
MetaflowとAWSの関係(この図にある「サービス」の意味は次の通りだ。
- メタデータ Metaflow Client APIの基盤となるバックエンド
- データストア 全てのコードとデータ成果物のストレージバックエンド
- コンピュート Metaflowタスクのコンピュートバックエンド
- ノートブック Metaflowの実行結果を検証する手段
- スケジューリング 人間が介在せずにMetaflowワークフローを自動的に実行する手法。本番ワークフローでは一般的な手法となる
- 大規模ML(機械学習) 大規模モデルのトレーニングに有用
- ホスティング Metaflowの実行結果をマイクロサービスとしてデプロイできる。実行結果は他のアプリケーションでプログラマティックに利用できる
関連記事
 機械学習の精度を左右する「データ加工」の基礎知識――「攻めのデータ加工」=「特徴量エンジニアリング」編
機械学習の精度を左右する「データ加工」の基礎知識――「攻めのデータ加工」=「特徴量エンジニアリング」編
AIに欠かせない数学を、プログラミング言語Pythonを使って高校生の学習範囲から学び直す連載。前回から2回に分けて「データ加工」の手法を紹介します。今回は「攻めのデータ加工」です。 「データサイエンス部隊が内製で切磋琢磨」から方針転換――機械学習/AIプロジェクトが守るべき4つの骨子
「データサイエンス部隊が内製で切磋琢磨」から方針転換――機械学習/AIプロジェクトが守るべき4つの骨子
リクルートジョブズが機械学習/AIをサービスに活用するプロジェクトで得た知見を紹介する連載。初回は、リクルートジョブズでデータサイエンス部隊が立ち上がった頃に起こった問題について。 何が違う? 何が必要? マイクロサービス/サーバレス時代のセキュリティ
何が違う? 何が必要? マイクロサービス/サーバレス時代のセキュリティ
従来のモノリシックなアーキテクチャに代わって着目されている「マイクロサービス」や「サーバレス」。これらの新しいアーキテクチャについて、セキュリティの観点からどのようなことに留意すべきなのだろうか。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。