[NumPy超入門]データ処理の最初の一歩! 基本統計量からデータの特徴を把握しよう:Pythonデータ処理入門(1/2 ページ)
データセットがどのような特徴を持つのか、その基本は最大値/最小値/平均値/中央値/最頻値/標準偏差などの基本統計量を使って調べられます。実際のデータを使って、これを体感してみましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
連載概要
本連載はPythonについての知識を既にある程度は身に付けている方を対象として、Pythonでデータ処理を行う上で必須ともいえるNumPyやpandas、Matplotlibなどの各種ライブラリの基本的な使い方を学んでいくものです。そして、それらの使い方をある程度覚えた上で、それらを活用してデータ処理を行うための第一歩を踏み出すことを目的としています。
前回はデータセットから基本統計量を調べる基本的なツールとして、最大値/最小値/平均値/中央値/最頻値/分散/標準偏差を求める以下の関数を紹介しました。
| 基本統計量 | 関数 |
|---|---|
| 最大値 | numpy.max関数 |
| 最小値 | numpy.min関数 |
| 平均値 | numpy.mean関数/numpy.average関数 |
| 中央値 | numpy.median関数 |
| 分散 | numpy.var関数 |
| 標準偏差 | numpy.std関数 |
| 基本統計量を調べる関数 | |
今回はカリフォルニアの住宅価格をまとめたCalifornia Housingデータセットを対象にしてこれらの関数を実際に使ってみることにします。
California Housingデータセット
California Housingデータセットについては本フォーラムのデータセット辞典「California Housing:カリフォルニアの住宅価格(部屋数や築年数などの8項目)の表形式データセット」で紹介をしているので、詳しくはそちらをご覧ください。ここでは、scikit-learnが元データを加工した上で提供しているこのデータセットを使用します。そのため、「pip install scikit-learn」「pip3 install scikit-learn」「py -m pip install scikit-learn」などをコマンドラインから実行してscikit-learnを事前にインストールしておく必要があります。

scikit-learnがインストールできたら、次にCalifornia Housingデータセットの概要についても触れておく必要があります。これはカリフォルニア州をアメリカの国勢調査で使用されている地理的な区分(これをブロックグループと呼びます)に分け、ブロックグループごとに以下のデータを表形式にまとめたものです(かっこ内はデータセット内でその列に付けられている名前です。ただし、NumPyではこれらを直接指定できません)。
- 所得の中央値(MedInc)
- 築年数の中央値(HouseAge)
- 平均の部屋数(AveRooms)
- 平均の寝室数(AveBedrms)
- ブロックグループ内の人口(Population)
- 世帯人数の平均値(AveOccup)
- 緯度(Latitude)
- 経度(Longitude)
そして、これらのデータと関連付けられる住宅価格の中央値(MedHouseVal)で構成されます。上記の8種類のデータを基に住宅価格を予想するためのデータセットとなっていて、8種類のデータのことを説明変数とか特徴量(この場合は住宅価格を決定する要因として考えられるデータ)と呼び、住宅価格のことを目的変数とか正解ラベル(8種類のデータを用いて何らかの処理を行った結果、得られる値の正解値)と呼びます(1990年の国勢調査から得られたデータが基になっています。また、AveRooms/AveBedrms/AveOccupの3列は処理しやすくなるようにscikit-learnが元のデータを加工したものです)。
 California Housingデータセット
California Housingデータセット論文著者: R. Kelley Pace and Ronald Barry
タイトル: Sparse Spatial Autoregressions, Statistics and Probability Letters, 33, 291-297.
公開年: 1997
URL: http://lib.stat.cmu.edu/datasets配下の、houses.zip内に含まれるcadata.txt
要するにブロックグループの所得が高ければ、その地域の住宅価格は高くなっているんじゃないのか、それはどのくらいの価格なのかとか、そんなことを考えるためのデータセットということです。
今回はそこまではやらないのですが、平均値や最大値、最小値などを眺めて、このデータセットにはどんな特徴があるのかをざっくりと見てみましょう。基本統計量の確認は、データ処理において最初の一歩ともいえる要素です。
まずはデータセットを読み込んで、データセットについて基本的な確認をしておきましょう。
データセットの読み込み
データセットを読み込むには、scikit-learnが提供しているfetch_california_housing関数を呼び出すだけです。
import numpy as np
from sklearn.datasets import fetch_california_housing
ca_housing_data = fetch_california_housing()
これにより変数ca_housing_dataにはこのデータセットの説明変数と目的変数やデータセットの説明などが含まれた辞書形式のデータが代入されます。実際にどんなデータが含まれているかをdir関数で調べてみましょう(dir関数を使うと、対象のオブジェクトにどんな属性や関数、メソッドなどが含まれているかを確認できます)。
print(dir(ca_housing_data))
実行結果を以下に示します。

これらの属性について以下に簡単にまとめます。
- DESCR:データセットに関する説明が含まれている
- data:上で述べた8種類のデータ(説明変数、特徴量)が表形式で格納されている、いわばデータセットの本体
- feature_names:8種類のデータのそれぞれの列に付けられた名前(MedIncなど)
- frame:pandas形式で読み込んだ場合にDataFrameが格納される
- target:住宅価格の中央値(目的変数、正解ラベル)。dataに格納された値から何らかの処理を行いtargetの値に近い値を得られるようにすることが本データセットの目的
- target_names:住宅価格の中央値を含む列の名前(MedHouseVal)
そこでまずはデータセットの説明(ca_housing_data.DESCR属性)に目を通すことにしましょう。
print(ca_housing_data.DESCR)
これらにはca_housing_data['DESCR']と辞書と同様な形でも、ca_housing_data.DESCRのように属性の形式でもアクセスできます。ここでは後者のやり方をしています。実行すると、次のようにデータセットに関する説明が表示されます。

出力が長いので途中で表示が省略されていますが、全てを確認するのであれば最下行の[scrollable element]か[text editor]というリンクをクリックしてください(ここではしません)。
この説明には重要な情報が幾つか書かれていることが分かるでしょうか。
- 「Number of Instances: 20640」:データの総数が20640件
- 「Missing Attribute Values: None」:欠損値はない
データの総数とこのデータセットには欠けているデータがないことが分かりました。その他の情報については既に述べた通りです。
次に説明変数(特徴量)を格納しているdata属性についても見てみます。辞書と同様なアクセスと属性的なアクセスがどちらも可能であることも確認してください。
print(ca_housing_data.data.shape)
print(ca_housing_data['data'])
1行目ではdata属性の形状を確認しています(本当に20640行8列のデータになっているでしょうか)。2行目は実際のデータの確認です。
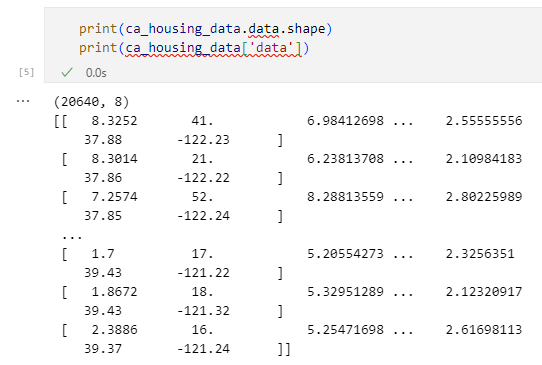 data属性の確認
data属性の確認最初の出力を見ると、説明変数として確かに20640行8列のデータが含まれているようです。次の出力はやはり途中が省略されていますが、実際にはこうしたデータが格納されているんだということが分かります。
目的変数(正解ラベル、target属性)がどうかについても確認しておきましょう。
print(ca_housing_data.target.shape)
print(ca_housing_data.target)
結果は以下の通りです。
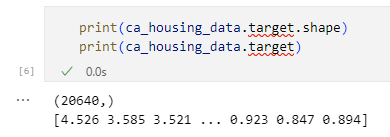 目的変数の確認結果
目的変数の確認結果1次元配列に20640個のデータが格納されていることが分かりました。
次に今回は説明変数と目的変数を1つの配列に結合してから、最大値や平均値などの値を確認します。
配列の結合
説明変数が20640行8列の2次元配列となっているので、ここではその右端に目的変数を結合することにしましょう。つまり、20640行9列のデータセットを作成するということです。
配列を結合するには幾つかの方法がありますが、ここではnumpy.hstack関数を使うことにしました。注意点としては、この関数を使って配列同士を結合するには、目的変数が20640行1列の2次元配列となっている必要がある点です(20640行の1次元配列では結合できません)。そのため、ここではreshapeメソッドを使って目的変数を含む配列を20640行1列の2次元配列に変換することにしました。
その後、説明変数を含む配列(以下のコードでは変数featuresに格納されています)と目的変数を含む配列(同じく、変数targetに格納されています)の2つを要素とするリストをnumpy.hstack関数に渡すことで2つの配列を結合しています。
features = ca_housing_data.data
target = ca_housing_data.target
target = target.reshape(-1, 1)
data = np.hstack([features, target])
print(data.shape)
print(data)
reshapeメソッドに渡しているのは配列の新しい形状ですが、最初の「-1」は「この次元の要素数は他の次元の要素数から推測してください」ということを意味しています。つまり、新しい形状は(X, 1)となるのですが、ここでは列の要素の数が1なので、行の要素の数は自動的に20640になるということです。
上のコードを実行すると、配列が結合され、その形状とデータが表示されます。
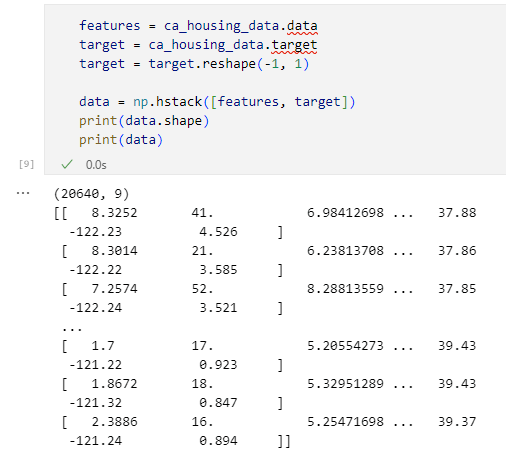 結合後の形状とデータの確認
結合後の形状とデータの確認これを見ると、うまく結合できているようです。
ここまで来たら、結果を別途CSVファイルに保存したくなりませんか?(人は何かをした証を残したいものなのです)。これにはnumpy.savetxt関数が使えます。また、ヘッダー行も欲しいところですが、これは大本のデータセットのfeature_names属性とtarget_names属性から作成できるでしょう。というわけで、以下が結合後の2次元配列をCSVファイルとして保存するコードです。
columns = ca_housing_data.feature_names + ca_housing_data.target_names
print(columns)
np.savetxt('test.csv', data, header=','.join(columns), delimiter=',')
numpy.savetxt関数には保存するファイルの名前、保存するデータの指定が必須です。ここでは、その他に各列の名前をカンマで区切ったものをheaderパラメーターに、区切り文字としてカンマをdelimiterパラメーターに指定しています(これは実行結果は不要でしょう)。
そして、2次元配列の各列を0や1などの数値ではなく、上で紹介した列ごとに付けられている名前でアクセスできると便利なので、ちょっと用意しておきます。
col = {k: v for v, k in enumerate(columns)}
print(col)
# 出力結果:
# {'MedInc': 0, 'HouseAge': 1, 'AveRooms': 2, 'AveBedrms': 3, 'Population': 4,
# 'AveOccup': 5, 'Latitude': 6, 'Longitude': 7, 'MedHouseVal': 8}
print(col['MedInc']) # 0
これは'MedInc'や'AveRooms'などの文字列をキーとして、対応する列インデックスの値を取り出せる辞書を作成するコードです。特定の列の最大値を求めるのに「np.max(data[:, 0])」のようにするのではなく、最後の行のように「np.max(data[:, col['MedInc']])」とすることで何をしているのか少しは分かりやすくなりそうです(と思ったのですが、実際にはこのような直接的な書き方はほぼほぼしませんでした)。
ずいぶんと長くなってしまいましたが、データの読み込みと基本データの確認、使いやすいようにデータを変形することもデータ処理には重要な要素なので、ここではネチネチを書き連ねてきました。この後は前回に紹介した関数を使って実際のデータを扱ってみます。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。