[pandas超入門]データセットの前処理をしてみよう:Pythonデータ処理入門
タイタニックデータセットを使って、欠損値の扱い方、不要な列の削除、カテゴリカルデータのエンコーディングなど、前処理の仕方を見ていきましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
本シリーズと本連載について
本シリーズ「Pythonデータ処理入門」は、Pythonの基礎をマスターした人を対象に以下のような、Pythonを使ってデータを処理しようというときに便利に使えるツールやライブラリ、フレームワークの使い方の基礎を説明するものです。
- NumPy(「NumPy超入門」の目次はこちら)
- pandas(本連載)
- Matplotlib
なお、本連載では以下のバージョンを使用しています。
- Python 3.12
- pandas 2.2.1
前回はタイタニックデータセットをpandasに読み込んで、その概要を調べた後、性別と生存率、または旅客クラスと生存率に関連があるかどうかなどを見てみました。このとき、欠損値を含む列('Cabin'列)などについてはそのままにしていました。今回はこのような列をどう処理すればよいのかや、機械的な処理が簡単になるように性別や旅客クラスを数値データに変換する方法などを見ていきます。このような作業のことを「前処理」と呼びます。前処理はデータセットを機械学習やディープラーニングで適切に取り扱えるようにするための重要なステップですが、今回はその練習のようなものです。
取り掛かる前に、タイタニックデータセットの内容をDataFrameオブジェクトに読み込んでおきましょう(タイタニックデータセットは前回同様にpandasのGitHubリポジトリからダウンロードしました)。
import pandas as pd
df = pd.read_csv('titanic.csv')
欠損値を含む列
以下はタイタニックデータセットの内容をざっくりと表示したものです。

'Age'列と'Cabin'列には「NaN」と表示されている箇所があることが確認できます。そこで前回もやりましたが、infoメソッドを呼び出して、各列の状態を確認してみたのが以下です。
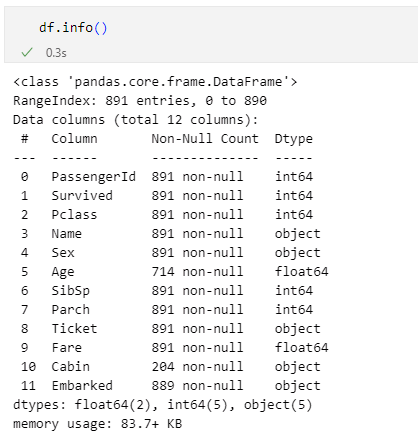 欠損値を含む列は'Age'列と'Cabin'列、'Embarked'列の3つ
欠損値を含む列は'Age'列と'Cabin'列、'Embarked'列の3つ前回も述べましたが、このデータセットには891行のデータがあり、各行は12個の列で構成されています。そして、infoメソッドの出力結果を見ると、'Age'列(年齢)には欠損していないデータが714個、'Cabin'列(客室番号)には欠損していないデータが204個、'Embarked'列(乗船値)には欠損していないデータが889個あることが分かります。
これらのうち、'Cabin'列に関しては欠損しているデータが多過ぎることから、今回は素直にこの列は削除してしまうことにしましょう(後述)。残る2つの列については何とかならないかを少し考えたいと思います。
'Embarked'列
まずは欠損値が少ない'Embarked'列について考えてみましょう。'Embarked'列の値は乗船値を表すもので'S'ならサウサンプトン、'C'ならシェルブール、'Q'はクイーンズタウンであることを示しています。そこで、前回も詳しく説明せずに使ってしまったgroupbyメソッドを使って、この列の値ごとにデータをまとめてみます。以下は今回使用する範囲でのgroupbyメソッドの使い方をまとめたものです。
pandas.DataFrame.groupbyメソッド
pandas.DataFrame.groupby(by=None)
DataFrameオブジェクトを指定した列の値ごとにグループにまとめる。byパラメーターに複数の列名を要素としたリストを渡すと、それらの列名ごとにグループが細分化される。groupbyメソッドの戻り値はDataFrameGroupByオブジェクトであり、このオブジェクトにさらに集計などを行うメソッドを呼び出すことでグループごとの情報を取得できる(詳細はpandasのドキュメント「pandas.DataFrame.groupby」「Group by: split-apply-combine」などを参照のこと)。
ここでは'Embarked'列の値でグループを作成したら、そのsizeメソッドを呼び出して、乗船地の分布がどうなっているかを確認してみましょう。
df.groupby('Embarked').size()
実行した結果を以下に示します。
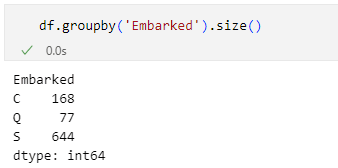 サウサンプトンから乗船した人が一番多いことが分かる
サウサンプトンから乗船した人が一番多いことが分かるサウサンプトン('S')から乗船した人が644人、シェルブール('C')から乗船した人が168人、クイーンズタウン('Q')から乗船した人が77人であることが分かりました。この列で欠損しているのは2つのデータだけです。幾つかの方法は考えられます。例えば、欠損している行を削除してしまうとか。あるいは、3つの乗船地のいずれかでデータを補完するのもありでしょう(平均を取るわけにはいきませんよね。後で出てきますが、このようなデータのことを「カテゴリカルデータ」といいます)。ここでは最頻値である'S'を使ってデータを補完することにします。
欠損しているデータを補完するにはDataFrameオブジェクト(またはSeriesオブジェクト)のfillnaメソッドを使用します。
pandas.DataFrame.fillnaメソッド
pandas.DataFrame.fillna(value=None)
pandas.Series.fillna(value=None)
DataFrameオブジェクトまたはSeriesオブジェクトの欠損値を補完する。valueパラメーターには補完に使用する値または辞書などを指定できる。全てのパラメーターについてはpandasのドキュメント「pandas.DataFrame.fillna」「pandas.Series.fillna」を参照のこと。
既に'Embarked'列の最頻値が'S'であることは分かっていますが、ここでは'Embarked'列に対してmodeメソッドを呼び出して、最頻値(mode)を取得するところからやってみましょう。
mode = df['Embarked'].mode()
print(mode)
print(type(mode))
print(mode[0])
実行結果は次のようになりました。
 最頻値を求める
最頻値を求める「df['Embarked'].mode()」とすることで、ここでは'Embarked'列の最頻値を取得しています。ただし、その戻り値はSeriesオブジェクトになっているので、インデックスに0を指定して、その先頭要素を取得すればよいでしょう。
では、fillnaメソッドで欠損値を最頻値で補完しましょう。ここではDataFrameオブジェクトのfillnaメソッドを呼び出してみます。
df2 = df.fillna({'Embarked': mode[0]})
ここでは何かを失敗してもやり直せるように変数df2に欠損値を補完した後のオブジェクトを代入しています(問題なければ元の変数dfに代入してもよいでしょう)。valueパラメーターには「{'Embarked': mode[0]}」と指定をしています。これにより、'Embarked'列の欠損値をmode[0]の値で補完することになります。あるいは次のようなコードも書けます。
df2 = df.copy()
df2['Embarked'] = df2['Embarked'].fillna(mode[0])
これは(やはり失敗したときにやり直せるように)変数df2にdfのコピーを代入し、その後で「df2['Embarked'].fillna(mode[0])」としてSeriesオブジェクトの欠損値を補完し、その結果をdf2['Embarked'](Seriesオブジェクト)に代入して、新しい値に置き換えるコードです。どちらがよいかは好みではないでしょうか。ただし、「df.fillna('S')」のようにしてしまうと、元のDataFrameオブジェクトの全ての欠損値が'S'で補完されてしまうことには注意してください。もちろん、全ての欠損値をまとめて補完できるような値があれば、それでも構いませんが、そうではないことの方がきっと多いでしょう。
ここでinfoメソッドを呼び出してみましょう。
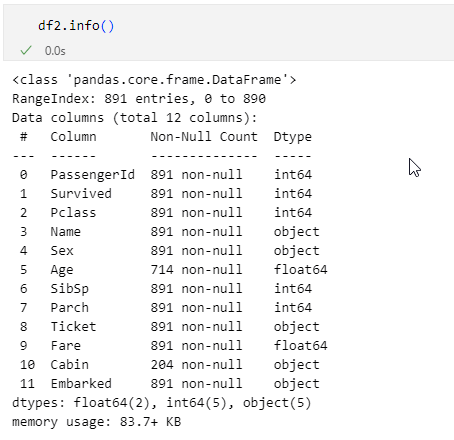 欠損値が補完されたので'Embarked'列の非欠損値の数が891になった
欠損値が補完されたので'Embarked'列の非欠損値の数が891になった「11 Embarked 891 non-null object 」とあることから、補完されたようですね。なお、元のdfオブジェクトの'Embarked'列で欠損値があった行は次のようにして調べられます。
nanrow = df[df['Embarked'].isnull()]
nanrow
このnanrowオブジェクトのindex値をdf2オブジェクトのloc属性に指定してやれば、's'が補完されたかどうかを確認できます。
df2.loc[nanrow.index]
実行結果を以下に示します。

'Age'列
'Age'列はもちろん年齢を格納している列です。先ほど見たときには欠損していないデータが714個(欠損しているデータが177個)ありました。'Cabin'列のように欠損しているデータがあまりにも多いともいえないので、これは何とか補完したいのですが、どうすればよいでしょうか。'Embarked'列は3つの乗船地の中で最頻値となる値を選びました。ここでは単術に算術平均を取ったもので補完することにします。
ただし、実務的には、まずは'Age'列のヒストグラムを作成するなどして、データの分布を確認することが重要です。理想的には中央に山がある正規分布の形が望ましいです。今回は図示しませんが、'Age'列のヒストグラムでは左に偏った分布が見られ、若年層が多いことが分かります。このような場合には、「平均値」を使うよりも「中央値」で補完する方が、より実際のデータを反映した結果になる可能性が高いです。平均値で補完すると、極端な値に引っ張られてデータ全体のバランスが崩れ、分析や機械学習の結果がゆがむ原因となることがあるので注意しましょう。
また、中央値や平均値以外にも、欠損値を補完する方法は幾つか考えられます。例えば、回帰分析などのアルゴリズムを用いて年齢を推定することも可能です。これにより、より精度の高い欠損値の補完が期待できます。
とはいえ、これは入門連載で欠損値を扱う一例ですから、まずは最もシンプルな「平均年齢で補完する方法」の例だけを示すことにしましょう。平均は次のようにして計算できます。
mean_age = df['Age'].mean()
print(mean_age) # 29.69911764705882
平均年齢を計算できたら、後は先ほどと同様です('Embarked'列の欠損値を補完した後のDataFrameオブジェクトはdf2に代入しているので、それを使っている点には注意してください)。
df3 = df2.fillna({'Age': mean_age})
#df3 = df2.copy()
#df3['Age'] = df3['Age'].fillna(mean_age)
df3.info()
上記コードの実行結果を以下に示します。
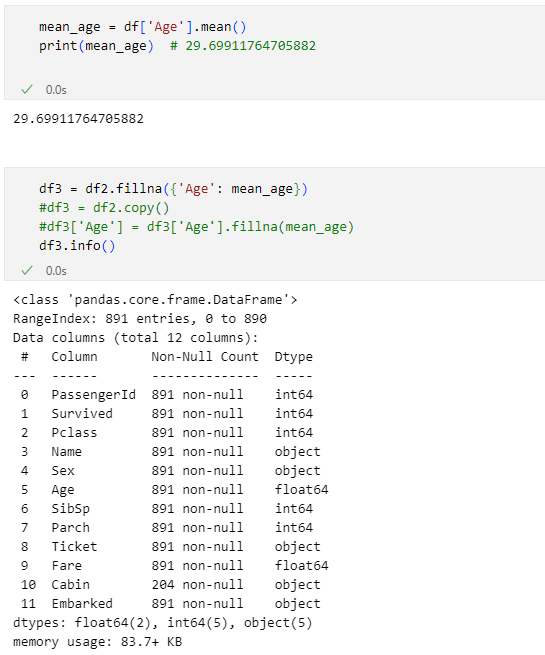 補完できた
補完できた後は欠損値が多数ある'Cabin'列と、この後は使用しないであろう列('PassengerId'列や'Name'列など)を削除すればよいでしょう。
列の削除
欠損値を含む列を削除するにはpandas.DataFrame.dropnaメソッドを使用します。これについては本連載の第9回「欠損値とその処理」の中で紹介しました。
ここでは削除方法を指定するhowパラメーターに'any'を、axisパラメーターに1を指定して、欠損値を含む列を全て削除するようにします(欠損値を補完した後のDataFrameオブジェクトは変数df3に代入されている点に注意)。
df4 = df3.dropna(how='any', axis=1)
df4.info()
このコードを実行すると次のようになります。
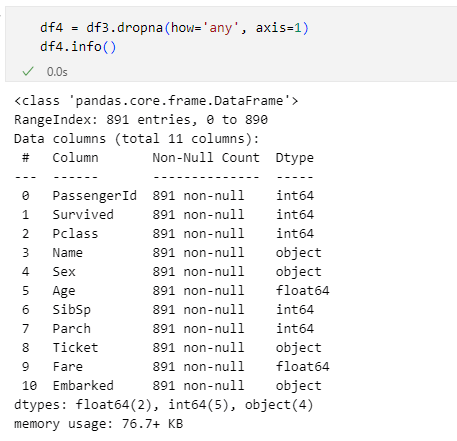 'Cabin'列が削除され、891行×11列のデータセットになった
'Cabin'列が削除され、891行×11列のデータセットになった特定の列を削除するには本連載の第6回「DataFrameに対して行や列を追加したり削除したりしてみよう」で紹介したpandas.DataFrame.dropメソッドを使用します。
ここでは以下の列を削除することにしました。
- 'PassengerId'列:各行に0始まりで振っただけのIDなので生死には関係ない
- 'Name'列:名前と生死に関係はなさそう
- 'Ticket'列:チケット番号と生死に関係はなさそう
本当は「関係なさそう」というだけで安易に削除するのは正しくないのでしょうが(運の強い名前があるかもしれませんし、チケット番号をよく精査すれば、生死との何らかの関係が見られるかもしれません)、ここではデータを加工する練習としてこれら3つの列を削除することにします。
削除する列はdropメソッドのcolumnsパラメーターに3つの列の列ラベルを指定します(あるいはlabelsパラメーターにそれらを指定して、axisパラメーターに1を指定)。
df5 = df4.drop(columns=['PassengerId', 'Name', 'Ticket'])
#df5 = df4.drop(labels=['PassengerId', 'Name', 'Ticket'], axis=1)
df5.info()
これにより次のように3つの列が削除されます。
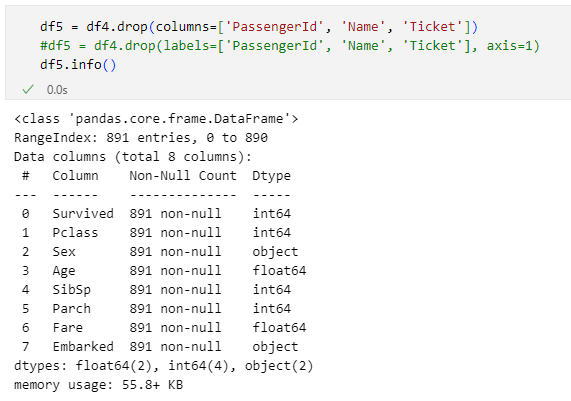 3つの列が削除され、891行×8列のデータセットができた
3つの列が削除され、891行×8列のデータセットができたここで上の画像の「Dtype列」に注目してください。'Sex'列と'Embarked'列が文字列(object型)になっていることが分かります。前回も述べましたが、プログラムで機械的にデータセットを処理したいという場合、文字列ではなく、数値データの方が便利です。こうしたデータを数値に変換するには幾つかの方法があります。
エンコーディング
性別('Sex'列)や乗船地('Embarked'列)のようなデータのことをカテゴリカルデータなどと呼ぶことがあります。男性と女性、サウサンプトンとシェルブールなどはそれらがあくまでも何らかのカテゴリー(グループ)を示すものであって、平均を取ったり、順序を付けたりはできません。もちろん、男性を0、女性を1のように数値データとして取り扱うことも可能ですが、1の方がエラいとか、2の方が大きいとか区別するものではありません。このようなデータは「名義尺度」を持つということもあります(名義とはあるデータと別のデータを区別する名前くらいの理解をすればよいでしょう)。
これに対して、'Pclass'列は旅客クラスを数値データです。この値が1なら1等、2なら2等、3なら3等という旅客クラスを表し、順序関係(大小関係)を持ちます。ただし、それらの値と値(例えば、1と2)が等間隔に並んだものというわけではありません。このような種類のデータは「順序尺度」を持つということがあります。順序尺度を持つデータもまたカテゴリカルデータの一種です。名義尺度と順序尺度を持つデータのことを「定性的なデータ」と呼ぶこともあります。'Pclass'列の1、2、3という値は'S'、'A'、'B'という文字列で表現可能なデータを数値に変換したモノだとも考えられますね。
今述べた定性的なデータと対になるのが「定量的なデータ」です。これは読んで字のごとく、量を表すものです。例えば、年齢('Age'列)や運賃('Fare'列)の値は量を表しているので定量的なデータです。定量的なデータも2種類に分けられます。1つは「間隔尺度」を持つもので、もう1つは「比率尺度」を持つものです。その違いは比率尺度を持つデータには原点0ともいえる点(値)が存在し、比率のような関係を持つことです(間隔尺度にはこうした特性はありません)。
例えば、摂氏0度は氷点(水が凝固して氷に変わる温度)として任意に定めたもので、絶対的な原点0とはいえません(対して、これ以上低い温度はなく、分子の運動エネルギーが0になる絶対零度は絶対的な原点0といってもよいかもしれません。つまり、絶対温度は比率尺度を持つといえるでしょう)。さらに摂氏20度は摂氏10度の倍の温度ではないので比率を求めることはできません。よって摂氏温度は間隔尺度を持ちますが、比率尺度ではないといえるでしょう。これに対して、体重は明確な原点0(体重0kg)があり、60kgの体重の1.5倍は90kgのような比例関係を持ちます。よって、体重は比率尺度を持つといえるでしょう。

難しい話は「社会人1年生から学ぶ、やさしいデータ分析」を読んでいただくとして、ここでは最初に出てきたカテゴリカルデータの'Sex'列と'Embarked'列を数値データに変換する方法を紹介しましょう。このような変換のことをエンコーディングと呼ぶことがあります。
カテゴリカルデータのエンコーディングには幾つかの種類があります。代表的なものを挙げましょう。
- Labelエンコーディング
- Ordinalエンコーディング
- One-Hotエンコーディング
Labelエンコーディングはカテゴリカルデータを単純に数値に置き換えるものです。例えば、'Sex'列の'male'を0に、'female'を1にエンコーディングするといったことが考えられます。これは単純でよいのですが、エンコーディング後の数値が自分の意図していない意味を持ってしまう可能性がある点には注意が必要です。
Ordinalエンコーディングはカテゴリカルデータが順序尺度を持つ場合に適しています。先ほどの'Pclass'列の例え話を続けると、この列の値が'S'、'A'、'B'でそれぞれ1等、2等、3等の旅客クラスを表していたとすると、そこには順序があるので(1等>2等>3等)、そのデータを順序に応じた整数値にエンコーディングできるでしょう。
One-Hotエンコーディングは名義尺度を持つカテゴリカルデータをエンコーディングするのに向いています。'Sex'列を例にとれば2つの値に対応する新しい列として'male'列と'female'列を新しく作成し、'Sex'列の値が'male'のデータは'male'列のデータを1に、'female'列の値を0にするといったことをします(逆も同様)。ただし、'Sex'列や'Embarked'列のように値の種類が少なければ列が大きく増えることはありませんが、種類が多いとそれに伴って列数が増えてしまう可能性があります。
ここでは2つの列をOne-Hotエンコーディングしてみることにしましょう。これにはpandas.get_dummies関数を使います。
pandas.get_dummies関数
pandas.get_dummies(data, prefix=None, prefix_sep='_', columns=None, dtype=None)
カテゴリカルデータをダミー変数(詳しくは後述する)に変換したり、One-Hotエンコーディングしたりできる。一部のパラメーターを以下に示す。全てのパラメーターについてはpandasのドキュメント「pandas.get_dummies」を参照のこと。
- data:変換元のDataFrameオブジェクト
- prefix:変換後のダミー変数の列に付加するプレフィクス。指定しなかった場合は元の列ラベルが付加される
- prefix_sep:プレフィクスの後に付加されるセパレーター
- columns:エンコードしたい列をリストで指定する
- drop_first:変換後のダミー変数の1列目を削除するか(True)どうか(False)。デフォルトはFalse
- dtype:新しく作成する列のデータ型。省略した場合はブーリアン値(True/False)
なお、ダミー変数とは、カテゴリカルデータを0または1の値に変換した変数のことです。ダミー変数化は、One-Hotエンコーディングの一種と見なせます。主な違いは、ダミー変数化では通常、複数のカテゴリーのうち1つを基準として残りを変換する点が特徴です(drop_firstパラメーターをTrueにした状態)。例えば'Sex'列を変換する場合、'female'を0、'male'を1とすることで、片方の変数(例えば'male'列)だけを追加します。これにより、必要な情報を効率的に保持できます。また、列数を減らすことで、回帰分析の多重共線性を防ぐメリットもあります。
DataFrameオブジェクトのメソッドではなく関数である点には注意してください。'Sex'列と'Embarked'列をOne-Hotエンコーディングして、1と0にしたいのであれば、次のようなコードになるでしょう。
df6 = pd.get_dummies(df5, columns=['Sex', 'Embarked'], dtype=int)
df6
ここではpandas.get_dummies関数に不要な列の削除までを行った結果(df5)を渡し、columnsパラメーターには'Sex'列と'Embarked'列を指定して、dtypeパラメーターにはintを指定しました。以下が実行結果です。
 'Sex'列がなくなり'Sex_female'列と'Sex_male'列が、'Embarked'列がなくなり'Embarked_C'列と'Embarked_Q'列と'Embarked_S'列が作成された
'Sex'列がなくなり'Sex_female'列と'Sex_male'列が、'Embarked'列がなくなり'Embarked_C'列と'Embarked_Q'列と'Embarked_S'列が作成された'Sex'列がなくなりその代わりに'Sex_female'列と'Sex_male'列が作成され、同様に'Embarked'列の代わりに'Embarked_C'列と'Embarked_Q'列と'Embarked_S'列が作成されたことが分かります。
新しくできたDataFrameオブジェクトでinfoメソッドを呼び出したところが以下の画像です。
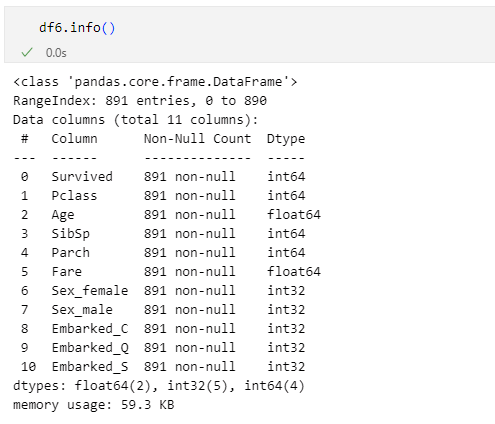 全ての列の値が数値データ化された
全ての列の値が数値データ化された全ての列のデータが整数または浮動小数点型の値になりました。これなら機械的な処理もうまくやれそうです。というところで、今回は終わりです。前処理でやらなければならないこと(データのスケーリングなど)がもう少し残っています。
ただし、その前に今回の成果をCSVファイルに保存しておきましょう。
df6.to_csv('titanic_cleaned.csv', index=False)
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。