制御構造としての例外:いまから始めるJava(13)
例外オブジェクトの生成
前回「エラーに対処するプログラムを書く」は予期しないエラーに対処する方法として、Javaの仕組みである例外を紹介しました。復習をかねて、指定したURLからデータを読み込んで画面に表示するプログラムを考えてみます。
| URLからデータを読み込んで画面に表示 |
import java.net.*; |
このプログラム本来の処理は、コマンドライン引数として渡されたURLからHTMLファイルを取得し、その内容を画面に表示することです。しかし、URLが引数として指定されていなかったり、指定されていても書式が間違っていたり、存在しないURLが引数として指定されるかもしれません。例えば、URLが引数として指定されていない場合の処理をプログラムの冒頭で以下のように記述してもいいはずです。
public class ShowHTML { |
この方法の問題点は、HTMLファイルを取得してその内容を画面に表示するというプログラム本来の処理が記述されているブロックに、プログラムを中断するときの処理が記述されていることです。また、プログラムの使い方はURLの書式が無効だったときにも表示するので、同じ内容の語句を表示するためのコードを別々の場所に記述することになり、効率的ではありません。そこで初めに紹介したプログラムでは、引数が指定されなかったときに「throw new MalformedURLException()」という文を実行し、MalformedURLException型のオブジェクトを発生させています。例外もオブジェクトですので、プログラマが手動で生成できるのです。このようにすることで、引数として渡されたときの処理と、URL型のオブジェクトがURLを解釈できなかったときの処理を1つのcatchブロックで処理しています。従って、このプログラム全体の大まかな流れは以下のようになります。

try〜catch〜finallyという例外処理用の文が制御構造を記述する制御文としての働きを持つことは、前回簡単に説明しました。例えば、引数が指定されていなかったときに実行される「throw new MalformedURLException();」という文により、プログラムの制御は「catch( MalformedURLException e )」以下の例外処理ブロックに移ります。try〜catch〜を使うと、ちょうどif〜elseで条件分岐させるように、特定の処理ごとにブロックを分けられるわけです。さらにこのプログラムでは、取得したHTML文書も例外発生時の説明文も同じ文字列としてStringBuffer型のオブジェクトであるresultに格納しています。もちろん、例外ごとにprintln()で画面に表示することもできます。しかし、例外が起きても起きなくても最後のfinallyブロックで処理の結果を表示することにより、このプログラム全体が最終的に何かを表示することを目的にしていることが明確になったと思います。
例外を親メソッドに任せる
せっかくURLからHTML文書を取得するプログラムを作ったので、以前に作ったHTMLDocumentクラスに、指定したURLからHTML文書を取得するためのメソッドを追加してみましょう。しかし、URLからHTML文書を取得するときに起こり得る例外はどうしたらいいのでしょうか。HTMLDocumentというクラスはHTML文書を格納したり加工したりするためにあるわけですから、例外発生時にHTMLDocumentのインスタンスが勝手に「例外発生」などと画面に表示するのは困ります。
そこでJavaには、メソッドの定義にthrowsというキーワードを付けることで、あるメソッド内で発生した例外をそのメソッドを呼び出した親メソッドに転送するという機能が用意されています。別のいい方をすると、例えばURLクラスのメソッドであるgetContent()が発生させるIOExceptionの例外も、getContent()が内部で処理せずに呼び出し元に転送しているからこそ、catchブロックによって捕捉しなければならないわけです。ただし、クラスのメソッドで発生した例外を呼び出し元のメソッドで捕捉しているわけですから、制御としてはちょっと複雑になります。breakやcontinueといった通常の制御文であれば、1つ外側のブロックに制御が移るだけですが、throwsによって例外が転送される場合はreturnと書かれていないのに、制御がいきなり親メソッドに移ってしまうからです。
以上を踏まえたうえでHTMLDocument型を書き直してみると、以下のようになりました。
| HTMLDocumentクラスの改良(パッケージとして登録する) |
package jp.co.atmarkit.java; |
元のHTMLDocumentクラスでは、HTML文書をString型で保持していましたが、今回はStringBuffer型で保持することにしました。また、指定したURLからHTML文書を取得するloadFromURL()というメソッドを追加しています。loadFromURL()はMalformedURLExceptionという例外を発生させますので、呼び出し元がこの例外を捕捉しなければなりません。さらに、取得したHTML文書のタグを除いたテキスト部分を取得するgetPlainText()というメソッドを用意しました。
では、さっそく新しいHTMLDocumentを使ったプログラムを書いてみましょう。
| 指定したURLのテキストを表示するプログラム |
import jp.co.atmarkit.java.HTMLDocument; |
プログラムを実行すると以下のような結果が得られます。
C:\>javac ShowTextFromURL.java |
HTML文書をURLから取得したり、HTML文書を解析してテキスト部分を取り出す機能がHTMLDocument型のメソッドとして用意されたため、プログラムはだいぶシンプルなものになりました。操作する対象となるデータと、データそのものをクラスとしてまとめてあるので、HTMLDocument型を使うプログラマは、HTML文書をどうやって取得しているのか、取得したHTML文書からどうやってテキスト部分を取り出しているのか、知っている必要はなくなりました。また、プログラムはHTML文書から取り出したテキストをセットするブロック、例外時のエラーメッセージをセットするブロック、結果を出力するブロックという3つに分割されており、何をしているのか誰が見ても理解できます。
例外の種類
例外を発生させるメソッドを使った場合はtry〜catchで捕捉しないとコンパイル時にエラーになります。従って、URL型のgetContent ()やHTMLDocument型のloadFromURL()のように、例外を発生させるメソッドを使う場合は必ずtry〜catchを使うことになりますが、はじめのうちはいちいちtryブロック内に本来の処理、catchブロックに例外時の処理を記述することが面倒に感じるものです。しかし見方を変えれば、コンパイルエラーを発生させないために、Javaプログラマはtry〜catch〜finallyを使ってプログラムを(1)本来の処理、(2)例外処理、(3)最後の処理に分割して書くように仕向けられているわけです。
ただし、すべての例外がtry〜catchで捕捉しないとコンパイル時にエラーになるわけではありません。コンパイル時にチェックされる例外と、チェックされない例外があるのです。試しに以下のプログラムをコンパイルして実行してみましょう。
| 配列の添え字はコンパイル時にチェックされない |
public class ExceptionWithoutCheck { |
実行すると以下のような結果が得られます。
C:\>javac ExceptionWithoutCheck.java |
要素の数が10個の配列に対して、インデックス10000の要素にアクセスしようとしていますので、実行時には当然ArrayIndexOutOfBoundsExceptionという例外が発生します。しかし、プログラムで例外を捕捉していないのにコンパイル時にエラーになりません。
実は、MalformedURLExceptionのように、コンパイル時に捕捉しないとエラーになる例外と、ArrayIndexOutOfBoundsExceptionのように、コンパイル時に捕捉しなくてもエラーにならない例外の違いは、第一にそれぞれの例外のスーパークラスの違いです。
すでに説明したように、例外はオブジェクトです。そして、すべての例外はjava.lang.Throwableのサブクラスのインスタンスです。これを図にすると以下のようになります。
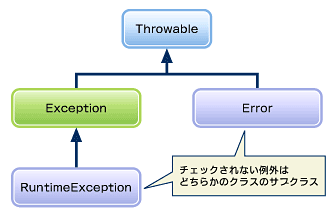
すべての例外のスーパークラスであるThrowableを継承しているのが、ExceptionとErrorという2つのサブクラスです。このうちMalformedURLExceptionのように、必ず捕捉しなければならない例外の直接または間接的なスーパークラスになっているのがExceptionです。ただし、ExceptionのサブクラスであるRuntimeExceptionを継承しているArrayIndexOutOfBoundsExceptionのような例外は、捕捉しなくてもコンパイル時にエラーになりません。両者の違いはやや分かりにくいのですが、大ざっぱにいうとExceptionのサブクラスのものは、ファイルが存在しない場合やURLが不正である場合など、実行時にしか判断できない種類の例外です。別のいい方をすると、Exceptionのサブクラスになっている例外は、回復し得る例外ということになります。
それに対してArrayIndexOutOfBoundsExceptionのように、RuntimeExceptionのサブクラスである例外は、プログラムを注意して作れば回避可能な例外です。また、RuntimeExceptionを継承した例外はメソッドごとにいちいち捕捉していたらキリがないので、捕捉はできるがプログラマの責任でなるべく回避すべき例外が含まれています。
一方のErrorはExceptionよりも重大な例外のスーパークラスです。例えば、Javaのバーチャルマシンが壊れたことを示すVirtualMachineErrorのように、プログラム内で捕捉しても回復のしようがない例外はErrorのサブクラスになります。
従って、なんでもtry〜catch〜finallyの例外機構を使って書けばよいというわけではありません。要素数を超える配列の要素にアクセスしないようなコードは、本来の処理の中に含めるべきなのです。catchブロックは、あくまでもプログラム本来の目的とは外れた処理、finallyブロックはいずれにしても実行すべき処理、というように明確に使い分けるようにします。
次回はいよいよ最終回です。Javaのクラスを完全にマスターするためには避けて通れない「インターフェイス(interface)」について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。