Hadoopの死角、COBOLバッチ処理の並列化:現場にキく、Webシステムの問題解決ノウハウ(8)
本連載は、日立製作所が提供するアプリケーションサーバ「Cosminexus」の開発担当者へのインタビューを通じて、Webシステムにおける、さまざまな問題/トラブルの解決に効くノウハウや注意点を紹介していく。現在起きている問題の解決や、今後の開発のご参考に(編集部)
クラウドで可能になった大量データ処理とバッチ処理
クラウド・コンピューティングを前提として、多数のサーバを使い大量のデータ処理をするための手法として、「MapReduce」や、MapReduceをJavaで実現するフレームワーク「Hadoop」に代表される分散並列処理に注目が集まっている。
多数のサーバを使い計算処理を並列化し、それまで非現実的と思われていた大量の計算処理も可能とする手法で、まさに「クラウド時代の技術」といえるだろう。
そして、企業内コンピューティングにおいても、「情報爆発」「ビッグデータ(Big Data)」と呼ばれるほどにデータ量の増加が進んでいる。その一方で、何十年にも渡って使い続けてきたCOBOLなどによるバッチ処理プログラムが毎日動いている現場も数多い。
今回は、メインフレーム時代の遺産といえるCOBOLバッチに悩む現場の話と、“単純な並列化”に潜む罠、そして、その回避策を紹介しよう。
企業内コンピューティング最後のブラックボックス
バッチ処理は、企業内コンピューティングの急所だ。いわゆる“レガシー・マイグレーション”の進展で、オンライン処理をUNIXやLinuxの上に再構築している場合でも、「日次バッチ」では古いCOBOLプログラムをそのまま使い続けている現場は多い。
「COBOLによるバッチ処理プログラムをJavaに書き直したとしても、工数に見合うメリットが得られない場合が多いからです」(日立製作所 IT基盤ソフトウェア本部 DB設計部 主任技師 丸山剛男 氏)。
COBOLプログラムをJavaに書き直しても、バッチ処理の性質やJavaのJITコンパイラの特性から、従来よりも高速化するとは限らない。むしろ、性能を出すのに苦労する場合さえある。再構築とテストの工数を掛けるメリットが見い出しにくいという現状がある。バッチ処理の世界は、何十年も使われてきた、いわば最後まで残った“ブラックボックス”が生き続けている領域なのだ。
だが、企業内システムが扱うデータ量は爆発的に増えている。処理すべきデータがあるのにバッチ処理のスピードが追い付かない事態が生じている。昼間のシステム稼働に必要なデータを夜間バッチで生成している場合、朝までに終わる分量のデータしか投入できず、多くのデータを捨てなければならない場合もあるという。
このような企業内コンピューティングの現場のニーズを満たすために、さまざまな方法があるが、例えば“グリッドバッチソリューション”(以下、グリッドバッチ)という概念がある。これは、既存のバッチ処理プログラムを書き直さずに並列処理することを目的としている。
既存のバッチ処理プログラムの入力をMapReduce?
“グリッドバッチ”の狙いは単純だ。既存のバッチ処理プログラムには手を加えず、その入力と出力に注目する。プログラムに与えるデータをうまく分割し、複数のサーバ上で並列処理させ、プログラムの出力を再結合する。
クラウドで注目を浴びているMapReduceアルゴリズムは処理の分散と集約の仕組みを提供する点がポイントだが、“グリッドバッチ”も、データの分散と集約の仕組みを提供する。もちろん“グリッドバッチ”はMapReduceと直接の関係はない。ただ、大量データ処理を並列処理により高速化するという目的は共通している。
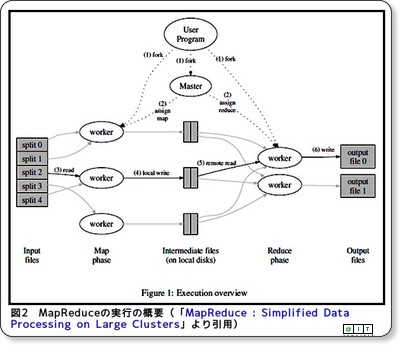
また、障害を起こしたサーバを自動的に除外する仕組みも取り入れ、高可用性も実現している。何十年も使い続けてきたバッチ処理プログラムであっても、クラウド環境を活用したコンピューティングが可能となるのだ。
“グリッドバッチ”は、バッチジョブ分散実行制御用のミドルウェア製品を軸として、ジョブスケジューラやアプリケーション実行制御ソフトウェア、共有ファイル・システム、そしてデータベースを組み合わせて使う。
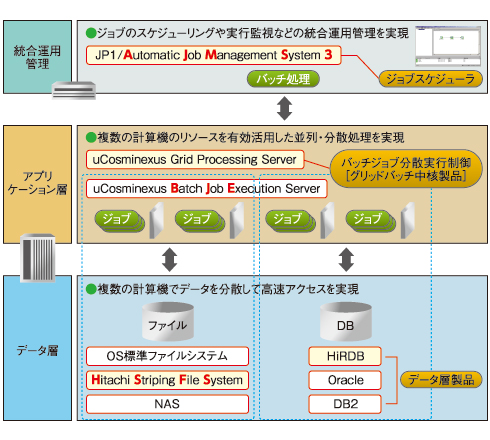 図1 グリッドバッチの構成
図1 グリッドバッチの構成“グリッドバッチ”で並列化の対象となるバッチ処理プログラムは、どんな言語で書かれていてもよい。COBOLで書かれていても、それ以外の言語で書かれていても(例えばFORTRANだったとしても)いい。ただし、入力データが分割不可能な場合は適さない。例えば、ファイル全体を何度も読み書きするようなプログラムは並列化には向かない。
適用業務としては「銀行の振り込み一括処理」「フランチャイズチェーンの売り上げ・在庫管理の月次バッチ」といったミッション・クリティカルな分野も想定している。
並列化の規模は、最も少ない場合では「2台でも高速化のメリットはある」(IT基盤ソフトウェア本部 第1基盤ソフト設計部 主任技師 渡辺和彦氏)という。そして、多数のサーバとストレージを活用した環境にも適用できる。例えば、プライベートクラウドを運用しているが夜間にはリソースが余っている場合があるとしよう。このとき、余っているリソースを“グリッドバッチ”の実行に使う運用も可能だ。
メインフレームのシステムを使う際に、意外なところで問題となることもある。それは、文字コードへの対応だ。「文字コードを変換すると、ソート順が変わってしまい、処理を追加しなければならない場合も出てくる」(丸山氏)という。例えば日立製作所製メインフレームで使われる日本語文字コードは「EBCDIK」だが、“グリッドバッチ”では、この文字コードをサポートしているデータベース「HiRDB」を使うことで、ソート順が変わるのを防いでいる。
“並列処理での高速化”にもボトルネックはある
この“グリッドバッチ”の技術上のハイライトは、並列処理したデータを集約する仕組みだ。並列処理で高速化するといっても、低速のネットワークやディスクを使いデータを集約するのでは、ネットワーク帯域やディスクの書き込み(I/O)速度がボトルネックとなってしまう。
解決するにはさまざまな方法が考えられるが、例えば“グリッドバッチ”では、共有ファイル・システム「HSFS」を利用し、以下の形で高速化を実現している。
- 各サーバから共有ストレージに対して直接ファイバチャネルで接続するアーキテクチャに対応する
- インメモリのファイルシステムおよびデータベースを利用する
ファイバチャネルは光ファイバを使う高速伝送の技術で、10Gbps以上の帯域を持ち、スーパーコンピュータ分野で実績がある。HSFSはスーパーコンピュータ分野向けに開発してきた技術を、企業内コンピューティング向けに活用したものだ。
このような環境が、どのように“並列処理による高速化”に効いてくるのだろうか。
「ファイバチャネルで各サーバと共有ストレージを直接結ぶことで、ネットワーク帯域がボトルネックとなることを避けています。通常、データを分割する処理の性能は、1台のサーバの速度で上限が決まってしまいます。しかし、共有ストレージにデータを置いて使うことにより、分割したデータを、それぞれのサーバまで転送する時間を発生させずに済んでいます」(プラットフォームソフトウェア本部 第1プラットフォームソフトウェア設計部 主任技師 岩倉義之氏)。
また並列実行した後のデータを集約する部分では、「インメモリのファイルシステムを使うことで、ディスクI/Oの速度がボトルネックとなることを避けている」(岩倉氏)という。
“グリッドバッチ”とHadoopの違いとは
最後に、“グリッドバッチ”とHadoopとは、どのような違いがあるのか比較してみよう。
| 分類 | 項目 | グリッドバッチ | Hadoop |
|---|---|---|---|
| 設計開発 | ・データ分割設計 ・アプリケーション開発 |
・業務に合わせて分割可能 ・既存COBOLアプリに対応 |
・設計の必要はない(ハッシュ分割) ・フレームワークで再構築 |
| 実行 | ・処理 ・異常対応 |
・厳密な排他処理が可能 ・異常検知や再実行保証 |
・整合性保証はなく、更新は苦手、参照系は優位 ・異常データは飛ばして処理(HDFSの場合) |
| 運用 | ・データ分散配置 ・運用管理 |
・スクリプトなどで配置 ・JP1の運用が容易 |
・コマンドで自動配置 ・選択肢は広いが作り込みが必要 |
| 表 “グリッドバッチ”とHadoopの違い | |||
「まったくゼロから新規にプログラムを開発する場合には、Hadoopを使うのもいいでしょう。ただし、既存のCOBOL言語によるバッチ処理プログラム、あるいは他の言語で記述されたプログラムを、なるべく手を加えずに並列化したいという要望には向いてないでしょう」(丸山氏)。
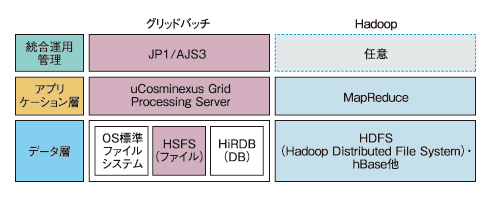 図2 グリッドバッチ”とHadoopのアーキテクチャの違い
図2 グリッドバッチ”とHadoopのアーキテクチャの違い以上見てきたように、“グリッドバッチ”のコンセプトは、古いプログラムを最新のクラウド環境で活用し、いままで実現できなかった大量データ処理を実現するというものだ。企業内に眠っている大量のデータを有用に活用するなどの用途で有効かと思われる。現在Linux版を提供中だが、Windows版の計画もあるとのことだ。
関連記事
- クラウドで再注目の「分散コンピューティング」の常識
- いま再注目の分散処理技術
- Javaバッチ処理は本当に業務で“使える”の?
- 次世代を予感させるグリッドコンピューティング
- スキルアップのための分散オブジェクト入門
- 第1回 Webアプリの問題点を「見える化」する7つ道具
- 第2回 “Stop the World”を防ぐコンカレントGCとは?
- 第3回 【実録ドキュメント】そのログ本当に必要ですか?
- 第4回 DBアクセスのトラブルは終盤で発覚しがち……
- 第5回 OutOfMemoryエラー発生!? GCがあるのに、なぜ?
- 第6回 【真夏の夜のミステリー】Tomcatを殺したのは誰だ?
- 第7回 【トラブル大捜査線】失われたコネクションを追え!
- 第8回 肥え続けるTomcatと胃を痛めるトラブルハッカー
- 第9回 JavaのGC頻度に惑わされた年末年始の苦いメモリ
- 第10回 ThreadとHashMapに潜む無限回廊は実に面白い?
- 第11回 スレッドダンプの森で覚えた死のロックへの違和感
- 第12回 アプリ開発でも、よ?く考えよう。キャッシュは大事だよ
- 第13回 DB操作の“壁”を壊すJPAが起こした「赤壁の戦い」
- 第14回 数百キロのコードでブルー - ドクターTomcat緊急救命
- 第1回 クラスタ化すると遅くなる?
- 第2回 キャッシュが性能劣化をもたらす謎を解く
- 第3回 クラスタは何台までOK?
- 第4回 マルチスレッドのいたずらに注意
- 第5回 クラスタによるアプリケーションの動的アップデート
- 第6回 APサーバからの応答がなくなった、なぜ?
- 第7回 低負荷なのにCPU使用率が100%?
- 第8回 文字化け“???”の法則とその防止策
- 第9回 メモリは足りているのに“OutOfMemory”のなぞ
- 第10回 レスポンスキャッシュでパフォーマンス向上
- 第11回 JDBC接続を高速化?PreparedCacheの活用
- 第12回 ブラウザキャッシュでパフォーマンス向上
- 第13回 ファイルアップロード/ダウンロードに潜むわな
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。