Java EEサーバからレスポンス返らず。何から調べる?:現場にキく、Webシステムの問題解決ノウハウ(1)(1/2 ページ)
本連載は、日立製作所が提供するアプリケーションサーバ「Cosminexus」の開発担当者へのインタビューを通じて、Webシステムにおける、さまざまな問題/トラブルの解決に効くノウハウや注意点を紹介していく。現在起きている問題の解決や、今後の開発のご参考に(編集部)
今回は、Webシステムの代表的な問題の1つとして、Java EE(J2EE)サーバのプロセスのハングアップが発生した場合を取り上げる。こういった場合、IT情シス・SE/プログラマがどういった流れで問題解決をしていくべきか。その手順について話をうかがったので、その内容を紹介する。
現象の見え方
今回は、以下の問題についての話だ。
外部からのJava EEサーバへのリクエスト(要求)がいつまでも完了しない。レスポンス(応答)が返らないように見える
問題解決への流れ
通常のプロセスハングアップが発生した場合、設定によっては、Java EEサーバのハングアップを検知して、自動的に障害資料採取およびサーバの再起動が実施される。しかし、このような設定を行っていない場合は、どうすればいいのだろうか。手動で障害資料を取得してから、サーバの再起動を行う必要がある。
プロセスハングアップ時に必要な障害資料は、OSの統計情報やJava EEサーバのログ・トレース、スレッドダンプだ。
スレッドダンプ
特に、スレッドダンプはハングアップしたモジュールの特定に有効だ。逆に、スレッドダンプをサーバプロセスの停止前に取得しておかないと、情報が不足して原因究明に手間取ることがあるので注意が必要となる。ハングアップしたモジュールの特定には、時系列での比較が有効な場合が多いため、複数回スレッドダンプを取得するとよい。およそ2〜3秒おきに10回ほど取得すると、正確な解析が可能になるという。
取得した障害資料を基に、原因を切り分ける。プロセスハングアップの場合、推定原因を定め、そこからハングアップの原因個所を絞り込んでいくことになる。スレッドダンプの取り方などの詳細は、以下の記事を参照してほしい。


CPU利用率
障害資料の中で、最初に判断基準として利用するのはOSの統計情報であるCPU利用率だ。
プロセスがハングアップした場合、下記の3つが原因として考えられるため、推定原因を絞り込む必要がある。
CPU利用率が100%に近い場合には無限ループや再帰呼び出しが発生している可能性があり、0%に近い場合にはバックプロセス無応答、またはデッドロックが発生している可能性が高いと判断するのが定石だ。
ログ・トレース
次に、Java EEサーバのログ・トレースを参照して、異常に時間がかかっている処理を割り出す。ハングアップ個所がある程度絞り込めた後に、推定原因を基にスレッドダンプを解析して障害の原因となったモジュールを特定する。
スレッドダンプからモジュールが特定できた場合には、開発元に調査を依頼するが、ハングアップ個所がネイティブメソッドの場合には、メモリダンプの解析を実施してモジュールを特定した後に、開発元に調査を依頼する。
障害切り分けフロー
これらの手順を示したものが下図のフロー・チャートだ。
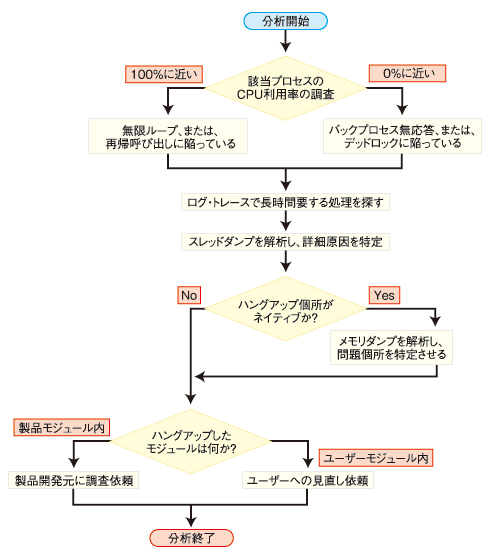 図 障害切り分けフロー
図 障害切り分けフローこの中で、障害原因切り分けのポイントとなるのは、ログ・トレースとスレッドダンプの解析だ。解析方法について、以降で細かく説明しよう。
ログ・トレースの解析
スレッドダンプの解析前に、ログ・トレースを確認して、どこの処理で問題が発生しているのかを割り出すことが必要だ。Java EEサーバのログ・トレースを確認することで、処理がどこまで進んでいるのか、実行時間が長い処理はどの処理なのかを把握できる。
実際に問題となった処理を確認してからスレッドダンプを解析することで、正確で迅速に原因が切り分けられるのだ。
ここでは、リクエストごとに処理シーケンスを把握して、特定のプロセスで異常に処理時間が長くなっている個所を探すこととなる。場合によっては、リクエストはプロセスをまたがることもあるため、ログとログとの付き合わせが必要だ。
なお、日立製作所のCosminexusでは、追尾性の良いトレースとして「性能解析トレース」機能が用意されている。この機能では、リクエストごとにユニークな識別子を付与し、機能ポイントごとにログが出力され、データベースのコネクションIDも情報として出力するという。これにより、問題発生時のクライアントからデータベースサーバまでのリクエストの流れを一貫して把握できるため、どの処理でハングアップが発生しているのか特定しやすくなる。
ハングアップしている処理の目安を付けた後は、スレッドダンプの解析に移る。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。