現実のXML文書を見る:XMLを学ぼう(3)
今回は実際にさまざまなXML文書を見ていただこう。プレーンテキストとXMLではどのように違うのか、CSV形式のデータをXMLで表すとどのように表現できるのか。具体的な例を見ていただくと、XMLに対するイメージがわいてくるはずだ。
実際のXML文書を見聞きしよう
XMLは、本質がメタ言語であるために「あれもできます、これもできます」という話に流れやすい。そのため、初心者がXMLに触れたとき、雲をつかむような話なってしまい、具体的なイメージが描けないことも多いだろう。
そこで、今回は、いくつかの実際に存在するXML文書を見ることで、具体的なイメージをつかむ手助けとしてみたい。
■ハローワールド!
プログラム言語の世界では、最初に“Hello World!”という文字列を出力する方法を解説することが多い。
これにならって、XMLで“Hello World!”という文字列を記述する方法をこの連載の第1回目で説明した。そのコードのみを以下に再掲する(これ以後、リストの行頭の数字とコロン記号(:)は説明の便宜上付けている行番号で、コードの一部ではない)。
1: <?xml version='1.0' encoding='UTF-8'?> 2: <doc><p>Hello! World!</p></doc>
このXML文書は非常にシンプルで、最小限度のXML文書がどこまで小さくなれるかについて、具体的なイメージを与えてくれる。構造と言えるほどの構造もなく、一目瞭然である。ただ文書全体を包み込むルート要素としての<doc>要素と、段落を示す<p>要素があるだけである。<doc>要素の子として<p>要素があり、その子としてHello! World!という文字列がある、というシンプルな階層構造があるだけである。しかし、実際に世の中で使用されるXML文書は、これほど短くもないし、シンプルでもない。
■最小のXML文書
ちなみに、余談ではあるが、ぎりぎりまで小さくした世界最小のXML文書は、おそらく、以下のようなコードだろう。なお、要素名のaは要素名に使える文字ならどんな文字でも構わない。
1: <a/>
つまり、XMLにおいて省略することが絶対に許されないものは、ルート要素だけであり、ルート要素の内容が空であるならば、<a></a>と<a/>は等価であるため、ただ<a/>と書くだけで、XML文書として成立する。
プレーンテキストをXMLで記述する
筆者が作成したtxt2xmlというツールがある。これは、プレーンテキストをXML文書に変換するツールである。これは、コマンドプロンプトで実行するツールで、初心者が簡単に使えるものではないので、このツールそのものを使うことはお勧めしない。ここでは、このツールが、プレーンテキストにどのような構造を与えているかを見ることで、XML文書というものの性格の一端をつかむ手助けとしていただきたい。
■DTD付きのXML文書
まず、以下のような3行のプレーンテキストがあったとしよう。
1: 今日もFFをやった。 2: でも、そろそろ寝ようと思った時に限って、モーグリが出てこないのはなぜだろう。 3: 1日中仕事を忘れてFFにひたっていられれば幸せなのにね。
これを、txt2xml (-pモード使用) でXML文書に変換した結果が以下の通りになる。見てお分かりの通り、爆発的に情報量が増えている。
1: <?xml version='1.0'?> 2: <!DOCTYPE document [ 3: <!ENTITY lt "<"> 4: <!ENTITY gt ">"> 5: <!ENTITY amp "&"> 6: <!ENTITY apos "'"> 7: <!ENTITY quot """> 8: <!ELEMENT fileName (#PCDATA)> 9: <!ELEMENT timeLastAccess (#PCDATA)> 10: <!ELEMENT timeCreation (#PCDATA)> 11: <!ELEMENT timeModify (#PCDATA)> 12: <!ELEMENT fileSize (#PCDATA)> 13: <!ELEMENT head (fileName|timeLastAccess|timeCreation|timeModify|fileSize)*> 14: <!ELEMENT p (#PCDATA)> 15: <!ELEMENT document (head,(p*))> 16: ]> 17: <document> 18: <head> 19: <fileName>delme.txt</fileName> 20: <timeLastAccess>Sun Jul 16 16:50:05 2000</timeLastAccess> 21: <timeCreation>Wed Apr 05 17:12:46 2000</timeCreation> 22: <timeModify>Sun Jul 16 16:48:56 2000</timeModify> 23: <fileSize>170</fileSize> 24: </head> 25: <p> 今日もFFをやった。</p> 26: <p> でも、そろそろ寝ようと思った時に限って、モーグリが出てこないのはなぜだろう。</p> 27: <p> 1日中仕事を忘れてFFに浸っていられれば幸せなのにね。</p> 28: </document>
これについて解説する。まず1行目は、お馴染みのXML宣言である。
2〜16行目は、DTD(Document Type Definition)が埋め込まれている。これは、この文書に含まれる情報本体の許される書式を明示的に書いたものである。XML文書の外側に置いて参照することが多いが、この例では内部に埋め込む形を選択している。2行目の<!DOCTYPE ... [ がDTDの宣言の開始を示している。そして、16行目の ]>がDTDの終わりを示している。
さらにDTDを深く見ていくと、3〜7行目は、XML文書のお約束の定義となっている。これは、XMLのマークアップで特殊な意味を持つ記号と等価の実体の定義である。この定義によって、<記号を記述する際に、<と記述できるようになるのである(ただし、DTDのない整形式のXML文書もありえるので、この定義はなくても、機能は有効である)。
8〜15行目は、要素の並び順を制約するために記述されているものである。これによって、定義されていない要素名を書いたり、許されない順番で要素を記述したときに、それをエラーとして判定することが可能となる。
このXML文書にDTDが埋め込まれているのは、伝送の途中で化けたり壊れたりした場合、それをある程度自動的に検出するためである。つまり、文書本体をDTDをワンセットのファイルに収めることで、本来は両者が無矛盾であると考えられる。それが、通信の結果の受取側でチェックしたときにエラーが出るようであれば、伝送の途中で壊れたと考えられるわけである。
さて、その次の17行目以降が、文書の本体である。<document>要素が、この文書のルート要素である。その次にすぐ文書本体が始まると思いきや、次には元のファイルにはない情報がつぎつぎと埋め込まれている。<head>要素は、文書のヘッダー情報を付加するために用意されている。この中には、元ファイルのファイル名やタイムスタンプなどの情報が保存されている。このような情報がわざわざ保存されているのは、プレーンテキストをXMLに変換して何かの処理を行ってから、またプレーンテキストに戻すことを配慮しているためである。
ここでは、元ファイルのファイル名として<fileName>要素、最終アクセスの日付時刻として<timeLastAccess>要素、ファイルの作成日付時刻として<timeCreation>要素、最後に変更された日付時刻として<timeModify>要素、元ファイルのファイルサイズとして<fileSize>要素が記述されている。これらの情報は、あれば便利ということで含まれているもので、必ずこれを使って処理しなければならないというものではない。
さて、34行目に<head>の閉じタグが出現し、やっとヘッダーが終わる。そして、35〜37行目が、もともとのプレーンテキストに含まれていた情報が出現する。元データの1行は1段落と見なされ、<p>要素によってマークアップされている。
このXML文書は、ある種のXMLらしさを直接的に表現している。見て分かる通り、このXML文書には以下のような特徴がある。
- 本文のほかにさまざまな情報がついている
- DTDはきちんと書くとけっこう複雑で長くなる。また表記も直接的ではなく分かりにくい
- DTD以外にも、本文以外の情報が多く付加されている(主要な情報ではなく、その情報の周辺の補助的な情報をメタデータと呼ぶ)
- 異なる目的の情報が1個のXML文書に共存している
これらは、必ずXML文書に見られるわけではないが、非常にしばしば目にする状況である。典型的なXML文書の使い方のパターンと言ってよいだろう。
CSVファイルをXMLで記述する
文書的なサンプルの次は、純粋にデータ性の強いXML文書をサンプルとして取り上げてみよう。前の例で使ったtxt2xmlは、CSVファイルをXMLに変換する機能も持っている。そこで、Excelで表を作り、これをCSV形式で保存し、XMLに変換してみよう(CSV形式とは、データがカンマ(,)で区切られたシンプルなデータ形式)。
■HTMLに似せた変換例
元データは以下の内容であるとする。
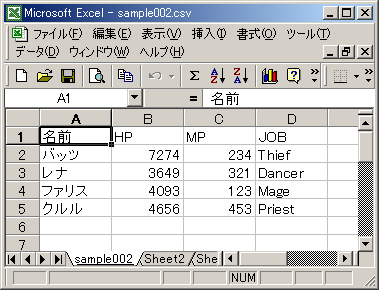
これを保存したCSVファイルの内容は以下のようになる。
1: 名前,HP,MP,JOB 2: バッツ,7274,234,Thief 3: レナ,3649,321,Dancer 4: ファリス,4093,123,Mage 5: クルル,4656,453,Priest
このファイルを、txt2xml(-csvモード)でXML文書に変換した結果は、以下のようになる。
1: <?xml version='1.0'?> 2: <!DOCTYPE table [ 3: <!ENTITY lt "<"> 4: <!ENTITY gt ">"> 5: <!ENTITY amp "&"> 6: <!ENTITY apos "'"> 7: <!ENTITY quot """> 8: <!ELEMENT fileName (#PCDATA)> 9: <!ELEMENT timeLastAccess (#PCDATA)> 10: <!ELEMENT timeCreation (#PCDATA)> 11: <!ELEMENT timeModify (#PCDATA)> 12: <!ELEMENT fileSize (#PCDATA)> 13: <!ELEMENT head (fileName|timeLastAccess|timeCreation|timeModify|fileSize)*> 14: <!ELEMENT td (#PCDATA)> 15: <!ELEMENT tr (td)*> 16: <!ELEMENT table (head,tr*)> 17: ]> 18: <table> 19: <head> 20: <fileName>delme.csv</fileName> 21: <timeLastAccess>Sun Jul 16 16:42:18 2000</timeLastAccess> 22: <timeCreation>Sat Jul 15 21:18:44 2000</timeCreation> 23: <timeModify>Sat Jul 15 21:18:44 2000</timeModify> 24: <fileSize>192</fileSize> 25: </head> 26: <tr> 27: <td>名前</td> 28: <td>HP</td> 29: <td>MP</td> 30: <td>JOB</td> 31: </tr> 32: <tr> 33: <td>バッツ</td> 34: <td>7274</td> 35: <td>234</td> 36: <td>Thief</td> 37: </tr> 38: <tr> 39: <td>レナ</td> 40: <td>3649</td> 41: <td>321</td> 42: <td>Dancer</td> 43: </tr> 44: <tr> 45: <td>ファリス</td> 46: <td>4093</td> 47: <td>123</td> 48: <td>Mage</td> 49: </tr> 50: <tr> 51: <td>クルル</td> 52: <td>4656</td> 53: <td>453</td> 54: <td>Priest</td> 55: </tr> 56: <tr> 57: </tr> 58: </table>
1〜17行目に関しては、DTDの定義の内容は違うものの、基本的に前の例と同じなので、説明は省く。txt2xmlのCSV変換機能は、いちどXMLに変換した上で、スタイルシート変換言語(XSLT)でHTMLに変換することで、自動的にCSV情報を公開するページを生成することを意図して作られたものである。そのため、CSV情報の中の意味に関しては、いっさい斟酌していない。それよりも、HTMLへの変換を容易にするために、HTMLのテーブル関係の書式に似た形で、データを出力している。実際、このデータを、HTMLに変換するXSLTスクリプトを書くのは容易である(XSLTに関しては別途改めて取り上げる予定である)。
しかし、このXML文書は、内容をデータとして処理するにはあまり適していない。例えば、このデータを元に、HPの数値が最大になるレコードの名前を出力する、といった処理を記述するのは面倒で分かりにくいものになる。また、人間がこのXML文書を見ても、意図する内容を判断するのは容易ではない。
■人間に分かりやすくしてみる
これに対処するひとつの考え方は、CSVファイルの最初の1行をフィールド名のリストと見なして、これを要素名としてXML文書を生成するというものである。txt2xmlの-csv2モードはこれを意図している。これを用いてXML文書に変換した結果は以下のようになる。
1: <?xml version='1.0'?> 2: <!DOCTYPE table [ 3: <!ENTITY lt "<"> 4: <!ENTITY gt ">"> 5: <!ENTITY amp "&"> 6: <!ENTITY apos "'"> 7: <!ENTITY quot """> 8: <!ELEMENT fileName (#PCDATA)> 9: <!ELEMENT timeLastAccess (#PCDATA)> 10: <!ELEMENT timeCreation (#PCDATA)> 11: <!ELEMENT timeModify (#PCDATA)> 12: <!ELEMENT fileSize (#PCDATA)> 13: <!ELEMENT head (fileName|timeLastAccess|timeCreation|timeModify|fileSize)*> 14: <!ELEMENT 名前 (#PCDATA)> 15: <!ELEMENT HP (#PCDATA)> 16: <!ELEMENT MP (#PCDATA)> 17: <!ELEMENT JOB (#PCDATA)> 18: <!ELEMENT record (名前,HP,MP,JOB)> 19: <!ELEMENT table (head,record*)>]> 20: <table> 21: <head> 22: <fileName>delme.csv</fileName> 23: <timeLastAccess>Sun Jul 16 16:52:21 2000</timeLastAccess> 24: <timeCreation>Sat Jul 15 21:18:44 2000</timeCreation> 25: <timeModify>Sat Jul 15 21:18:44 2000</timeModify> 26: <fileSize>192</fileSize> 27: </head> 28: <record> 29: <名前>バッツ</名前> 30: <HP>7274</HP> 31: <MP>234</MP> 32: <JOB>Thief</JOB> 33: </record> 34: <record> 35: <名前>レナ</名前> 36: <HP>3649</HP> 37: <MP>321</MP> 38: <JOB>Dancer</JOB> 39: </record> 40: <record> 41: <名前>ファリス</名前> 42: <HP>4093</HP> 43: <MP>123</MP> 44: <JOB>Mage</JOB> 45: </record> 46: <record> 47: <名前>クルル</名前> 48: <HP>4656</HP> 49: <MP>453</MP> 50: <JOB>Priest</JOB> 51: </record> 52: </table>
このリストでは、1行分のデータが<record>要素によって示されている。そして、個々のデータは、1行目に記載された名前が要素名であるとして、タグ付けされている。これを見れば、どの数値がHPであり、それに対応する名前がどれであるかが一目瞭然となる。
例えば、7274という値が、<HP>という要素の値となることによって、HPという情報と、7274という値が互いに深く関連していることが、XMLデータ上の構文として示される。また、これらの要素のグループが、<record>要素によってグループ化されているために、同じ<HP>が複数あっても、それぞれが他のどのデータとグループを形成しているかが、明瞭に分かる。
このような形で、単にデータを列挙するのではなく、個々のデータに対して要素や属性を用いて意味づけしていくのが、XMLによるデータ扱いの基本である。
■要素か属性か
今回の例では、要素の値を使ってデータを表現しているが、属性を使うやり方もある。例えば、上の例で示した1行、
<HP>7274</HP>
これを以下のように表現するやり方もある。
<HP value="7274"/>
要素の値を使う方法と、属性を使う方法は、どちらも一長一短があって、どちらが正しいというものではない。状況や目的によって使い分けるものである。例えば、要素の値を使う場合は、更に要素をネストして記述することができるので、より複雑な情報を記述することに適する。それに対して、属性を用いる方法は値に要素を含めることはできないが、複数の値を1つの要素に関連づけるのが容易である。
現実に使われる実例
さて、実際に現場で使われている本格的なXML文書は、どのような雰囲気で記述されているのだろうか。
ここでは、日本電子出版協会(JEPA)が電子出版用の標準形式として開発している言語JepaXを例として見てみよう。JepaXの仕様書は、JepaX自身で記述されている。そのJepaX仕様書の一部抜粋を見てみよう。
1: <bookinfo> 2: <book-title reading="JepaX">JepaX</book-title> 3: <book-subtitle>JEPA電子出版交換フォーマット</book-subtitle> 4: <edition>Draft: Version 0.9</edition> 5: <book-author role="著" reading="ニホンデンシシュッパンキョウカイ シュッパンデータフォーマットヒョウジュンカイインカイ">日本電子出版協会 出版データフォーマット標準化研究委員会</book-author> 6: <pub-date>19990930</pub-date> 7: <publisher>日本電子出版協会</publisher> 8: </bookinfo>
これは電子書籍の本文ではなく、奥付などの情報を電子的なフォーマットで持つ書誌情報を記述した部分の抜粋である。ここでは、特に5行目を見ていただきたい。<book-author>要素は、著者に関する情報を記述する要素である。その内容は、当然著者名である。しかし、この要素には、内容として文字列が書かれているほかに、2つの属性が付いている。
1つはroleという名前の属性で、これは、著者の役割を示す情報である。“著”、“訳”、“監修”、“編”、“画”などを記述して使う。だがなぜ属性なのだろうか? これも要素として<book-author>要素と並列に列記してはダメなのだろうか? その回答はこうだ。著者が複数いる場合は、<book-author>要素を複数列挙することになる。そこで、<book-author>要素の属性として、役割が記述される意味が生じる。つまり、それぞれの著者に対して、役割が属性として付く形になるため、どの役割が、誰に対応するのかが明瞭になるのである。これが明示されることで、特定の名前の人が訳した本だけを(自分で著した本は除いて)探す、という検索も可能になる。
もう1つのreading属性は、内容の文字列の読みを明示的に示すために使用される属性である。著者の名前の読み方が分からないというような状況はしばしば起きることだが、いちいちルビを振るのは歓迎されないこともある。だから、このような表現方法に意味がある。つまり、読み情報は情報本体の一部ではないが、しかし必要な場合もあるので、一歩引いた形で記述する方法を用意しておく。つまり本体は内容で、付加的な情報は属性で、という表現スタイルなのである。
同じ情報の表現にも複数の方法がある
データをXML文書として表現する方法はいろいろある。しかし、慣習的によく使われる定石もある。今回は、典型的なパターンをいくつか紹介した。これらのパターンは、XMLを扱っていれば、しばしば見かけることになるだろう。逆に、これがXMLの使い方の全てと言うわけではない。
今回の説明に対して注意すべきことは、同じ情報を表現するにも、複数のやり方があるということだ。例えば、同じ情報を要素の内容として書くことも、属性として書くこともできる、というのは最も典型的な一例である。そして、そのどのやり方が本当に正しく有益であるかの判断は、たいへんに微妙で難しい。ときとして、常識通りの記述がうまく機能しない、ということすら存在する。これは、古くて新しいXMLユーザーに課せられた永遠の課題である。
さて、XML文書にはいろいろな表現方法があることは分かっていただけたと思うが、実際にアプリケーションソフトで処理する場合には、すべてを自由に使うことはできず、アプリケーションソフトが想定する使い方に制限される。その制限を記述するために、いわゆるスキーマ言語が存在する。スキーマ言語の中でも最も基本となるDTDを通して、次回は、構文の制限についてを考えてみよう。
それでは次回、また会おう。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。