速報! SQL Server 2005のデータパーティション:SQL Server 2000 チューニング全工程(3)(1/3 ページ)
本連載ではSQL Server 2000のチューニングに関するノウハウを解説する。SQL Server 2000は自動チューニング機能を持つために、チューニングはあまり必要ないと思われがちだが、そのアーキテクチャを理解し適切にツール類を使用しなければ、本来のパフォーマンスを得られない。(編集局)
データパーティション機能の必要性
前回「動的ディスク管理でのチューニングポイント」では、データベースの割り付け方法について以下の内容を紹介しました。
- データベースは、複数のデータファイルによって構成される
- 複数のデータファイルをグループ化するためにファイルグループを使用できる
- ファイルグループにより、テーブルやインデックスを複数のディスクドライブにまたがって割り付けることができ、IOを物理的に分散できる
このような機能により、数万件もの巨大なデータを格納するテーブルへのアクセスを改善することができます。また、データファイルやファイルグループは、データベースのバックアップ、復元の単位として使用できるため、1回のバックアップ操作が、許容される時間内に完了しないような巨大なデータベースの場合、複数のデータファイルに分散して割り付けることで、バックアップや復元を複数回に分けて行えることも理解しておきましょう。
さて、実際に、テーブルに数万件も膨大なデータを格納する運用とは、どのような場合でしょうか。商取引などのビジネスを行っている企業では、受注した商品のトランザクションデータを保存しているでしょう。また、製造業では、製品の生産率、歩留まりや運転コストなどを算出するためのデータを時系列的に保存しているでしょう。これらの履歴データを蓄えて分析することは、今後の販売活動の効率化や生産性、品質向上のため、重要視されるようになってきています。このような時系列的に累積されたデータをテーブルに格納していると、どんどんその件数が増えていきます。
例えば、受注データをTransactionHistoryテーブルに格納しているとしましょう。その企業は、1日に1000件の取引を行っているとします。そして日々、データは累積されていきます。1年が経過すると、36万5000件ものデータになります。このデータをSQL文で記述したクエリを使用して分析することを考えると、さまざまなクエリを記述しなければなりません。売り上げ金額、経費や利益などを製品ごと、顧客ごと、店舗ごとに集計したいと考えるでしょう。しかし、格納しているデータが増加してくるとクエリのパフォーマンスは低下してきます。このような場合、皆さんはどうするでしょうか?
OLAPの仕組みを理解している方は、OLAPストアに集計済みのデータを保存し、ExcelやReporting Servicesのクライアントなどからアクセスすることを検討するでしょう。それで、面倒なクエリをたくさん記述する作業からは解放されます。しかし、この膨大なデータをストアしているTransactionHistoryテーブルは、このままにしておいてよいでしょうか?このテーブルに5年も10年もデータを格納した場合、発生する問題を考えてみましょう。インデックスの再構築や不要になった履歴データの削除に時間がかかるようになり、メンテナンスの作業負荷が上がり、ユーザーが履歴テーブルを使用できる時間が制限される状況に陥るかもしれません。
そこで、通常は、分析対象としてあまり使用されない古い履歴データをアーカイブ用のテーブルに移すことを検討します。OLAPストアを利用する場合でも、増分更新の機能を使用していれば、ベーステーブルに、常に過去の履歴データをすべて格納しておくような運用を行う必要がありません。
例えば、毎月、TransactionHistoryテーブルから最も古い1カ月分のデータをTransactionHistoryArchiveテーブルに移動することを考えてみましょう。3万件のデータをTransactionHistoryテーブルからTransactionHistoryArchiveテーブルにINSERT文で挿入して、操作が完了したら、DELETE文で削除するような処理を行わなければなりません。このような処理は、テーブルにかかるロックの時間が長くなるため、なるべく早く終了させたいものです。このような局面で有効になるのが前回の記事の最後に少し紹介した、SQL Server 2005(2005年中にリリース予定のSQL Server 2000の次期バージョン)でサポートされるデータパーティションの機能です。
データパーティションの仕組み
指定された列により、グループ化された行を個別のパーティションにマッピングすることで、テーブルを水平単位に分割できます。SQL Server 2000では、複数のデータファイルをファイルグループにより束ねたとしても、ファイルグループに割り付けられるのは単一のテーブルやインデックスの単位です。しかし、パーティションを定義する場合、水平分割されたデータの集合の単位で、ファイルグループを指定することもできます。また、パーティション分割されたテーブルであっても、クエリなどの操作からは、テーブル全体が単一のエンティティであるかのように実行されます。
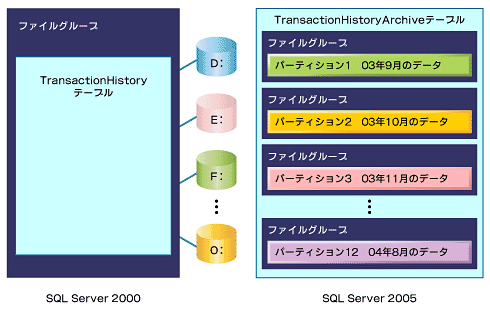 図1 ファイルグループとデータパーティションの比較
図1 ファイルグループとデータパーティションの比較パーティションを定義することで、パーティションごとにインデックスの構造が作成されるため、インデックス再構築の時間を短縮できます。また、パーティション単位でのデータの移行や削除を高速に行うことができます。SQL Server 2005では、1つのテーブルに最大1000個のパーティションを作成できます。
データパーティションの設定手順
パーティションテーブルを定義するには次の3段階のステップがあります。
- パーティション関数を定義し、その関数を使用するテーブルのパーティション方法を指定
- パーティションスキームを定義し、パーティション関数で指定されたパーティションを配置するファイルグループを指定
- 定義されたパーティションスキームを使って、テーブルまたはインデックスを作成
簡単なサンプルスクリプトで手順を紹介します。
1.パーティション関数を定義し、その関数を使用するテーブルのパーティション方法を指定
リスト1のパーティション関数では、int型の列に格納された値に基づきテーブル、およびインデックスを4つのパーティションに分割できます。定義されたパーティション関数は、テーブルの作成時(3番目のステップ)に参照します。
CREATE PARTITION FUNCTION myRangePF1 (int) |
| リスト1 パーティション関数の定義 |
分割されたパーティションに格納される値は以下の範囲になります。
- 指定された列 < 1
- 1 <= 指定された列 < 100
- 100 <= 指定された列 < 1000
- 1000 <= 指定された列
2.パーティションスキームを定義し、パーティション関数で指定されたパーティションを配置するファイルグループを指定
リスト2のパーティションスキームは、myRangePF1パーティション関数で指定された4つのパーティションをFG1〜FG4のファイルグループに配置することを指定しています。
CREATE PARTITION SCHEME myRangePS1 |
| リスト2 パーティションスキームの定義 |
3.定義されたパーティションスキームを使って、テーブルまたはインデックスを作成
リスト3のテーブル定義文では、定義されたパーティションスキームを使用するよう指定しています。
CREATE TABLE PartitionTable |
| リスト3 パーティションスキームを使ったテーブル定義文 |
作成したパーティションスキームは、複数のテーブルで使用できます。次ページでは実際にサンプルデータベースを使ったサンプルを紹介します。(次ページへ続く)
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。