複合索引(コンポジット索引)が有効なケース:Oracle SQLチューニング講座(8)(2/3 ページ)
複合索引(コンポジット索引)をさらに有効利用する
前ページの図4で示された複合索引を使用した実行計画から、すべての索引ブロックに1つずつアクセスする全索引スキャン(INDEX FULL SCAN)が実行されていることが確認できました。表データへのアクセスを排除することで大きくパフォーマンスを改善できましたが、このようにすべての索引ブロックを読み込む必要がある場合には、さらに高速全索引スキャン(INDEX FAST FULL SCAN)を使用することで、複数の索引ブロックをパラレル処理にて読み込むことにより、よりパフォーマンスを向上できる可能性があります。
ただし、複数の索引ブロックをまとめて読み込むため、取り出されたデータの順番が保証されません。高速全索引スキャンでアクセスした場合、その後にソート処理が必要となる点に注意が必要です。
それぞれの特徴をまとめると表1になります。
| 全索引スキャン | 高速全索引スキャン | |
|---|---|---|
| アクセス方法 | シングルブロックアクセス | マルチブロックアクセス |
| 取得データの順番 | 保証される | 保証されないため、ORDER BY句などが指定されている場合、データ取得後にSORT処理が実行される |
| ヒント文 | INDEX | INDEX_FFS |
| そのほか | ・パラレルでのスキャンが不可能 | ・指定した列のうち少なくとも1つはNOT NULL制約が必要 ・全表スキャンと同様にパラレルでスキャン可能 |
| 表1 全索引スキャンと高速全索引スキャンの特徴 | ||
図6では、ヒント文で高速全索引スキャンを使用し、かつ、パラレル度4で索引スキャンするようにオプティマイザに指示し、SQLトレース、TKPROFユーティリティを使用して実行計画を取得しています。
 図6 並列度4での複合索引による高速全索引スキャンの場合
図6 並列度4での複合索引による高速全索引スキャンの場合図4の実行統計と比較すると、実行時間が短縮されていることが分かります(パラレル処理の場合、disk、query、currentの値は不正確ですので、時間で比較します)。これは、高速全索引スキャンの特徴であるマルチブロック読み込みの効果といえます。しかし、表1にも記述したように取得したデータはソートされていないため、「ORDER
BY句」が指定されている場合には、全索引スキャンでは発生しないソート処理が発生してしまいます。そのため、索引のサイズ、取り出される行数(データ量)によっては、全索引スキャンでソート処理を排除した方がパフォーマンスが良いケースもありますので、実際にSQLを実行して実行時間を計り、適切な実行計画を選択するようにしてください。
COUNT(*)の高速化
表示件数を制限しているようなアプリケーションでは、初めに検索条件に合致する件数をCOUNTしていることが多いと思います。そのようなアプリケーションにおいて、
SELECT COUNT(*) FROM ORDERS;
というように、特定の列名を指定していない記述を見受けることがあります。しかし、検索対象となる表に主キーが設定されている場合には、その主キー索引を使用した索引全スキャンを実行することで、実行時間を大きく短縮できます。
それでは、次のようなSQLを実行して、SQLトレース、TKPROFユーティリティを使用して実行計画を取得します。
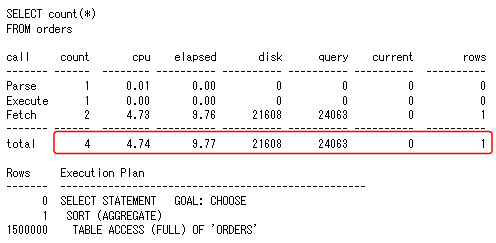 図7 COUNT(*)を使用した全表スキャンの場合
図7 COUNT(*)を使用した全表スキャンの場合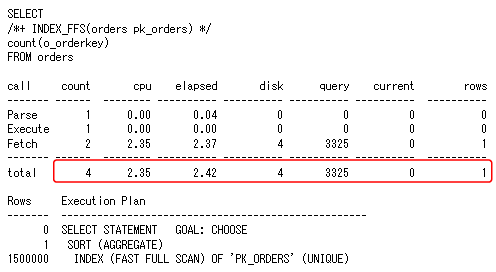 図8 主キー索引を使用した高速全索引スキャンの場合
図8 主キー索引を使用した高速全索引スキャンの場合図8のように「COUNT(主キー列)」として高速全索引スキャンを使用することで、アクセスブロック数が大幅に減少し、実行時間が短縮されていることが確認できます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。