索引の使い分けでパフォーマンスを向上できるケース:Oracle SQLチューニング講座(9)(3/4 ページ)
逆キー索引の使用
逆キー索引は、索引列のデータをビット単位で反転させ、その反転させたデータをソートして索引に格納します。このため、索引列の値が昇順で増加するようなINSERT処理を多重で実行した場合、索引のブロック競合を低減させることができます。
ただし、ビット反転されているため、“<”、“>”、“between”などの範囲検索では索引スキャンを行うことができません。逆キー索引を使用する場合は、検索処理のパターンを見極めたうえで使用する必要があります。
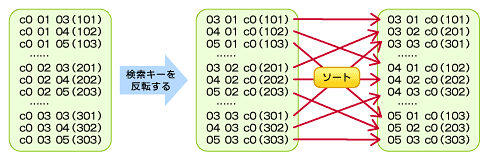 図8 逆キー索引でのデータ格納イメージ
図8 逆キー索引でのデータ格納イメージ例えば、受注テーブルを考えてみます。受注番号はシーケンスを使用して昇順に値が振られ、多くの端末から同時にINSERT処理が実行されています。このとき、受注番号にB*Tree索引が作成されていると、図9のように索引ツリーの最後のブロックに挿入処理が集中してしまい、パフォーマンスが劣化する原因となってしまいます。
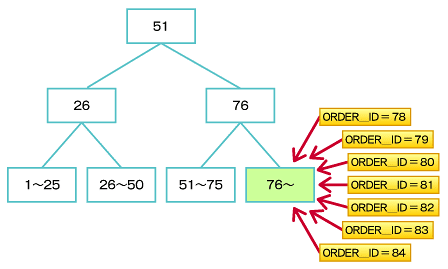 図9 B*Tree索引での特定索引ブロックへのアクセス集中
図9 B*Tree索引での特定索引ブロックへのアクセス集中このような場合、逆キー索引を使用すると、連続したデータでも図10のように複数の索引ブロックに分散して挿入されることになるため、図9のような特定ブロックへのアクセス集中による競合を軽減できます。
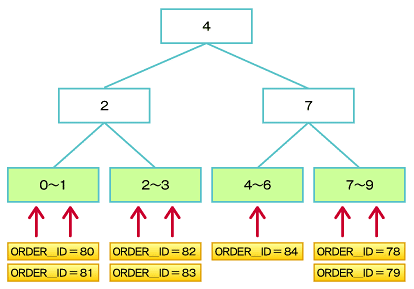 図10 逆キー索引の使用による挿入データの分散
図10 逆キー索引の使用による挿入データの分散以下の図11は、大量のINSERT処理を行った場合の、B*Tree索引と、逆キー索引での競合発生状況をV$WAITSTAT動的パフォーマンスビューの「data block」項目で確認したものです。
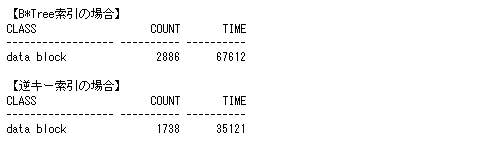 図11 逆キー索引による索引ブロック競合の減少
図11 逆キー索引による索引ブロック競合の減少上記の例では、逆キー索引を使用することで待機回数が「1148回」、待機時間が「324.91秒」減少しています。ブロック競合をさらに減らすためには、表をハッシュ・パーティション化することも有効です。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。