I/Oボトルネックの病巣はこれで究明できる:Dr. K's SQL Serverチューニング研修(7)(2/3 ページ)
的確な領域見積もりの第一歩は、
データ件数の正確な見積もりが基本
データ領域サイズ見積もりを行うに当たって、まずテーブルのデータ件数を正確に見積もっていることが大事です。例えば、現在6万件くらいあるテーブルで、1日に1000件くらい増加しているとします。この場合、第5回「排他制御の落とし穴を避けるインデックス設計」でお話しした、テーブルのプライマリキーをどうするのかといったことを考えておくべきです。
SQL Serverに任せて自動的にインクリメンタルなキーを作っていくのか、ユーザーテーブルの中に自動採番の仕組みを作るのか、もしくは伝票にあらかじめ印刷された伝票番号が入っているのか……、その設計方法により、関連するテーブルにInsertされる1000件/日のプライマリキーの格納分布が変わってきます。そういうことも、本当はデザインの段階できちんと押さえておかないといけないのです。第5回のインデックス設計でお話したページ分割と、fill factor値の設定を思い出してください。
こういう条件が分かると、8Kbytesのデータページに何件のデータが入るのかは、テーブルの定義から各列のプロパティ(データ型)を計算していけば出ます(ただし、可変長型データや、null指定が入ってくると簡単にはいかないのですが)。
こうして計算したデータサイズはあくまでもデータページの領域であって、このほかにクラスタ化インデックスを格納する領域も必要になります。プライマリキーをどう設計するかという話は、ここにかかわってくるのです。少し煩雑な計算式ですが、必要なクラスタ化インデックスと、データページを見積もるための計算式もマイクロソフトより公開されています。
- MSDN2「クラスタ化インデックスのサイズの見積もり」
このほかの方法として、現在運用中のデータベース環境から、リスト2のストアドプロシージャ実行により、現在のデータ行数、データページ数、インデックスページ数を知ることができます。
use
'データベース名' |
| リスト2 データ領域サイズ見積もりを行うストアドプロシージャ |
一般的にデータページの大きさを100とすると、クラスタ化インデックスだけの場合は、その10%も見ておけば十分です。ただ、同じテーブルに非クラスタ化インデックスを作成する場合は、別個に見積もりが必要になります。
ところが、こういった計算をきちんと実行して現状の6万件に必要な領域を割り当てたとしても、運用するに従ってデータのフラグメンテーションが起きてしまいます。そこで「DBCC INDEXDEFRAG」と「DBCC DBREINDEX」(詳細は第5回「排他制御の落とし穴を避けるインデックス設計」を参照)を実行するのですが、この処理はデータファイルの中にソート用ワーク領域を取って並べ替えを行います。この領域も、サイズ見積もりには重要な要素となります(SQL Server 2005からは、領域の再編成を行うときに「tempdbを使ってソーティングせよ」というオプションが加わり、tempdbを使うかユーザーデータベースを使うかを選べるようになりました)。
SQL Server 2000の場合は、仮にインデックスページとデータページの総和が500Mbytesあれば、必要な初期サイズは通常2.3倍で計算できます。なぜこれだけ大きくサイズを取るかというと、インデックスのデフラグ(DBCC INDEXDEFRAGやDBCC DBREINDEX)をユーザーデータベース内で実行するので、そのソート用のワークエリアを見込んで2.3倍と見積もるのです。定期的なデータ格納領域断片化の解消と、オプティマイザが参照する統計情報の定期的な更新が、コストベースでクエリ・プランを最適化するSQL Serverにととって不可欠な保守作業です。
以上のようなことをちゃんと考えて使っているユーザーというのは、なかなかいるものではありません。しかし、このように、領域の見積もりをきちんとロジカルに計算して、必要な領域を確保していくのは、やはりデータベースアーキテクトの仕事だと思います。そこをきちんとやっていくのが大事だと私は思っています。
SQL Serverはどうやってディスク領域を作成・管理するのか
ここからはSQL Serverの内部的な動作を見ていきましょう。図3は新規にデータベースを作成する一連の作業を示しています。
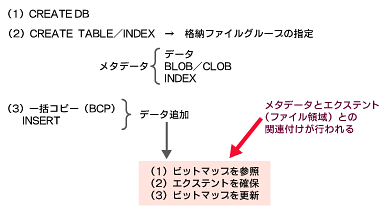 図3 新規にデータベースを作成する作業
図3 新規にデータベースを作成する作業データの負荷が大きければ「データ1」「データ2」のように、またインデックスも「Index1」「Index2」のように階層化する方法がある。またディスクのパーティション上に、どの程度高速なファイルシステムやストレージシステムがあるかによって、適正な負荷分散を考慮する必要がある
まず(1)の「CREATE DB」でデータベースを作成し、(2)の「CREATE TABLE/INDEX」を実行するわけですが、この段階ではメタデータが作成されるだけで、実際のディスク領域はまったく使われていません。
これに対して(3)の「一括コピー(BCP:Bulk Copy Program)」や「INSERT」といった処理により、実際のデータがディスクに書き込まれていきます。この段階で何が起きるかというと、メタデータだけで空っぽの状態であるテーブルやインデックスに対して、実データの追加が行われることによって、初めてエクステントが割り当てられるのです。この時点で、テーブルなどのメタデータと実際のエクステントと呼ばれるファイル領域との関連付けが始まるのです。どれだけのエクステントが必要かというと、CREATE TABLE/INDEXで定義した内容によって、テーブル単位で決まってきます。
ここで登場するのがビットマップです。SQL Server 2000では、エクステントの空き領域を管理するビットマップとして、以下の2つのページを使用します。
- GAM(Global Allocation Map)
1つのGAMで6万4000のエクステント(約4Gbytes)を管理する。1エクステントに1ビットが割り当てられ、空きエクステントの場合は「1」、割り当て済みの場合は「0」が記録される。 - SGAM(Shared Global Allocation Map)
1つのSGAMで6万4000のエクステント(約4Gbytes)について、混合エクステントの割り当てを管理する。1エクステントに1ビットが割り当てられ、混合エクステントとして使用されており空きページを含んでいると「1」、混合エクステントとして使用されていないか、全ページが混合エクステントとして使用されていると「0」が記録される。
データベースエンジンは、この2つのビットマップ(GAMとSGAM)を参照して、エクステントを確保し、ビットマップの値を更新するという手順を踏んで領域管理を行っているのです。いくつのエクステントが確保されるかは、格納するオブジェクトの定義によります。例えば、データとインデックスだったら、最低2つのエクステントを作らなくてはなりません。データとインデックスは共有できないので、それぞれ専用のエクステントを持つわけです。
| エクステントの使用状況 | GAMのビット設定 | SGAMのビット設定 |
|---|---|---|
| 空きで未使用 | 1 | 0 |
| 単一エクステント、またはすべて使用された混合エクステント | 0 | 0 |
| 空きページがある混合エクステント | 0 | 1 |
| 表1 エクステントの空き領域を管理するビットマップ | ||
GAMとSGAMに加えて、各ページの空き容量を記録するPFS(Page Free Space)というページもあります。1つのPFSで64Mbytes(約8000ページ)を管理します。PFSには管理対象のページごとに1つのビットマップ(8ビット)が用意され、ページ使用率が「0%」「1〜50%」「51〜80%」「81〜95%」「96〜100%」のどれであるかが記録されています。
1つのデータファイル内に配置されるページの構成は、図4のようになります。ファイルの先頭にはファイルヘッダがあり、次にPFS、GAM、SGAMという順になります。SGAMというのは、混合エクステントの場合に使いますから、通常はPFSとGAMを図3の(2)で行うアロケーションのときに作っているわけです。データベースエンジンはPFSとGAMを見ながら、ファイルの頭から64Kbytesのエクステントを取っていって、どんどん詰めていきます。データ用に64Kbytes、インデックス用に64Kbytesといった具合に、エクステントを作成していき、GAMにこのページはもう使用済みですと記録していくのです。
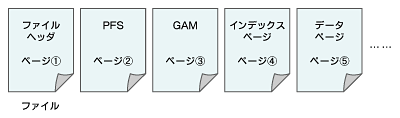 図4 ファイル内のページ構成
図4 ファイル内のページ構成1つの論理テーブルはn個のエクステントから構成されているので、それがどこにあるのかというのをアロケーションするためのマップがあります。これをIAM(Index Allocation Map)といいます。各ページにどれくらいの空き領域があるのか、その領域をどのオブジェクトがどう使っているのか、どれくらいの空きがどこに残っているのかという領域管理は、IAMとPFSを参照して行うわけです。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。