WAFのセキュリティレベルとパラメータ設定:Webアプリケーションファイアウォールの必要性(最終回)(3/4 ページ)
Dynamic content valueによるパラメータ値の改ざんチェック
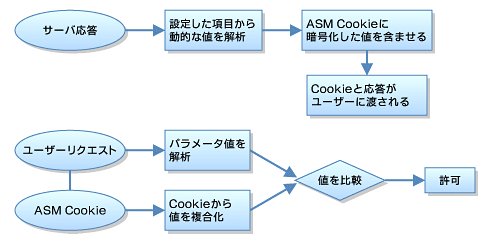
Dynamic content valueは、同一のオブジェクト、Flowであってもプログラムによってダイナミックに値が生成されるようなものを指している。この値が改ざんされないことを保証するために、BIG-IP ASMではCookieを使用したメカニズムを採用している。
あるレスポンスページ内からDynamic content valueを手に入れるのであるが、その内容をハッシュ化したCookieをBIG-IP ASMはクライアントに返す。次にクライアントは、Dynamic content valueとBIG-IP ASMが発行したCookieを持ってリクエストを投げてくる。BIG-IP ASMでは、CookieとDynamic content valueの値を比較し、サーバのレスポンスのときから変更が加えられていないことを確認したうえで、リクエストを通過させる。
設定の手間を軽減する学習機能
オブジェクトの登録およびFlowの設定を手動で行うやり方を紹介したが、実際のサイト構築においてすべてのオブジェクトとFlowを手動入力するのは設定にかかる時間を考えると現実的ではない。実際にはここに紹介する学習機能によって、ある程度自動的に情報を収集し、その後に手動で設定を変えていく手法を取ることになる。いわゆるWAFといわれる製品はほぼすべて、ある程度の学習機能を備えており、設定時間の短縮を図れるようになっている。
BIG-IP ASMでは以下のような機能を使用してポリシーの学習を行うことができる。
- Real Traffic
- Crawler
- Policy Browser
- Auto-Accept
ここではよく使用されるReal TrafficとCrawlerについて説明する。
1.Real Traffic
BIG-IP ASMは常にReal Trafficの学習モードで動作しており、この機能を停止させることはできない。すでに設定済みであるポジティブルール上に存在しない、violationとして判断されるトラフィックをブロックするかどうかが制御可能である。
設定が完了すれば、violationのトラフィックをブロックすることになるが、設定途中においてはviolationのトラフィックを通過させることもできる。通過させるかブロックするかは、Webアプリケーション全体またはviolationの種別ごとに細かく設定できるようになっている。
violationとして判断されるトラフィックはすべて(ブロックするにせよ通過させるにせよ)学習テーブルに書き込まれる。管理者は本当に正しい、通過させるべきトラフィックかどうかを、内容を見て確認し、もし通過させるべきトラフィックであれば「Accept」という操作を管理者が行い、その内容がポジティブルールに書き込まれる。そして次回同様のトラフィックがやって来た際には正しいトラフィックとして通過させる。このAcceptという作業を繰り返していくことによって設定が出来上がっていく。以下が、violationとして記録されたときの例である。
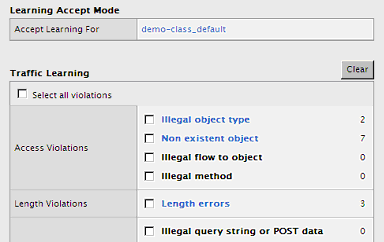 画面8 学習テーブル。違反があれば該当の違反のカウントが上がる
画面8 学習テーブル。違反があれば該当の違反のカウントが上がる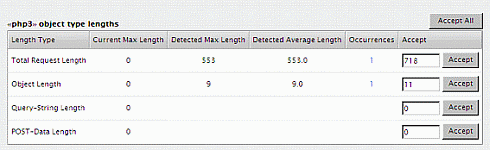 画面9 実際にどのような違反があったかを確認し、正しいトラフィックであればAcceptする
画面9 実際にどのような違反があったかを確認し、正しいトラフィックであればAcceptする前述の手入力でポリシーを作り上げていく代わりに、何も設定が入っていないセキュリティポリシーを使用してトラフィックを一通り流し、本来通すべきトラフィックのすべてをAcceptすることによってポジティブルールを構築していくという方法を取ることも可能である。
ここで出力されるviolationはそのままログ情報となり、そのログ情報が設定を作成していく道筋となっている形である。
2.Crawler
オブジェクトやパラメータをすべて登録しなければならないEnhanced StandardモードやAPC Phase1の場合、手入力やReal Trafficですべての要素を登録するのは非常に手間がかかる。このためBIG-IP ASMではCrawlerという自動巡回ツールを内蔵しており、ある程度サイト上の情報を自動的に取得し学習させることができる。
Crawlerは取得したページのFormタグに含まれるパラメータに値をセットできる。このため単なるリンク追跡とは異なり、例えば認証後のコンテンツも取得して学習させることができる。
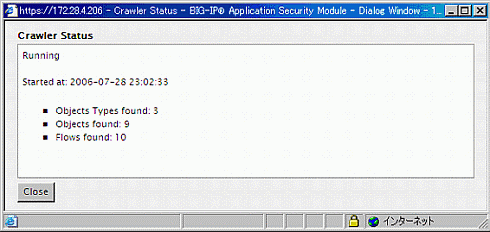 画面10 Crawler Status
画面10 Crawler Statusこれらの学習機能と手入力を組み合わせて、最終的な設定が確定されてゆく。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。