パーティショニングとパラレル処理は最高の相性:Oracleパーティショニング実践講座(3)(2/4 ページ)
パラレル処理に分割される基準
それでは指定された並列度に対して、アクセスするデータはどのような基準で分割されるのでしょうか?
対象となるデータが非パーティショニングの場合
非パーティショニング環境では、対象となるデータが分割されていないので、指定された並列度に応じてブロック範囲(つまりROWIDの範囲)に分割する必要があります(図5)。この場合、パラレル処理の前にブロック範囲に分割するタスクが発生し、また、ROWID範囲で分割したデータがパラレル処理に適した形でデータファイルに分散して格納されているわけではないため、ディスクI/Oの競合が発生するなどの理由からパラレル処理のメリットを十分に享受できないと考えられます。
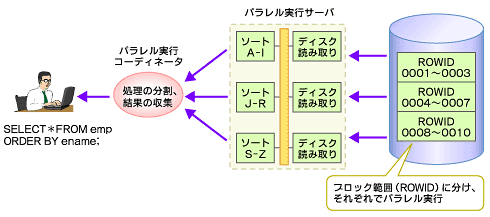 図5 非パーティショニング環境でのパラレル処理
図5 非パーティショニング環境でのパラレル処理対象となるデータがパーティショニングの場合
ここで「データ側もきちんと分割しておけば」という考えが必要になってきます。パーティショニング環境の場合には、図6のように基本的にパーティションごとにパラレル実行サーバが割り当てられます。
例えば、売り上げデータの売り上げ日付列をパーティション・キーにして、月ごとのパーティションを構成している場合、1年間の売り上げ集計を行うためには12個のパーティションにアクセスすることになります。仮に並列度が4であれば、同時に4つのパラレル実行サーバがそれぞれ割り当てられたパーティションにアクセスすることになります。また、パラレル処理を実施すると、同時にデータにアクセスするためディスクI/Oの競合が発生する可能性がありますが、パーティション表であれば、パーティション単位で格納されるストレージを分散させるなど、明示的にパラレル処理を効率的に実施するのに適した設定が可能です(図6)。
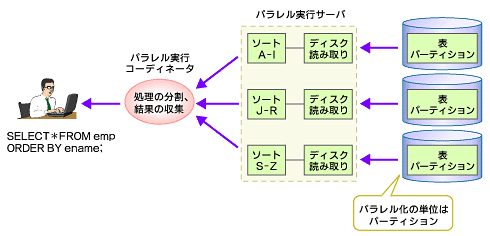 図6 パーティショニング環境でのパラレル処理
図6 パーティショニング環境でのパラレル処理さらにパーティショニングでは、表データに加えて索引データもパーティション化できます。ローカル非同一キー索引は、表パーティションと同じキーにてパーティショニングされているため、図7のようにパラレルの索引走査をほかのパーティションに影響を与えることなく実施できます。パフォーマンスを向上させる場合に索引を使うケースは多いため、索引走査をパラレル化できることは大きな意味を持ちます。
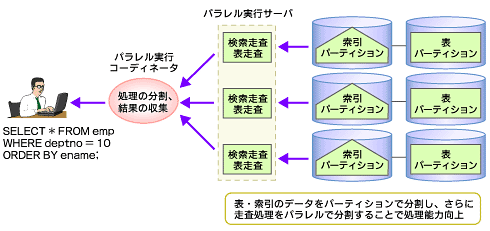 図7 パーティショニング+索引を使ったパラレル処理
図7 パーティショニング+索引を使ったパラレル処理パラレル処理が効果を発揮するケース
ここまでパラレル処理の概要とその仕組みや効果について紹介してきました。特にDSS(意思決定支援システム)およびDWH(データウェアハウスシステム)といった環境でその効果は顕著に表れます。またOLTPシステムにおいても、例えばバッチ処理時および索引の作成などのメンテナンス操作時に、パラレル処理の利点を生かすことができます。
ただ、OLTPシステムで採用される小規模な検索(特定顧客の1取引情報の参照)や、小規模なトランザクション(1件の売り上げデータの登録や特定顧客データの属性変更など)には、パラレル処理は適していません。パラレル処理では処理の分割やパラレル実行サーバへの割り当てに関するコストが発生し(プロセスの起動などを含む)、小規模なトランザクションでは、上記コストがオーバーヘッドになるためです。
またパラレル処理は空いているハードウェア・リソース(CPU、メモリ、ディスクI/O)を活用するよう設計されています。このためにハードウェア・リソースの空きが十分でない場合もパラレル処理の利点はなく、かえってパフォーマンス劣化につながる可能性があるので注意が必要です(表1)。
| パラレル処理が有効な環境 | 対称型マルチプロセッサ(SMP)、クラスタシステム |
|---|---|
| I/Oのキャパシティが大きいシステム | |
| CPUの運用率が低いシステム(25%未満) | |
| メモリに余裕があるシステム | |
| パラレル処理が有効ではない環境 | トランザクションが非常に多い環境(数秒以内) |
| CPU、メモリ、I/Oリソースが頻繁に使用されている環境 | |
| 表1 パラレル処理とシステム環境 | |
このようにパラレル処理は有効に使えるケースと効果が期待できないケースがありますので、状況を見極めたうえでの活用をお勧めします。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。