SQL Server 2005でガラッと変わった個所とは?:Dr. K's SQL Serverチューニング研修 Part II(1)(3/4 ページ)
SQL Server 2005の注目ポイント&新機能
SQL Server 2005には、SQL Server 2000と比較して、いくつもの改善点や新機能が満載されています。新連載の初回ということで、重要なトピックをざっと見ていきましょう。これらの中から、特にパフォーマンス・チューニングに関連の深い項目は、今後の連載の中で詳しく説明していく予定です。
■User Mode SchedulerからSQL OSへと進化
SQL Serverの進化の過程を見てみると、まずSQL Server 7.0でUser Mode Scheduler(以下、UMS)の概念を導入して、それをさらにSQL Server 2005では、SQL Serverが独自に制御するスレッドとして改良しました。これは、具体的にはSQL OSというもので、従来のUMSを全面的に書き換えたものです。SQL Serverでは2世代ごとに大きなアーキテクチャ変更が行われてきたので、そういう意味でも今回のSQL Server 2005では、SQL Server 7.0から受け継がれてきた主要アーキテクチャの全面的な刷新が行われたといってよいでしょう。
この具体的な項目としては、「SQL CLR対応」「SODA(Service Oriented Database Architecture)対応」が挙げられます。これは後の回のどこかでもっと詳しいお話をする予定です。
■動的管理ビュー(DMV)と動的管理関数(DMF)
UMSからSQL OSへの移行で変わった、もしくは付け加えられた大きな特徴を、ほかにもいくつか挙げていきます。まず「動的管理ビュー」(以下、DMV)と「動的管理関数」(以下、DMF)があります。これらはSQL Server 2005で出てきた新しい機能で、今回の連載でもDMVとDMFを中心に解説していくことになると思います。
パフォーマンス・チューニングのうえでなぜこの機能が重要かというと、この2つを使うとデータベースエンジンの中で何が起こっているのかが、すべて見えるようになるからです。いままでは非公開のDBCCコマンドがいくつもあって、そのコマンドを入力しないとデータベースエンジン内部の動きは見られませんでした。しかしマイクロソフトはSQL Server 2005から、それらのコマンドと関数をすべて公開したのです。その結果、中で何が起きているのかが見えるようになりました。
しかし、見えるからといって、それだけでは何も分かりません。技術者はそれが何を意味しているのか、理解する知識を身に付けなくてはならないのです。現在、私が最も関心を持っているのは、DMVとDMFが教えてくれるパラメータを完全に読みこなして、実際のチューニングに生かせる技術者をどうやって育成するかということです。
いままでは非公開コマンドでしたから、分からなくても仕方なかった部分がありましたが、これからはそんなことをいってはいられません。技術者にとっては便利になった分、勉強しなくてはならないことが増えたともいえます。もちろん難しいことではありますが、SQL Server 2005の内部をすべて自分で把握して、思うとおりにチューニングを追求していけるのですから歓迎すべきことだと思います。
■内部的なWait Events事象の増強
データベース・チューニングを行ううえで注目すべき点に「Wait Events事象」があります。SQL Server 2000では75種類だったWait Events事象は、SQL Server 2005では一挙に3倍の225種類に増えています。これは従来のパラメータをより細かく見るように改善したことに加えて、データベース・ミラーリングやService Brokerなどの、新たに付け加えられた機能の待ち事象を見られるようにしたためです。
■拡張パフォーマンスカウンター増強
さらに「拡張パフォーマンスカウンターの増強」も、ぜひ挙げておきたい項目の1つです。SQL Server 2000の「master」システムデータベース内にあるシステムテーブルの中に「sysperfinfo」というテーブルがあり、Windows OSのシステムモニタ(Windows NTではパフォーマンスモニタ)が参照しているSQL Serverの内部パフォーマンスカウンターが格納されています。この「拡張版パフォーマンスモニタ」ともいうべきデータを参照することで、一般には非公開と思われている多くのパフォーマンス情報を見ることができるのです。
このいわば“隠しコマンド”が、SQL Server 2005ではすべて公開されています。項目数もSQL Server 2000の382種類から、倍近い662種類に増えました。これも、チューニング技術者が見なくてはならない部分が増えたことを意味しています。
この拡張パフォーマンスカウンターとDMV、DMFからいったい何が見えてくるかは、本連載の第2回以降に順次説明していきたいと思います。それを通じて、内部のコンテキストスイッチを含めたスケジューラの動きとか、メモリやI/O、排他制御がどのように行われているのかを学んでいきます。
■ストレージエンジンの全面的な書き換え
UMSからSQL OSへの移行と並んで大きな変更点は、「ストレージエンジンの全面的な書き換え」です。その主要項目を見ていきましょう。
マルチコア/NUMAへの対応
これは、マルチコアとNUMAが当たり前になってきた事実を受けて、これらのテクノロジにきちんと対応しようという考えの表れです。ストレージエンジンとしてマルチコアとNUMAをフルサポートできるようにしたのです。技術的には、ノード単位に独立したバッファスペースを含めたメモリスペースを持てるようになったということです。
新たなロックマネージャとロック粒度の導入
ロックの所有者やデッドロックの検知のシステムも変わりました。ロックの管理方法の刷新です。従来のSQL Serverでは、ロックテーブルはシステムで1個しかありませんでした。ところがSQL Server 2005からは、1つで全部行うのではなく、16CPU単位で1つの独立したロックテーブルを持って、データキャッシュの所有権を見られるように変わりました。この辺がストレージエンジンの最適化への対応だといえます。
データ・パーティショニング
これも私が非常に期待しているものの1つです。これに代わる従来の機能としては、SQL Server 2000の「分散パーティションビュー」がありました。これは複数のノードや独立したマシンを、分散トランザクションコーディネータを使って1つに見せていたものです。ところがSQL Server 2000ではオプティマイザがそれほど賢くなくて、インデックスを持っていたりすると、期待した動きをしてくれませんでした。しかも、こうした方法を使うと、非常にメンテナンス性が悪かったのです。
ではSQL Server 2005でデータ・パーティショニングが登場して、何がどう大きく変わったのでしょうか(図4)。
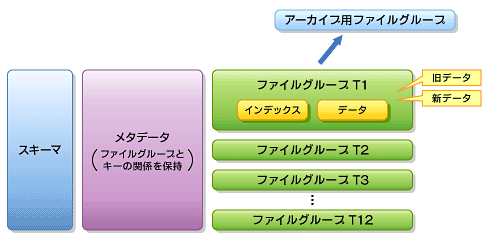 図4 データ・パーティショニング
図4 データ・パーティショニングまず全体の論理的なスキーマがあります。そして、これとファイルグループの間にメタデータをかませてワンクッション置いています。ファイルグループの中にはT1〜T12といったテーブルが格納されるわけですが、メタデータの中にはファイルグループとキーの関係が格納されています。つまり、SQL Server 2005では、「どの範囲のキーは何番目のファイルグループにある」というのをメタデータで管理できるようになったのです。
この結果どうなったのかというと、まず完全にファイルグループ単位にバックアップ/リストアできるようになりました。またアーカイブ用のファイルグループをファイルグループとまったく同じ構造で別個に持ってメタデータで管理できます。さらにファイルグループ内にインデックスとデータを持つことができるため、オプティマイザは完全にファイルグループ単位内で最適化を行って、同一インスタンス内で従来よりも非常に高速で動く仕組みを持てるようになったのです。
これが、今回私がストレージエンジンの中で最も期待している、最適化のためのいくつかの有効な手段の1つです。そのナンバー1がNUMAだとすると、「データ・パーティショニング」はナンバー2といってよいでしょう。これをいかにうまく使って最適化を実現していけるか、この上ないツールを手に入れた気持ちです。
その身近な活用方法を考えると、例えばWebサイトで行っているアクセスログの蓄積ですが、これはどんどん古いデータがたまってきますね。そうするとこの古いデータを、データ・パーティショニングならばメタデータを使って瞬間的に移動できるのです。この例を1つ見ても、使える機能だと思えるでしょう。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。