故障発生時にフェイルオーバーしない?:Linuxトラブルシューティング探偵団(4)(2/3 ページ)
システム構成は?
今回のシステムは、DBサーバ「PostgreSQL」、Webサーバ「Apache」を使用しています。アプリケーションは「Python」で作成され、「mod_python」によりApacheモジュールとして動作させる一般的なWebアプリケーションシステムです。
|
||||||||||
| 表1 システム構成 |
この構成を、前述のとおり「Heartbeat」によりHAクラスタ化しています。図中のvividがアクティブ系、vigorがスタンバイ系になります。
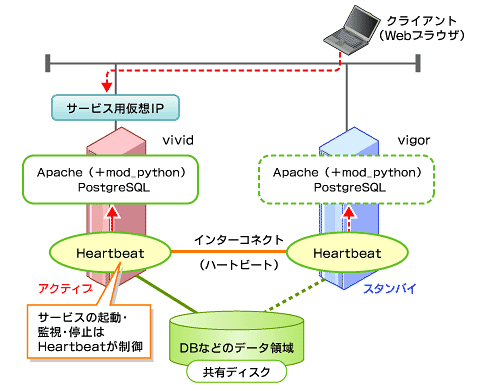 図3 システム構成図
図3 システム構成図■ディスク構成は?
OSのほか、Heartbeat、Apache、PostgreSQLなどのアプリケーション本体や、Pythonで作成されたWebアプリケーションは内蔵ディスクに、またDBなどのデータ領域は共有ディスクに配置しています。
|
|||||||||||||||
| 表2 ディスク構成 |
■リソースエージェントは?
Heartbeatが制御するリソースは次の一覧のとおりです。
|
|||||||||||||||||
| 表3 リソース一覧 |
設定したリソースエージェントの監視シーケンスについて、一部を簡単に説明しましょう。
Apache用では、設定したURLにhttpプロトコルで接続を行い、ヘルスチェック用に設定した文字列が返ってくるかを監視します。
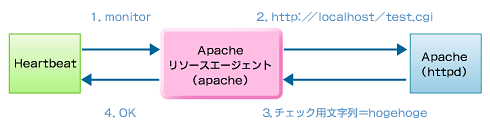 図4 Apache:monitor「OK」のシーケンス
図4 Apache:monitor「OK」のシーケンスまたPostgreSQL用は、“SELECT now();”のSQL文を実行し、return値が“成功”かどうかを監視します。
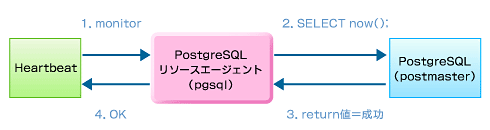 図5 PostgreSQL:monitor「OK」のシーケンス
図5 PostgreSQL:monitor「OK」のシーケンス■予想されるフェイルオーバー契機って?
Heartbeatでは各リソースを一定間隔で監視(monitor)し、想定外の値が返ってきたときにはフェイルオーバーするよう設定しています。
今回の事象は、Webブラウザからの接続で、Apacheの「Internal Server Error」が確認されています。従って、チェック用文字列は返ってこないでしょうから、Apacheのリソース故障と判断し、vigorへフェイルオーバーされるはずなのですが……?
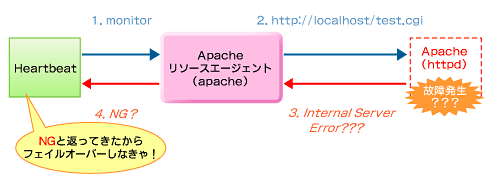 図6 予想されるApacheのmonitor「NG」のシーケンス
図6 予想されるApacheのmonitor「NG」のシーケンスコラム 共有ディスク排他制御「sfex」とは?
NTT OSSセンタでは、sfex(Shared Disk File EXclusiveness Control Program)を開発し、Linux-HA日本語サイト(http://linux-ha.org/ja/sfex_ja)においてGPLライセンスで公開しています。
sfexはアクティブ-スタンバイのHAクラスタ構成で共有ディスクの排他制御を行い、運用中にインターコネクト通信(ハートビート)が切れた場合に、両ノードがアクティブとなる「スプリットブレイン状態」を防ぐために使用します。
トラブルシューティングしてみたが……深まる謎
現象を確認すると、次のような事象が分かりました。
- Webブラウザでアプリケーションに接続すると、Apacheの「Internal Server Error」のエラー表示が出るが、正常にコンテンツが出るURLもある
- 両系のサーバにpingは通る
- 両系のサーバにSSHでログイン可能
ここから、一般的なトラブルシューティングらしい調査をしてみます。
まず、アクティブ系vividへSSHによる接続は可能だったため、ログイン後、以下のコマンドを実行してみました。
[root@vivid ~]# ls -al |
あらら、これはひょっとして……!? 実際にサーバのコンソール前に行ってみると、ディスクの赤ランプが点灯するとともに、次のような不吉なメッセージが、延々と無数に出ていました。
EXT3-fs error (device cciss/c0d0p1) in start_transaction: Journal has aborted |
どうやら原因は単純明快……内蔵ディスク故障が原因のようです。ただこうなると、強制終了させようとしても、コマンドさえ受け付けてくれない状態です。
[root@vivid ~]# reboot -nf |
本来であれば、SysRqキーによってディスクを同期させた後に電源オフしたいところですが、そのディスクが故障しているので、ここでは、最終手段のハードスイッチによる強制電源オフしかありませんでした。これでスタンバイ系vigorのHeartbeatがインターコネクト経由で故障を検出し、やっとサービスがフェイルオーバーしたのです。
と、ここでふと、われに返りました。
このようにコマンドも受け付けないような内蔵ディスク故障ならば、Apache、PostgreSQLのサービスは停止し、リソースエージェントがリソース故障を検出してフェイルオーバーするはずでは……? というより、そもそもHeartbeatやOS自体が機能しなくなり、スタンバイ系がアクティブ系のノード故障を検出してフェイルオーバーするはずでは……?
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。