文字化けに関するトラブルに強くなる【基礎編】:Oracleトラブル対策の基礎知識(5)(1/3 ページ)
今回は、「文字化け」に関する問題について説明します。コンピュータが扱うデータの中で文字データは最も親しみやすいものですが、歴史的な経緯や内部処理の関係から、残念ながら文字化けトラブルなどが発生することがあります。文字化けが発生したとき、オープンシステムではさまざまなソフトウェア製品が処理に介在することから、問題の切り分けに非常に時間を要し、対処が困難な場合が多いです。本稿で説明するOracle内部の文字データと文字コードの処理の方法を理解し、問題の切り分けと、一般的な問題への対処方法を理解しましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
Oracleにおける文字コードの扱い
文字コードとは?
連載バックナンバー
主な内容
- Oracleにおける文字コードの扱いデータベースキャラクタセット
NLS_LANG
文字コード変換 - 文字化けの原因と対処
文字化けの典型的な発生パターン
(関連キーワード:データベースキャラクタセット、NLS_LANG、文字化け、Unicode、シフトJIS、日本語EUC)
コンピュータが扱うすべてのデータは、0、1のビット列で表現されます。文字データも同様で、コンピュータで扱われるすべての文字は、その文字に対応付けられたあるビット列で表現されます。この「どの文字にどのビット列を割り当てるか?」を定めたルールが「文字コード」と呼ばれる体系です注1 。
注1:なお、本稿では理解のしやすさを重視し、文字コードに関する用語の説明を意図的に必要最小限としています。このため、文字コード一般に関してより詳細な理解が必要な場合、適宜書籍などで知識を補うなどの工夫をしてください。
現在日本で使用される文字コードにはいくつかの種類があり、文字コードによって同じ文字に割り当てられるビット列が異なります。表 1に日本で使用されている文字コードの例と、その文字コードにおいて、文字「あ」がどのビット列に対応するかをまとめています。なお、表 1では、ビット列を0、1からなる2進数表記ではなく、0、1、2.……9、A……Fからなる16進数表記で記載しています。
| 文字コード | 文字「あ」に対応するビット列 |
|---|---|
| シフトJIS | 0x82A0 |
| 日本語EUC | 0xA4A2 |
| UTF-8(Unicode) | 0xE38182 |
| 表1 日本で使用される文字コードの例と、文字「あ」に対応するビット列 | |
日本では複数の文字コードが存在し、OSによって、主に使用される文字コードが異なります。例えば、Windows系OSではシフトJISが主に使用され、UNIX系OSでは日本語EUCやUnicodeが主に使用されています。このため、文字データをOS間でやりとりする場合、文字コードの変換が必要となってくる場合があります。
先に記載したとおり、同じ「あ」という文字であっても文字コードごとに対応するビット列が異なりますので、ここでの文字コードの変換とは、ある文字コードでのビット列から別の文字コードのビット列への変換に相当します。
例えば、文字「あ」をシフトJISから日本語EUCに変換する場合、ビット列 0x82A0をビット列0xA4A2に変換します。このような変換は、あらかじめ定められた変換表に基づき実行されます注2。変換表には変換対象となるすべての文字について、変換前のビットと変換後のビットの対応関係が記載されています。
注2:例外的に置換表を必要とせず、算術的な処理によって変換が可能な場合もあります。
しかしながら、文字によっては、「ある文字コードには存在するが、ある文字コードには存在しない」ものもあります。例えば、Windows環境で使われるシフトJISには「(1)」という文字が存在しますが、一般的な日本語EUCには「(1)」は存在しません。
Oracleにおける文字コードの扱い
このように、さまざまなOS間で文字データをやり取りする際には、文字コードの変換が必要となります。Oracleが対象とするシステムにも、さまざまなOSが介在するため、システムの構成によっては文字コードの変換が必要となります。この際に、文字化けなどの問題が発生するわけですが、本セクションでは、文字コードの変換の前提となるOracleにおける文字コードの扱いについて説明しましょう。
Oracleでは、データベースが文字データを保存する際の文字コードを示す「データベースキャラクタセット」と、クライアント環境に適した文字コードを指定する「NLS_LANG」と呼ばれる2つのパラメータで、主に文字コードの扱いを決定しています。
データベースキャラクタセットとは、データベースに格納される文字データをある特定の文字コードで一元的に保管するような仕組みです。データベースキャラクタセットは、データベースの作成時に指定します。
文字データはデータベースではデータベースキャラクタセットで一元的に格納されますが、クライアントについては、クライアントが動作するOSごとに適した文字コードが異なることが多いため、クライアントそれぞれの環境に応じて動作用の文字コードを指定するNLS_LANGと呼ばれるパラメータを用意しています。
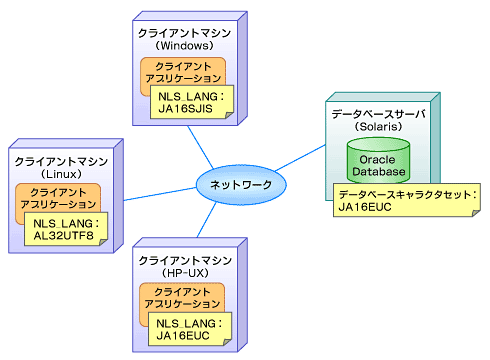 図1 データベースキャラクタセットとNLS_LANG
図1 データベースキャラクタセットとNLS_LANGデータベースキャラクタセット
データベースには、作成時に1つのデータベースキャラクタセットを指定します。典型的な日本語環境では、データベースキャラクタセットをデータベース作成後に変更することはできません。表2に日本語環境で使用される代表的なデータベースキャラクタセットを記載します。
| データベースキャラクタセット | 対応する文字コード | 補足 |
|---|---|---|
| JA16SJIS | シフトJIS | ― |
| JA16EUC | 日本語EUC | ― |
| JA16SJISTILDE | シフトJIS | (JA16SJISとはチルダ文字のマッピングのみが異なる注3) |
| JA16EUCTILDE | 日本語EUC | (JA16SJIS、EUCとチルダ文字のマッピングのみが異なる注4) |
| AL32UTF8 | Unicode注5、UTF-8エンコーディング | ― |
| 表2 日本語環境で使用される代表的なデータベースキャラクタセット | ||
注3:注4:JA16SJISTILDEの詳細は次回解説します。
注5:Oracle Database 9.1ではUnicode 3.0に、Oracle Database 9.2ではUnicode 3.1に、Oracle Database 10gR1では3.2に、10gR2は4.0に対応しています。
データベースに、CHARデータ型、VARCHAR2型、CLOB型、LONG型の文字データを格納した場合、文字データは、そのデータベースのデータベースキャラクタセットに対応する文字コードを用いて格納されます。例えば、文字「あ」をデータベースキャラクタセットJA16SJISのデータベースに格納した場合、0x82A0として格納され、また、データベースキャラクタセットJA16EUCのデータベースに格納した場合、0xA4A2として格納されます(図2)。
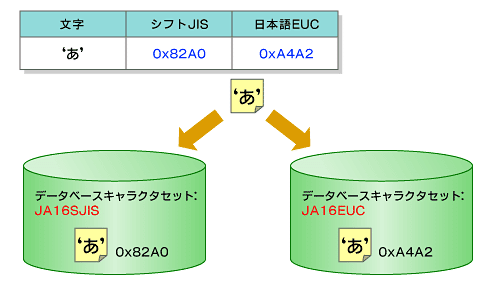 図2 データベースキャラクタセットと文字コード
図2 データベースキャラクタセットと文字コードデータベースキャラクタセットは、以下のSQLを実行することで確認できます。
SQL> SELECT * FROM V$NLS_PARAMETERS WHERE PARAMETER = 'NLS_CHARACTERSET'; PARAMETER VALUE -------------------------------------------------------- NLS_CHARACTERSET JA16SJIS
クライアント側で一般的に用いられる文字コードはシフトJIS、日本語EUCなどさまざまですが、データベース内の文字データは、データベースキャラクタセットの文字コードで一元的に格納されます。これは、Oracleでは、クライアントのNLS_LANG環境変数が適切に設定されてさえいれば、OracleクライアントとOracle Databaseの処理の中で、自動的に文字コードが変換されるためです。文字コード変換の詳細については、「文字コード変換」にて説明します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。