データモデル正規化の目的と役割:ゼロからのデータモデリング入門(9)(1/3 ページ)
第8回「ビジネス視点のデータモデリング」ではER図からビジネスを読み、ビジネスを反映したER図の描き方について解説しました。今回は、論理データモデリングの基礎技術となる正規化について説明します。
宿題の解答
まず、第8回の最後で出題した問題の解答を簡単に解説しましょう。

今回の出題では、細かなルール定義を決めていませんので、この解答例ではカーディナリティやオプショナリティについて言及しません。

また、解答から以下のビジネスルールを読み取ることができれば問題ありません。
【ビジネスルール】
契約形態としては、ライセンス契約とメンテナンス契約があり、ライセンス契約は見積を必要とするがメンテナンス契約は自動更新のため見積を必要としない。どちらの契約も顧客からの注文書に基づき処理を行う。
【確認事項】
1.見積と注文のリレーションシップは、ライセンスのみ見積が必要となるため、サブタイプのライセンス注文とのリレーションシップとなる。
2.見積と商品のリレーションシップが定義されており、ライセンス注文と商品の定義がないので、ライセンス注文時に商品構成が変更されることはない。
データベースの「正規化」とは
データベースにおける「正規化」という言葉は広く一般に知れ渡っているので、ご存じの方も多いと思います。正規化とは、エンティティの独立性を最大限に高めると同時に、エンティティのデータを挿入、更新、削除した場合に「データ間に不整合が生じないようなデータ構造」を実現することを目的として行います。第1正規化、第2正規化、第3正規化と進めながら、エンティティの分離と、リレーションシップや外部キー(フォーリンキー)の設定を繰り返すことで、データを整理していきます。
第1正規化
対象となるデータ群のプライマリキーを決め、繰り返し項目をそのプライマリキー(複写)とともに別のデータ群として分離します。
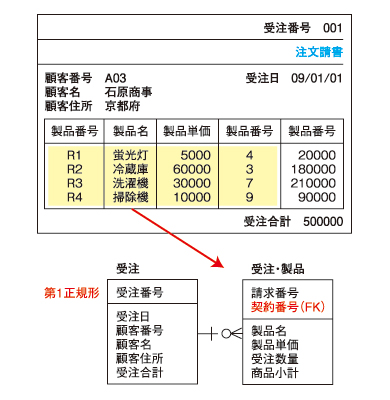 ●図2 第1正規化
●図2 第1正規化図2で見ると、繰り返し項目に該当するのは製品番号、製品名、製品単価のデータ群になります。これらの繰り返し項目を、元のキーの「受注番号」とともに分離しています。
第2正規化
第2正規化では、分離したデータ群の複合キーに、他のデータ群が完全に従属するかどうかを検証します。完全に従属しなければ、すなわち、部分従属の場合は、さらに別のデータ群として分離します。
例えば、図2の第1正規化後のデータ群を見てください。受注番号が決まっても製品名や製品単価は分かりませんが、製品番号が決まれば製品名や製品単価は決まります。従って、図3のように製品番号に部分従属している製品名、製品単価は、別のエンティティとして分離します。
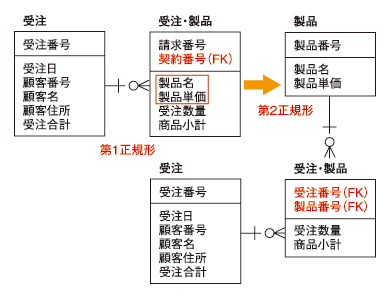 ●図3 第2正規化
●図3 第2正規化第3正規化
第3正規化では、第2正規化対象以外のデータ群でキー以外に従属する属性(アトリビュート)があるかを検証します。キー以外の従属関係を発見した場合は、さらに別のデータ群として分離します。
例えば、図4では第1正規化後の受注エンティティがその対象になります。顧客名や顧客住所は、受注番号ではなく顧客番号に従属しているため、別のエンティティとして分離します。
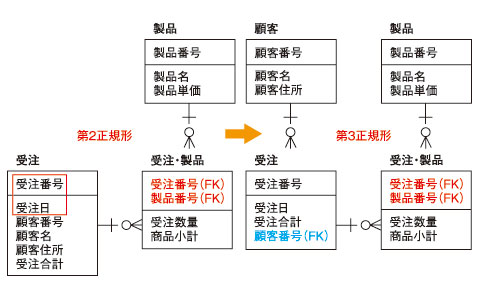 ●図4 第3正規化
●図4 第3正規化このように段階を踏んで、重複なく最小限の単位にデータを整理していくのが正規化という作業です。この正規化作業を「より効率的に」、「ビジネス活動をER図へ反映」させる手法としてアシストでは「正規化簡便法」を提唱しています【注1】。
【注1】アシストの4つのモデリング・メソッド「Tetra-Method(R)」に基づく正規化手法。SDIの佐藤正美氏によるTM(T字型ER手法)を参考にしている。
正規化簡便法の大きな特徴は、煩雑化するエンティティの仕分けや外部キー設定ルールなどを明示することにより、単純なミスを少なくし、正規化作業の品質を高め、ビジネスルールを抜け漏れなく反映したER図を作成(リレーションシップ定義)できることです。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。