CAT秘伝、バランスド・システムの考え方:真・Dr. K's SQL Serverチューニング研修(2)(2/3 ページ)
プロセッサ:NUMAを手に入れよ、そしてNum Runnableを見よ!
これは私見ではありますが、チューニングを考えるにはまずプロセッサの概念を知るところから始めるべきでしょう。
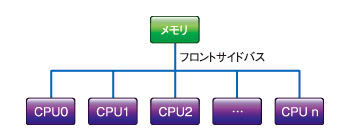 図1 SMPのアーキテクチャ
図1 SMPのアーキテクチャマルチプロセッサのアーキテクチャとして著名なのは、SMPとNUMAでしょう。SMP(Symmetric Multi Processor)は対象型と呼ばれ、各プロセッサの役割が完全に対称です。この方式ではすべてのプロセッサユニットから共通にメモリアクセスが行える必要がありますので、コア数が増えると、メモリとCPUをつなぐフロントサイドバスがネックになります。キャッシュのコンフリクトなどによる遅延が起きるわけですね。
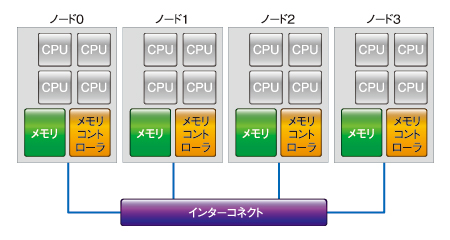 図2 NUMAのアーキテクチャ
図2 NUMAのアーキテクチャNUMA(Non-Uniform Memory Access、Non-Uniform Memory Architecture)は、複数のCPUで1つのノードを構成します。このノード単位でメモリ、CPUが独立しているので、ノードが1つのSMPシステムと考えていいでしょう。ノード間は高速なインターコネクトで接続しているので、拡張性が高い上にスケーラビリティに優れた方式です。特徴として、ノード内のメモリアクセスは大変速いものの、ノード間のアクセスは遅くなります。
【関連記事】
NUMA(Non-Uniform Memory Access、Non-Uniform Memory Architecture)
http://www.atmarkit.co.jp/icd/root/77/44603477.html
現在、汎用的なサーバー上のインテルやAMDのCPUはNUMAアーキテクチャを取り入れているものが大多数です。上記の特徴を見ても分かるように、その上で高速に動作をさせるためには、NUMAへのチューニング――ノード内のアクセスに閉じるような処理を行う――が必要です。これは、OSとDBエンジンがそれぞれ対応しなくてはなりません。SQL Serverは2000 SP4以降、NUMA対応が進められています。
実はこのNUMA対応がSQL Serverの大きな優位点です。第1回で触れた「SQL OS」が、このNUMAに対応しています。具体的には、各ノードに独立したスケジューラが用意され、ストアドプロシージャはノード内に残るようにチューニングしているのです。

ここから分かることはなんでしょうか。それは、「CPUの使用率」という指標はほとんど意味がないということです。SQL ServerのプロセッサがボトルネックになっているかどうかはCPUの使用率ではありません。むしろ見るべき項目は「Num Runnable」。スケジューラの空きを待っている数です。十分な数のコア(SQLOS上のスケジューラ)を持っていないと、SQL Serverはスケールしません。以前はこのNum Runnableはパフォーマンスモニタに表示されないものでした(CUIベースの表示しかできませんでした)。しかし、最新版の管理コンソール、もしくは動的管理ビューで確認できます。
第2世代のSQL Serverより、DBエンジン内のSQL OSでスケジューリングを行うよう改良したことは第1回で触れました。このSQL OSはCPUコアを階層化し、効率のよいマルチユーザー処理とクエリーの並列処理を実現できるよう、つまりNUMAアーキテクチャに最適化した形で改良されています。コアごとにスケジューラが用意されていますので、その待ち行列が存在することを示すNum Runnableを見ることで、CPUの数が十分なのかどうかが判断できるはずです。
メモリ:最大限搭載! 32→64ビット移行組は競合に注意
SQL Server 2000の時代は32ビット環境であり、メモリはクリティカルな共有資源でした。でも、それは過去の話です。いまやクライアントPCも64ビット環境になり、搭載したメモリオブジェクトがフラットな64ビットアドレス空間を利用可能です。これをケチることはありません。いまからシステムを構築する方はぜひ、メモリを最大限搭載しましょう。
しかし、2000時代のシステム――32ビット環境でAWEを活用していたシステム――をメンテナンスするエンジニアには問題があります。それはプロシジャキャッシュとバッファキャッシュの競合問題です。
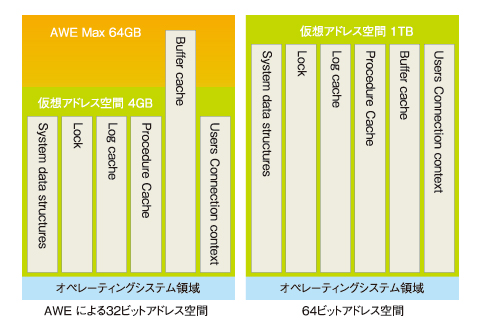 図4 64 ビット アドレス空間 vs AWE
図4 64 ビット アドレス空間 vs AWE上図を見てください。32ビットアドレス空間のAWEでは、バッファキャッシュは4Gバイトの仮想アドレス空間と、最大64GバイトAWEの空間を利用しています。そのため、プロシジャキャッシュとバッファキャッシュは別空間を利用していると考えていいでしょう。しかし、64ビットのアドレス空間では、最大1Tバイトの空間のすべてを、さまざまなキャッシュが共有します。そのため、単純にメモリ空間を64ビットに移行しただけでは、キャッシュの競合が発生する可能性があるのです。具体的には、アドホック(使い捨ての)クエリーとプリペアードクエリーが多い場合、メモリオブジェクトを大量に消費してしまいます。これらはガベージコレクタが動けばきれいになるのですが、しきい値を超えるまでは動きません。
これを踏まえたメモリのベストプラクティスをお教えしましょう。それは、「ユーザーデータベース容量の5〜10%をバッファキャッシュとして用意する」ことです。NUMAの場合、各ノードに最低8GBのメモリ(できれば16GB)を、SMPの場合はCPUコアあたり最低4GBのメモリを用意してください。
アドホッククエリーの動作は、動的管理ビューを用いてキャッシュプランの大きさと利用頻度を参照できます。この内容をしっかり把握しましょう。これがメモリチューニングの極意です。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。