Cにおける識別子の有効範囲と変数の生存期間:目指せ! Cプログラマ(9)(1/2 ページ)
変数や関数をプログラム中のどこから使うか、変数に保存した値をいつまで使いたいか、といった要求によって、これらの定義の仕方が変わります。今回は、要求に応じて変数や関数を定義できるようになるために必要な、型修飾子、識別子の有効範囲、変数の生存期間について学びます。
前回は関数について学びました。入力である引数、関数の処理、そして出力である戻り値を書くことで関数を作ることができました。処理の単位でまとめて関数にすることによって、処理の内容がはっきりし、何度でも同じ処理を呼び出せるようになります。
これまで変数や関数を定義し、それをプログラムの中で使ってきました。しかし定義したからといって、「いつでもどこからでも使える」というわけではありません。より便利に使うためには、オブジェクトの特徴をより詳しく定義したり、使用できる範囲を制限したりすることが必要になってきます。今回は変数や関数を特徴付けるための“修飾子”と、変数や関数の使える範囲について学びましょう。
型修飾子
型修飾子は、変数の型をより具体的に説明するためのキーワードです。型修飾子には次の3つがあります。
- const
- restrict
- volatile
型に型修飾子を組み合わせることで、型の意味がより具体的になり、用途を明確にすることができます。例えば型intに修飾子constを組み合わせることで、ただのintではない、この後に説明するような「constという特徴を持ったint型」を表現することができます。
型修飾子はこのように型の意味を具体的にするために用意されているので、常に型とともに用いられ、単独で登場することはありません。
ここではconstとvolatileについて説明します。restrictについてはもう少しあとで取り上げます。
(1) const
constで修飾された型のオブジェクト(変数)は、プログラムの中で値を変更できなくなります。つまり、次のような操作ができません。
const int a = 0; // const int型の変数aを定義して初期化する。 a = 1; // コンパイルエラー! const int型の変数は値を変更できない。
この方法は関数の引数でも使えます。
#include <stdio.h>
#include <stdlib.h>
double add(const double a, const double b) {
// a = 0.3; エラー
return a + b;
}
int main(void) {
double x = 0.1;
double y = 0.2;
double sum = add(x, y);
printf("%f\n", sum); // 0.300000
return EXIT_SUCCESS;
}
仮引数aには0.1が、bには0.2が入ります。関数addの中ではaとbの値を変更することができません。これには2つのメリットがあります。
- 誤ってaとbの値を変更してしまうようなコードを書いてしまうことがない(たとえ書いてしまってもコンパイラが検出してくれる)
- 関数addの実装を知らない人にも、関数add内でaとbの値が変更されないということが明確に分かる
後者のメリットについては、今までに説明した範囲内では問題になりません。関数addの中でaとbの値が変更されても、mainの実行には何も影響を及ぼさないからです。
しかしポインタ(ポインタ型については今後の記事で説明する予定です)というものを使用することによって、呼び出し側の変数の値を、呼び出された関数の中で変更できるようになります。そのときには、変数の値が変更されるのか、それとも変更されないのか、ということを関数を呼び出す側に明確に示すことは、その関数を使う人にとって、とても有益な情報になります。こうしたちょっとした気遣いで関数の使い勝手はとても良くなりますから積極的に使いましょう。
(2) volatile
今まで扱ってきた変数は、値を変更するためには代入演算子('='や'+='など)を使っていました。Cコンパイラも、そのことを前提にコンパイルを行ないます。
変数の型にvolatile修飾子を付けると、この変数は次のような特徴を持つことを表します。
- プログラムのコードで変数の値を変えなくても、勝手に値が変わる可能性がある
- 変数の値を変えようとすると、値が変わる以外の動作をする可能性がある
もちろん、プログラマがまったく知らない動作をしてもらっては困ります。その変数がどのような動作をするか知らないのはCコンパイラであって、プログラマは知っていなければなりません。
volatileは主に組み込みプログラミングで利用します。ある特殊な変数はプログラムが動いているCPUとは別のデバイスの状態を表しており、そのデバイスの状態が変わるとその変数の値が変わる、というようなケースがあります。
プログラマはデバイスの状態が変わったらある変数の値が変わるということを知っていますが、Cコンパイラは知りません。もしCコンパイラが「勝手に値が変わる可能性がある」ことを知らないままコンパイルすると、プラグラマに取って都合悪く解釈されてしまう場合があります。
例えば次のコードはどうでしょうか。
int main(void) {
int a = 1;
if (a) { // if文は条件式の値が0以外なら真となり、続くブロックが実行される。
printf("このメッセージは表示される?\n");
}
return EXIT_SUCCESS;
}
変数aの値が変わらないならば、if文のブロックは必ず実行されます。コードを見る限り変数aの値を変更していませんから、ifの条件式を評価するのもはっきり無駄と言えます。賢いCコンパイラならばこれは無駄であると解釈し、if文を削除してprintfを必ず実行するようなプログラムを生成してくれます。このような処理を“最適化(optimization)”と呼びます。
この最適化が行われても記述通りにプログラムは動作しますし、if文がなくなる分だけプログラムの動作は速くなります。しかし変数aが「勝手に値が変わる可能性がある変数」だとしたら困ったことになります。if文を実行する前にaの値が0になっている可能性があるからです。ということは、賢いCコンパイラでもif文を勝手に削除してもらうわけにはいきません。
このような場合にvolatileを使用します。volatileで修飾された型を持つ変数はこのような最適化が行われないようになります。
int main(void) {
// volatile修飾子をつけたので最適化されない。
volatile int a = 1;
if (a) {
printf("このメッセージは表示されるかもしれないし、表示されないかもしれない。\n");
}
return EXIT_SUCCESS;
}
識別子の有効範囲(スコープ)
オブジェクト(変数)や関数などには名前が付いています。これを識別子と呼びます。
直感的には、1つの識別子は1つのオブジェクトや関数を指し示していると考えられますが、実際にはそうではありません。同じ識別子が複数のオブジェクトや関数を表すことがあります。
例えば、「誰か知らない人が書いたプログラムで使用されたオブジェクトの識別子は、自分のプログラムの中では使えない」ということになると、相当に不便です。そのため識別子には、その識別子が有効となる範囲(スコープ)が決まっており、その有効範囲の中でのみ、ある1つのオブジェクトや関数を指し示しています。
(1) ブロック有効範囲
最も直感的な有効範囲はブロック(複合文)でしょう。これを一般的に“ブロック有効範囲”あるいは“ブロックスコープ”と呼びます。先ほどのサンプルで有効範囲を確認してみます。
#include <stdio.h>
#include <stdlib.h>
double add(const double a, const double b) {
// a = 0.3; エラー
return a + b;
}
int main(void) {
double x = 0.1;
double y = 0.2;
double sum = add(x, y);
printf("%f\n", sum); // 0.300000
return EXIT_SUCCESS;
}
9行目から始まる関数mainでは、x、y、sumという3つのdouble型のオブジェクトを宣言しています。これらの識別子の有効範囲は「宣言された場所」から「ブロックの終了(この例では関数の終了と同じ)」までです。
- x : 10行目の宣言の後ろから15行目の関数終了を表す'}'の前まで
- y : 11行目の宣言の後ろから15行目の関数終了を表す'}'の前まで
- sum : 12行目の宣言の後ろから15行目の関数終了を表す'}'の前まで
識別子sumの有効範囲は12行目からですから、10行目や11行目で識別子sumを使用することはできません。もちろん、関数addの中で使用することもできません。もし関数mainとaddの上下の位置が逆でも同じで、他の関数で宣言された識別子を使用することはできません。
本連載の第3回で「変数を利用する前に必ず宣言が必要」と大雑把な説明をしましたが、ここで有効範囲について正確に理解するようにしてください。なお、宣言をした行から変数の有効範囲が開始されるということは当たり前のように思うかもしれませんが、これはプログラミング言語によって違います。使用する変数名の宣言はブロック内のどこでもよい、という仕様となっているものや、そもそも宣言が必要ないものもあります。気を付けましょう。
ここでは関数におけるブロックの例でしたが、他のブロック、例えばif文に続くブロックやfor文のブロックなどでも同じです。
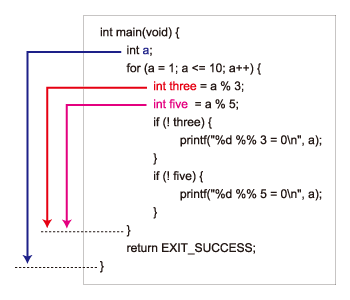 ブロック有効範囲
ブロック有効範囲オブジェクトの有効期間にはブロック有効範囲の他に、“ファイル有効範囲(ファイルスコープ)”と“プロトタイプ有効範囲(プロトタイプスコープ)”というものもあります。
(2) ファイル有効範囲
変数は関数の外側にも置くことができます。この場合、変数の識別子はファイル有効範囲を持ちます。ファイル有効範囲は変数が宣言された場所から、Cソースファイルの終わりまでです。
 ファイル有効範囲
ファイル有効範囲ファイル有効範囲は、複数のソースファイルを結合してひとつのプログラムとするときに意識する必要があります。あるソースファイルで宣言された識別子は、別のソースファイルで参照することはできません。
(3) プロトタイプ有効範囲
これはあまり意識する必要はありませんので簡単に紹介します。
プロトタイプ有効範囲は、関数プロトタイプで使われるオブジェクト識別子の有効範囲です。プロトタイプ宣言の仮引数に使われる識別子は、その宣言の中でだけ有効です。関数プロトタイプ宣言で利用した識別子を他の場所で利用することはできません。
(4) 有効範囲の注意事項
このように宣言した場所によって変数の識別範囲が異なりますので、どの場所でどの識別子が有効になっているかを把握することは重要です。
まず、同じ名前と同じ有効範囲を持つ複数の識別子を宣言することはできません。
void func(void) {
int a = 0;
// ...
int a = 1; // コンパイルエラー! redefinition of 'a'. ('a'が再定義されています。)
}
同じ名前であっても別の有効範囲を持つ複数の識別子を宣言することはできますので、同じ識別子を持つ複数のオブジェクトの有効範囲が重なることがあります。
// ファイル有効範囲を持つ変数aを宣言した。
int a = 0;
void func(void) {
// ブロック有効範囲を持つ変数aを宣言した。
int a = 1;
// a = 0? a = 1?
printf("a = %d\n",a);
}
この例では2つの同じ識別子を持つ変数aが登場します。識別子は同じですが有効範囲は異なり、一方がファイル有効範囲で、もう一方がブロック有効範囲です。関数funcの中で識別子aを参照しようとしていますが、この箇所では識別子aを持つ両方の変数について有効範囲に入っています。
このように複数の識別子が有効な場所では、内側の有効範囲を持つ識別子が参照されます。ブロック有効範囲はファイル有効範囲の内側にあります。つまりブロック有効範囲を持つ識別子aが参照されるため、この例のprintf関数呼び出しでは「a = 1」が表示されます。このことはブロックが入れ子になっている場合でも同じで、それぞれのブロックで同じ識別子のオブジェクトを宣言した場合、内側のブロックでは内側の変数が参照されます。
なお、識別子の有効範囲が重なっているところでは、外側の識別子を参照する方法はありません。
また、オブジェクト(変数)と関数の有効範囲については扱いが同じなので、同じ識別子で同じファイル有効範囲を持つ変数と関数を同時に宣言することはできません。しかしラベルの有効範囲については扱いが別になっているので、同じ識別子で同じブロック有効期間を持つ変数とラベルは同時に宣言することができます。
int a = 0;
// 同じ識別子、同じファイル有効範囲を持つ変数や関数を、複数宣言することはできない。
/* double a = 0.0; コンパイルエラー! */
/* void a(void) {} コンパイルエラー! */
void func(void) {
// 有効範囲が異なればOK。
int a = 0;
// ラベルは別の扱いなのでOK。
a:
// 同じ識別子、同じブロック有効範囲を持つラベルを、複数宣言することはできない。
/* a: コンパイルエラー! */
}
コラム●変数の宣言位置と型名の省略
C99より前のCでは、変数はブロックの先頭にまとめて宣言する必要がありました。C99ではその制限はなくなっているため、次のようなコードを書くことができます。
#include <stdio.h>
#include <stdlib.h>
int a = 1;
int main(void) {
printf("a = %d\n", a); // a = 1
int a = 2;
printf("a = %d\n", a); // a = 2
return EXIT_SUCCESS;
}
C99に対応したコンパイラであれば、このコードは問題なくコンパイルできます。GCCなどの一部のコンパイラでは、C99に対応していなくても独自拡張で対応しているものもあるようです。Visual C++は残念ながらC99に対応していないため、このコードはエラーになります。変数の宣言はブロックの先頭にまとめて書きましょう。その場合でも有効範囲については同じと考えて差し支えありません。
また、C99より前のCでは、オブジェクトの宣言時に型名を省略することができました。省略するとintとして解釈されます。つまり「const a = 1」と書くと、変数aはint型として扱われていました。C99では省略できなくなったため、「const int a = 1」と書く必要があります。C99より前のコードではintを省略して書かれたものがあるかもしれませんから、覚えておくと良いでしょう。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。