「データ」をめぐって聞こえてきた2つの新しいメッセージ:Database Watch(2013年4月版)(1/2 ページ)
今回はデータプラットフォームについて、直近で製品発表のあった2社のトレンドをウォッチ。いずれも“データ”の扱い方について、新しいメッセージを示すものとなりました。
当初IT業界用語だった「ビッグデータ」。最近では地上波TV番組のタイトルに登場するなど認知度は高まりました。今はいかに実現するかという実践面に目が向けられているようです。今回はビッグデータ戦略を発表した2社を紹介しましょう。「包括的にデータを処理できるプラットフォーム化」を打ち出したIBMと、「誰もがデータサイエンティスト化」を掲げるマイクロソフトです。
DB2 V10.5に搭載されたBLUアクセラレーション
IBMは近年ビッグデータに力を入れています。4月11日には情報管理製品の年次イベント「Information On Demand Conference 2013」(以下、IODC 2013)を開催しました。テーマとして掲げたのはやはり「ビッグデータ」。イベントでは事例を通じた実践的な技術情報提供が多く盛り込まれていました。
IBMがビッグデータ戦略で示しているのが「プラットフォーム化」です。
ビッグデータは構造化データだけではなく、非構造型のソーシャルなデータ、センサが送出するデータやシステムログなど、絶え間なく生まれるマシンデータ、あるいは動画や音声など、幅広く処理しなくてはなりません。IBMはあらゆるデータを統合的に把握し処理できるビッグデータのプラットフォームを提案し、それを構成するためのInfoSphereやPureData SystemsなどIBMのテクノロジー製品群を紹介していました。
その6日前、4月4日には、データベース管理ソフトウェアの最新版「DB2 V10.5」の発表もありました(関連記事1、関連記事2)。同社専務執行役員 ソフトウェア事業担当のヴィヴェック・マハジャン氏(写真)が「今年最も重要なイノベーションとなる発表」と胸を張っていたのが印象的でした。

IBMはDB2 V10.5を「ハイブリッド・データベース」と表現していました。ハイブリッドとは従来の業務処理に加え、分析処理もできるという意味です。
余談ですが、DB2は5〜6年前にも「ハイブリッド」化を進めていました。ただし当時はリレーショナル(テーブル構造)とXML(ツリー構造)のハイブリッド。「pureXML」とも呼ばれていました。思うに、RDBは脈々と続いた技術の延長にあり、企業システムで不可欠な存在でもあります。システムの中枢にあるからこそ、過去から続く技術を継承しつつ、新しい技術を取り込み続けていく使命のようなものがあるのかな、と思いました。
閑話休題。IODC 2013ではIBMコーポレーション ソフトウェアグループ インフォメーションマネジメントのティム・ヴィンセント氏(写真)がデータベースの新製品群について詳しく解説してくれました。同氏はIBM インフォメーションマネジメント部門におけるCTO(最高技術責任者)でもあります。

DB2 V10.5に搭載された分析処理を高速化する技術をIBMは「BLUアクセラレーション」と呼んでいます。特徴的な圧縮技術やデータ抽出手法、並列処理などを組み合わせ、分析処理の高速化を実現しています。シンプルに実行できるのもメリットです。なおBLUアクセラレーションはDB2のためだけの技術ではありません。DB2 V10.5のほか、Informix 12.1 TimeSeriesにも実装され、今後ほかの製品にも波及するそうです。
同社研究所のテストによると、BLUアクセラレーションでレポーティングや分析の処理は8〜25倍高速化したという結果が得られました。それをどのような技術を組み合わせて実現したのかをもう少し詳しく見ていきましょう。BLUアクセラレーションでは下図のように処理が流れていきます。最初のデータ量は10TBとします。
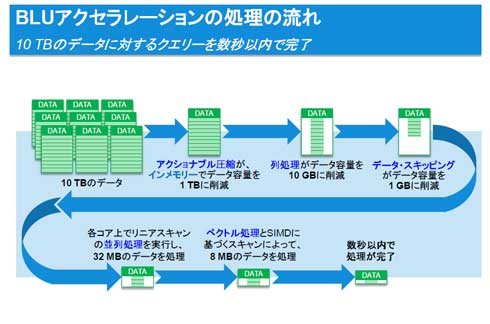
最初の「アクショナブル圧縮」はデータの順序を保持して圧縮する機能で、圧縮済みのデータを解凍せずデータを処理できる技術です。解凍しなくて済むなんて圧縮データの概念がひっくり返りそうです。そしてインメモリカラム型の列処理を経て、データスキッピングは旧ネティーザのZoneMapに由来する技術だそうです。これらの処理を経て、10TBのデータはみるみるうちに1GBまで小さくなります。その小さくなったデータを並列処理し、最後はベクトル処理です。結果的に10TBのデータを数秒程度で処理できてしまうとのことです。
ベクトル処理はCPU能力を最大限活用する手法として有効です。SIMD演算ができるプロセッサが対象となります。1つの命令で複数のデータを処理できるので、処理速度向上に寄与します。前に紹介したVectorwiseもこの機能を活用していましたね。
DB2のカーネルにBLUアクセラレーションがどのように組み込まれているのかを示したのが下図です。従来型の機能と分析用のBLUアクセラレーションが共存しています。ストレージには従来型となる行形式のテーブルと、圧縮とエンコードが行われた行われたカラムストア型のテーブルのどちらも入ってハイブリッドとなっています(XMLとハイブリッドになったときもまさにこうでした)。
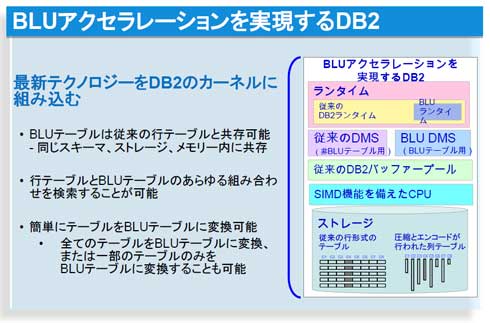
ところでBLUアクセラレーションが有効になるカラムストア型テーブルはどう作るのでしょうか――つまり、従来型のトランザクション向けの処理と分析向けの処理は何がスイッチになるのでしょうか。答えは「create table」の末尾に「ORGANIZE BY COLUMN」を1行追加するだけです。このシンプルさも驚異的です。テーブルを作成してロードするだけ。
このBLUアクセラレーションのインパクトが大きいため、分析機能にばかり目が向いてしまいますが、新機能はこれだけではありません。V10.1からDB2に標準搭載されるようになった「pureScale」を機能拡張されました。OLTPワークロードに応じて最適化できるようになり、より大規模にも拡張できるようになりました。
使い勝手に関してはOracle DatabaseからDB2への移行しやすさも挙げられています。IBMによると「DB2 V10.5はOracle PL/SQLとの間で平均98%の互換性を実現」しているといいます(同社内テスト結果より)。SAP AGがOracleからDB2に移行した移行事例では、アプリケーションのレスポンスタイムが40%短縮、データベースサイズを22%削減できたそうです。
最後にもう1つ。DB2ではなく、PureData Systemsについてのニュースもありました。これまでPureDataは3兄弟だと紹介してきましたが、新しい弟が登場するようです。それが「PureData System for Hadoop」です。提供開始時期は2013年第3四半期を予定しているとのことでまだちょっと先です。詳細はまだ多く語られていませんが、おおざっぱにいうと、IBM InfoSphere BigInsightsの技術を搭載した製品だそうです。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。