僕たちが分散KVSでファイルシステムを実装した理由:分散KVSを使ったファイルシステム「okuyamaFuse」(1)(2/3 ページ)
データへのアクセスの仕組み:書き込み
まず、データを保存(書き込み)する動きを見ていきましょう。
(1)ユーザーがデータをファイルシステム上に保存しようとします。例えばテキストエディタでファイルを保存する場合を想像すると分りやすいでしょう。
(2)保存されるデータの先頭から順次記憶装置に書き込んでいきます。
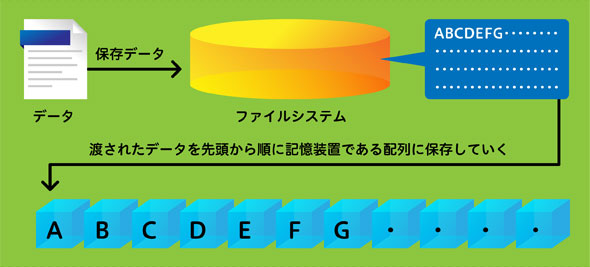
(3)渡されたデータが全て保存できるまで(2)を繰り返します。
データへのアクセスの仕組み:読み込み
次にデータの読み込みを見ていきましょう。
(1)データを利用するユーザーから読み込みを開始したい場所とサイズが指定されます。
例えばテキストエディタなどの場合、先頭から全てのデータを読み込もうとします。一方で、Linux環境で使われるtailコマンドなどは、ファイルの途中など、所定の位置からデータの最後までを読み込むことができます。これは開始位置を指定しているからこそできる動作になります。
(2)指定された位置から指定されたサイズ分データが読み込まれます。
先ほどの配列から読み込みます。
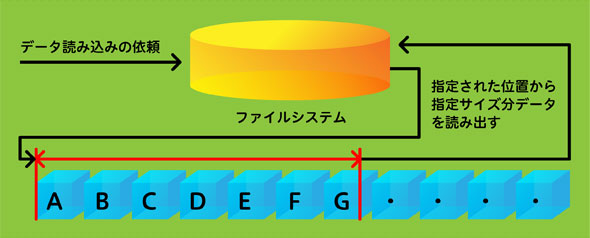
(3)まだデータを全て読み込めていない場合は、ユーザーから新たな開始位置とサイズが指定され(1)と(2)を繰り返します。
上記がデータの保存と読み出しのおおまかな流れです。
実際のデータの読み書きは、1バイトずつではなく一定の単位でまとめて扱われます。また、即記憶装置に保存するのではなく、「バッファリング」という仕組みを利用して、ある程度保存するデータがたまるのを待ってから記憶装置に保存する仕組みも存在します。読み出しに関しても、一度記憶装置から読み込んだデータをメモリ上に蓄えておき、2回目以降のメモリ上のデータを参照することで読み込みを高速化する仕組みなどがあります。これらの仕組みも全て含めてファイルシステムの中に含まれています。ここでは詳しく説明しませんので、興味を持った方は、ぜひご自分で調べてみましょう。
物理デバイスの仕組み
このように、ファイルシステムを配列に置き換えると、普段ソフトウェアのプログラムを書かれる皆さんにもイメージしやすいのではないでしょうか。この配列が実際には記憶装置となります。PCに搭載されたHDDの場合もありますし、ネットワーク越しのファイルサーバにあるHDDかもしれませんが、いずれにしても、開始位置とサイズによってデータへのアクセスが実現していることが分かります。
では実際に物理的なデバイスであるHDD上ではどのようなことが起こっているのでしょうか?
下の図4はHDDディスクのデータが保存されているイメージです。

HDDの場合はこのように内部の円盤状の装置(磁気記憶装置)で実際のデータを管理しています。データの読み書きは手前にあるヘッドといわれる装置で行っています。位置を指定して読み出す動作を例に取ると、図5のように、データを実際に読み書きするヘッダが取り付けられているアクセスアームの下に目当てのデータが来ると同時に読み出しが行われます。そのため、アクセスアームと磁気記憶装置が物理的に動く時間だけ待たなければいけません。この待ちの時間が長ければそれだけファイルシステムの動作が遅く感じられます。

では、最近一般的な個人のPCにも多く搭載を始めたSSDの場合どうでしょう?
SSDの場合記憶装置内の仕組みが全く異なります。先ほどのHDDが持っていた記録装置がフラッシュメモリと言われる記憶素子に変わり、プラッタが存在しません。フラッシュメモリは物理的な移動などを伴わずにデータを取り出すことが可能であり高速です。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。