Azureの「SQLデータベース」とSQL Serverは何が違う?/Pivotal HD 2.0:Database Watch(2014年6月版)(2/2 ページ)
HAWQ強化とGemFire XDを統合した「Pivotal HD 2.0」
2014年6月2日、Pivotalジャパンは「Pivotal HD 2.0」の国内販売開始を発表しました。Pivotalジャパンの松下正之氏が解説してくれました。
 Pivotalジャパン 技術統括部 シニアテクニカルコンサルタント 松下正之氏
Pivotalジャパン 技術統括部 シニアテクニカルコンサルタント 松下正之氏詳細に入る前にPivotalの大切なコンセプト「Data Lake」について触れておきましょう。
Pivotalはクラウドやビッグデータに着目し、クライアント/サーバーモデルに継ぐ、次世代の「第3のプラットフォーム」を視野に入れて設立した企業です。特に重視しているのがデータ。
Pivotalは自社の技術でデータのプラットフォームを構築しようと考えています。そのイメージを「Data Lake」と呼んでいるようです。
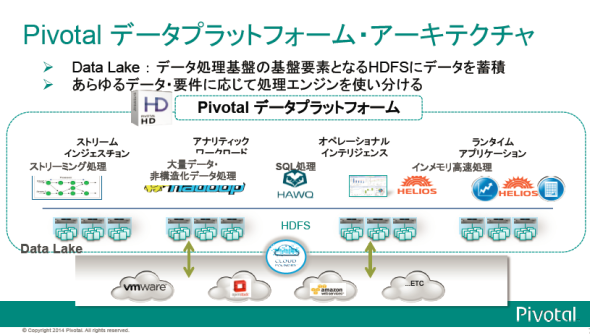 (資料提供:Pivotalジャパン)
(資料提供:Pivotalジャパン)「Data Lake」で特徴的なのは、Apache Hadoopが採用している分散ファイルシステム「HDFS」にデータが格納されている点です。Pivotalの製品はHDFSのデータに対して多様な要件や処理が可能となるように発展してきています。PivotalはHDFSに「賭けている」といってもいいでしょう。
ではあらためて、今回発表された「Pivotal HD 2.0」とは何かを見ていきましょう。Pivotal HD 2.0はApache Hadoop 2.2.0をベースにしたHadoopディストリビューションの一種です。Pivotalが独自の機能を追加しています。今回は主にHDFSに対してSQLでアクセスする「HAWQ(HAdoop With Query)」を強化し、同社のインメモリ処理エンジン「Pivotal GemFire XD」を統合したのが特徴です。
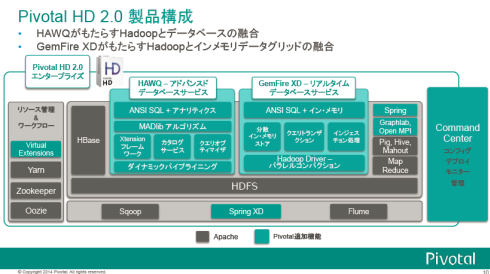 (資料提供:Pivotalジャパン)
(資料提供:Pivotalジャパン)「HAWQ」を見ていきましょう。
HAWQはPivotal HDにSQLでアクセスできるようにしたもので、HAWQ単体で見ると日本における正式版は2014年2月の「Pivotal HD Enterprise」と同時に提供開始となりました。今回は分析機能を強化したとのことです。
HAWQは最近注目されている「Hadoop on SQL」技術の一つです。SQLはRDBを前提にした問い合わせ言語ですから、その前提に当てはまらないHDFSでSQLを使うのは「離れ業」といってもよいほどです。
昨今、HDFSが急速に広まりましたが、当初はデータにアクセスするにはJavaなどプログラミング言語を用いる必要がありました。データベースアプリケーション開発者はSQLには慣れていても、Map/Reduceによる分散処理には不慣れです。そこでHDFSでもSQL(に近い形)でアクセスしたいという要望があり、手段がいろいろと出てきました。例えばApache HIVE(関連記事)やCloudera Impala(関連記事)などです。
SQLによる問い合わせはRDBMSなら当たり前のことですが、ファイルシステムであるHDFSに対して実行するのは技術的には難しいはずです。どうやっているのでしょうか。
松下氏は「GreenplumDB(関連記事)の技術を有効活用した。HAWQの技術がリレーショナルデータベースからきているからこそ、高速な処理ができるなどの強みがある」と話していました。具体的にはHAWQのクエリオプティマイザーや並列処理による高い性能などに当たるようです。
もう一つはインメモリ処理エンジン「GemFire XD」です。今回の「Pivotal HD 2.0」で初めてPivotal HDに統合されました。もともとGemFireはインメモリ型KVSで、基本的にはデータアクセスはJavaやC++などを使うものでした。そこにSQLラッパーとHDFS連携機能が加わったのが「GemFire XD」です。
今回の「Pivotal HD 2.0」でPivotalの「Data Lake」は着実に豊かな湖へと発展してきたように見えます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。