9.4で盛り込まれる新構文とPostgreSQL本体のレプリケーション機能強化:PostgreSQLガイダンス(3)(2/4 ページ)
行ロックエラーのメッセージ拡張
PostgreSQL 9.4では、行ロックに関するエラーメッセージが改善されています。どの行でロック待ちしているのかという情報がメッセージに含まれるようになりました。
テーブル「t1」の「id = 1」の行を行ロックしておいた上で、新たな接続から以下のように、ロックタイムアウトを付けてt1テーブルの全行UPDATEを試みた場合、行ロックがあるため、タイムアウトエラーになります。この時のエラーメッセージに「CONTEXT:……」というメッセージが加わるようになりました。
db1=# BEGIN; db1=# SET LOCAL lock_timeout TO '10s'; db1=# UPDATE t1 SET v = 'x'; ERROR: canceling statement due to lock timeout CONTEXT: while locking tuple (0,1) in relation "t1"
上記の「(0,1)」というのは、行の物理位置を示すシステム列「ctid」の値です。以下のようにして、当該行を確認できます。
db1=# SELECT * FROM t1 WHERE ctid = '(0,1)'; id | v ----+--- 1 | 1 (1 row)
このCONTEXTメッセージは、postgresql.confでlog_lock_waitsを指定して、指定時間以上のロック待ちをログ記録するようにした場合にも同様に出力されます。また、デッドロックを検知した場合にも出力されます。
以下は出力例です。
2014-10-22 10:46:34 JST [3786] LOG: process 3786 still waiting for ShareLock on transaction 1894 after 3000.315 ms 2014-10-22 10:46:34 JST [3786] DETAIL: Process holding the lock: 3605. Wait queue: 3786. 2014-10-22 10:46:34 JST [3786] CONTEXT: while updating tuple (0,1) in relation "t1" 2014-10-22 10:46:34 JST [3786] STATEMENT: UPDATE t1 SET v = 'xx';
2014-10-22 10:59:37 JST [3975] ERROR: deadlock detected
2014-10-22 10:59:37 JST [3975] DETAIL: Process 3975 waits for ShareLock on transaction 1897; blocked by process 3973.
Process 3973 waits for ShareLock on transaction 1898; blocked by process 3975.
Process 3975: SELECT id FROM t1 WHERE id = 1 FOR UPDATE;
Process 3973: SELECT id FROM t1 WHERE id = 2 FOR UPDATE;
2014-10-22 10:59:37 JST [3975] HINT: See server log for query details.
2014-10-22 10:59:37 JST [3975] CONTEXT: while locking tuple (0,1) in relation "t1"
2014-10-22 10:59:37 JST [3975] STATEMENT: SELECT id FROM t1 WHERE id = 1 FOR UPDATE;
2014-10-22 10:59:37 JST [3973] LOG: process 3973 acquired ShareLock on transaction 1898 after 8160.316 ms
2014-10-22 10:59:37 JST [3973] CONTEXT: while locking tuple (0,2) in relation "t1"
2014-10-22 10:59:37 JST [3973] STATEMENT: SELECT id FROM t1 WHERE id = 2 FOR UPDATE;
遅延レプリケーション
ここからはレプリケーション機能の改善について取り上げます。
PostgreSQLでは、バージョン9.0からレプリケーション機能を本体に盛り込んでいます。その後、バージョンを重ねるごとに少しずつ機能を改善してきました。
PostgreSQL 9.4では、スタンバイサーバーの設定ファイル「recovery.conf」に「recovery_min_apply_delay」という設定項目が追加されています。これは、指定した時間だけ、スタンバイサーバーへの更新内容の適用が遅延されるというものです。
この機能は、ヒューマンエラーによるデータ破壊に対する対策に利用できます。あらかじめrecovery.confのrecovery_min_apply_delayの値を'1d'(=1日)としたスタンバイデータベースを作っておけば、うっかりデータを壊してしまった場合でも、1日前のデータを保持しているスタンバイサーバーが持つデータベースから必要な部分を取り出してデータ復旧に利用できます。
なお、本設定をしたとしても、更新内容のデータ転送そのものは遅延しません。遅延するのはスタンバイデータベースへの適用だけです。従って、遅延時間が長い場合には、その間に生成されたトランザクションログファイル(WALファイル)がスタンバイサーバーに保持されることになります。
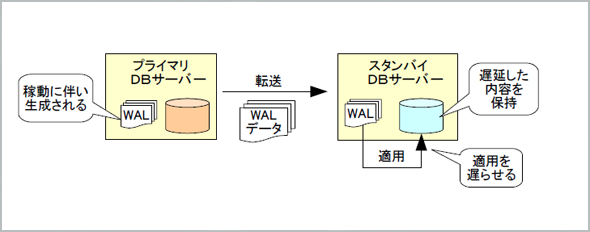 図1 遅延レプリケーション WALファイルそのものは転送するが、スタンバイサーバーへの適用は任意のタイミングになるため、ヒューマンエラー時でもリカバリが容易になる
図1 遅延レプリケーション WALファイルそのものは転送するが、スタンバイサーバーへの適用は任意のタイミングになるため、ヒューマンエラー時でもリカバリが容易になるCopyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。