Cephがスケールできる理由、単一障害点を排除する仕組み、負荷を減らす実装:Ceph/RADOS入門(4)(4/4 ページ)
オブジェクトをレプリケーションする際の挙動
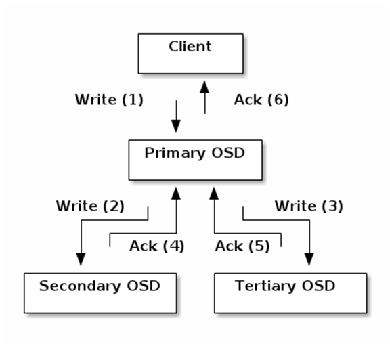
クライアントは、CRUSHアルゴリズムでプライマリOSDを特定します。プライマリOSDというのは、レプリカ番号に0を指定して特定されたOSDです。クライアントは、オブジェクトをプライマリOSDのみに書きます。
 Primary-copyレプリケーション動作。出典:
Primary-copyレプリケーション動作。出典:プライマリOSDは、CRUSHアルゴリズムで各レプリカを持っているOSDを特定します。各レプリカを持っているOSDとは、レプリカ番号に1、2、…、Nを指定して特定されたOSDです。Nはオブジェクト冗長度を指します。
プライマリOSDは、オブジェクトを各レプリカを持っている各OSDにコピーします。プライマリOSDは、オブジェクトがコピーされたことを確認するとクライアントに応答します。
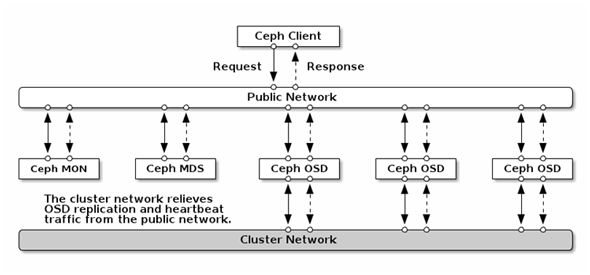
クライアントと各OSDは、パブリックなネットワークで接続されます。各OSD間は、パブリックネットワークとは別のネットワーク(クラスターネットワーク)で接続する構成が可能です。この場合、OSD間のオブジェクトコピー(レプリケーション)やリバランスのためのオブジェクトの移動はクラスターネットワークを使用して行われます(Ceph/RADOSのクライアントの挙動については第2回を参照ください)。
 出典:
出典:ペタバイトを超えるために活用するストレージノードの「インテリジェンス」
OSDの計算リソース(CPUやメモリ)は、クライアントへのサービス提供やOSD間のオブジェクトコピー(レプリケーション)やリバランスの他にも使用されます。分散ストレージならではの、ストレージノードそれぞれの「インテリジェンス」を活用した仕組みです。
| 用途 | 役割 |
|---|---|
| データレプリケーション | オブジェクトおよびレプリカの配置 |
| データマイグレーション | クラスターマップの更新に伴うデータレプリケーションの維持(OSD間のデータ比較) |
| 故障検出・修復 | OSDのHeartbeat監視、OSDダウン情報のmonitorへの報告(=クラスターマップの更新) |
| ピアリング | PGを格納する全てのOSDをPG内の全てのオブジェクトの状態について合意させるプロセス。PGログによるデータレプリケーションの修復 |
| クラスターマップの伝播 | クラスターマップの更新に伴うインクリメンタルマップ(差分マップ)の配布 |
| オブジェクトのロック管理 | 共有ロック、排他ロックの管理(ロックはオブジェクトの属性の一部) |
上記の表で見たように、多数のOSDが中央のmonitorの負荷をOSDのインテリジェンスを活用して分担する工夫がされています。こうした仕組みを持つことで、Ceph/RADOSではペタバイト単位を超えてスケールできるようになっているのです。
冒頭で言及したように、中央のmonitorが全てのOSDを監視するのではなく、OSD同士が監視し合う仕組みです。検出した他のOSDのダウン情報はmonitorに報告します。monitorはOSDダウンの情報をクラスターマップに反映します。この情報はOSD間のメッセージを使ってマップ更新の情報をクラスター内のOSDに伝播させます。
クラスターマップが更新されることで、各OSDの間で通信が行われ、クラスターマップが伝播すると、PGを構成するOSDによってオブジェクトやレプリカがPG内の「あるべき場所」に配置されます。OSDがダウンした場合だけでなく追加・削除される場合も同様の挙動になります。
同時に、PGを構成するOSD間でオブジェクトのレプリカ同士を比較するデータスクラビング(Data Scrubbing)も行います。比較はメタデータとメタデータのみを比較する「light scrubbing」と、データそのものも比較する「deep scrubbing」の二種類があり、比較的負荷の少ない前者は後者よりも高頻度で行っています。
Ceph Storage Clusterのハードウェア要件は?
さて、このように各ノードに一定の処理を委譲する仕組みを持つCeph/RADOSを動作させるために、ストレージクラスター側(Ceph Storage Cluster)はどの程度のハードウェア要件を持っておくべきでしょうか。
下に示す図はCeph Storage Clusterを動かすためのハードウェア要件(最小構成)です。ハードウェア要件についての詳細はCeph Documentationの「HARDWARE RECOMMENDATIONS」のページなどを参照してください。
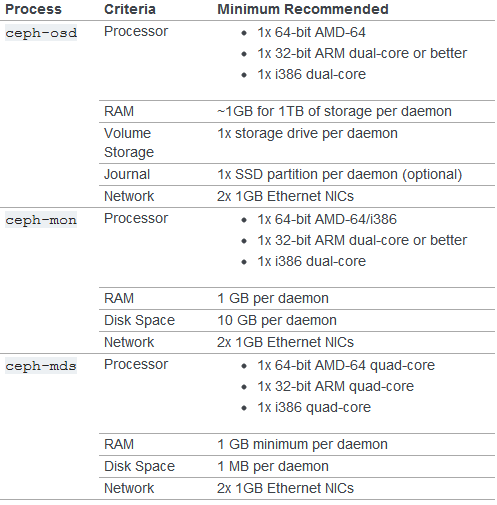 Ceph Storage Clusterを動かすためのハードウェア要件(最小構成)。出典:http://ceph.com/docs/master/start/hardware-recommendations/より抜粋
Ceph Storage Clusterを動かすためのハードウェア要件(最小構成)。出典:http://ceph.com/docs/master/start/hardware-recommendations/より抜粋実運用で使われる際のCeph/RADOS商用製品スペックは
下図はDreamHostが提供しているプロダクションシステム「DreamObject」で実際に使用されているといわれるサーバーのスペックです。オブジェクト冗長度「3」で実効容量1Pバイトのシステムを99台のサーバーで構成しています。
 DreamHostのDreamObjectで採用されているサーバースペック(出典:http://ceph.com/presentations/20121102-ceph-day/20121102-dreamobjects.pdf)
DreamHostのDreamObjectで採用されているサーバースペック(出典:http://ceph.com/presentations/20121102-ceph-day/20121102-dreamobjects.pdf)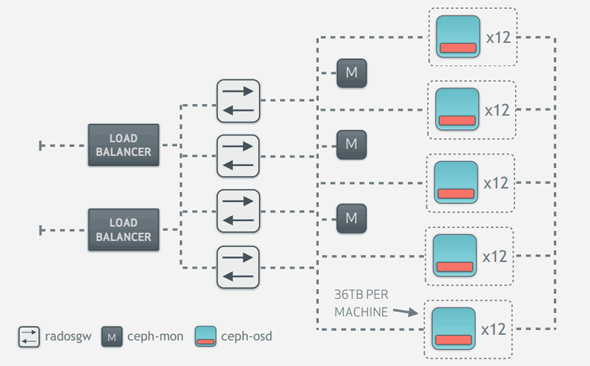 DreamHostのDreamObjectが採用している構成(概略)。出典:http://ceph.com/presentations/20121102-ceph-day/20121102-dreamobjects.pdf
DreamHostのDreamObjectが採用している構成(概略)。出典:http://ceph.com/presentations/20121102-ceph-day/20121102-dreamobjects.pdf今回はCeph/RADOSの挙動をアルゴリズムなどに触れながら紹介してきました。
Ceph/RADOSのアーキテクチャは、各クライアントがオブジェクトを持ったOSDに直接アクセスするので、クライアントやOSDの数が大きくなっても中央のコンポーネントが性能ボトルネックや単一障害点(SPOF)になることがないという特徴と、それを実現するためのクラスターマップやオブジェクトレプリカ整合性の維持に全OSDが協調して動作するという特徴があることが分かりました。
筆者プロフィール
佐藤友昭(さとうともあき)
VA Linux Systems Japan株式会社 クラウド基盤エキスパート。
UNIX系オペレーティングシステムの開発において、ローカルファイルシステム、ネットワークファイルシステム、論理ボリュームマネージャーなどを担当。
HPC向けネットワークファイルシステム、ディスクアレイ、Flash SSDアレイストレージの開発にも携わるなど、ストレージ開発のスペシャリストとして活躍する。
また、InfiniBandやiWarp(10GbE)などのRDMAネットワーク向けのファイルシステムプロトコル策定、リファレンス実装の分野におけるOSS開発の実績を持つ。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。