大量データ処理時に知っておきたいAmazon DynamoDB活用テクニック4選:大規模プッシュ通知基盤大解剖(2)(3/3 ページ)
【4】「並列スキャン」でテーブル読み取り速度を向上させる
DynamoDBへのリクエストが高負荷となる状況は他にもあります。それはアプリをインストールしているデバイス全てを対象としてプッシュ通知を一斉に配信する場合で、DynamoDBのデバイス情報テーブルに登録されたデバイス情報全てを走査しなければならないためです。
DynamoDBでは、上記のようなテーブル全走査のために「Scan API」が用意されています。Scan APIはデフォルトではシーケンシャルな読み出し方式が提供されています。スキャンの対象となるデータのサイズが1MBを超える場合は、スキャン対象のデータのうち1MB分だけのレスポンスが返されるようになっています。レスポンスには、続きのデータをスキャンするためのLastEvaluatedKeyが含まれており、このパラメーターを使ってScan APIへリクエストを繰り返す手続きによって、テーブル内の全データを読み取ることができます。
Scan APIの読み取り速度を上げるためには、テーブルのReadスループットの設定値を上げる方法以外にも、Scan API自体の機能として提供されている「並列スキャン」を利用する方法があります。並列スキャンは、その名の通り、1つのテーブルに対するスキャンリクエストを並列に行うための仕組みで、テーブルの走査領域を複数のセグメントに分割し、各セグメントに並行してスキャンリクエストを実施できます。
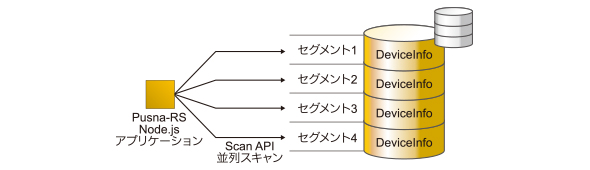 テーブルのデータ領域を分割して並列に読み込む並列スキャンの利用により読み込み速度を向上
テーブルのデータ領域を分割して並列に読み込む並列スキャンの利用により読み込み速度を向上Pusna-RSでも、前述のプッシュ通知一斉配信のようなケースにおいて並列スキャンを利用したテーブル読み取り速度の向上を図っています。リクエストを並列化することによって実際どれくらいの性能が出るのかについて、Pusna-RSのプロトタイプ作成時のベンチマークでの測定結果を下表に示します。表の通り、並列化しない場合より数倍の読み取り速度向上が望めます。
| セグメント数 | 読み込み速度(件/秒)(m1.small) | 読み込み速度(件/秒)(c1.medium) | 性能比(c1.medium) |
|---|---|---|---|
| 1 | 12769.9 | 19830.2 | 1 |
| 2 | 17621.0 | 35926.3 | 1.8 |
| 3 | 20954.6 | 56613.2 | 2.9 |
| 4 | 20429.0 | 71184.8 | 3.6 |
| 5 | 20761.6 | 63480.6 | 3.2 |
| 1件200バイトのデータ100万件に対して全件スキャン走査を行った結果を表にしています | |||
次回は、Node.jsによる高速配信の実現
ここまで説明したように、Pusna-RSでは、データ永続化層としてDynamoDBを利用することで、信頼性と高いパフォーマンスを両立させたアーキテクチャを実現しています。
2014年のAWS re:inventで「DynamoDB Streams」という新機能が発表されました(参考:Amazon Web Services ブログ:DynamoDB Streamsについての事前情報)。StreamAPIはDynamoDBの更新ログを取り出せる機能ですが、Pusna-RSでも、デバイス情報の検索に利用しているElasticsearchのインデックス作成に活用できるのではないかと検討を開始しています。このようにDynamoDBは今後も進化を続けさらに魅力的なサービスとなっていくと思われますので、この機会に皆さまも利用を検討してみてはいかがでしょうか。
次回は、「Node.jsによる高速配信の実現」というタイトルで、高速配信を実現するためのNode.jsでの実装について解説する予定です。
著者プロフィール
相野谷 直樹
2013年9月に株式会社リクルートテクノロジーズに入社。Pusna-RSのインフラ構築を担当したほか、リクルートのWebサービス開発における新技術の導入検証に従事。
github:https://github.com/ainoya
個人ブログ:http://ainoya.io
関連記事
 AWS「Mobile Push」を発表、1つのAPIで各社の端末にプッシュ通知が可能に
AWS「Mobile Push」を発表、1つのAPIで各社の端末にプッシュ通知が可能に
モバイル端末OS向けのプッシュ機能を発表。単一のAPI操作で主要端末へのプッシュ通知機能を利用できる。 BaaSを使えばアカウント認証やプッシュ通知は、もう面倒くさくない
BaaSを使えばアカウント認証やプッシュ通知は、もう面倒くさくない
ここ2年ほどの間で広まってきたクラウドサービス「BaaS(Backend as a Service)」。バックエンドにリソースを割かずに済むBaaSの機能としてデータストア、ソーシャルサービスとの連携、認証機構、プッシュ通知などをiOSアプリから使う方法を解説。 Chrome拡張機能にpush通知をしよう
Chrome拡張機能にpush通知をしよう
簡単なGoogle Chrome拡張機能を作成し、それにGoogle Cloud Messaging for Chrome機能を追加しましょう。 AndroidビームとPush通知で最強のO2Oアプリを作る
AndroidビームとPush通知で最強のO2Oアプリを作る
今注目の「O2O」について、現状や概要を紹介し、O2Oを利用したAndroidアプリを作る際に必要な技術要素を1つ1つ解説していきます。今回は、O2Oの技術要素の1つとして、Push NotificationとNFCについて、実際にアプリに組み込んだ例を示しながら解説します。 Androidのウィジェットにノーティフィケーションするには
Androidのウィジェットにノーティフィケーションするには
 Push Notificationを使ったiPhoneアプリ13選
Push Notificationを使ったiPhoneアプリ13選
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。