ニューラルネットワーク、Deep Learning、Convolutional Neural Netの基礎知識と活用例、主なDeep Learningフレームワーク6選:いまさら聞けないDeep Learning超入門(1)(1/2 ページ)
最近注目を浴びることが多くなった「Deep Learning」と、それを用いた画像に関する施策周りの実装・事例について、リクルートグループにおける実際の開発経験を基に解説していく連載。初回は、ニューラルネットワーク、Deep Learning、Convolutional Neural Netの基礎知識と活用例、主なDeep Learningフレームワーク6選を紹介する。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
本連載では、最近注目を浴びることが多くなった「Deep Learning」と、それを用いた画像に関する施策周りの実装・事例について、リクルートグループにおける実際の開発経験を基に解説していきます。
第1回では、Deep Learningと、それを用いた背景に関して、第2回では、Deep Learningを実装する際に用いたフレームワークである「Caffe」に関して、その構築手法や使い方に関して解説し、第3回では、リクルートグループにおける施策事例に関して、より詳細に述べていきます。第4回では、判別精度のチューニングや、「Active Learning」を用いた継続的精度向上など独自の開発ポイントなどを記載していく予定です。
ニューラルネットワークとは、ディープラーニングとは
ここに一枚の画像があります。この画像を見たとき、あなたはとっさにどう判断したでしょうか。

おそらく思うはずです。「あっ、カブトムシだな」と。たとえカブトムシを知らなくても、「虫だな」とか、「生き物だな」と何かしらを認識して判断したはずです。
これは脳内で無意識に下記のプロセスをたどった結果、起きたことです。
- これまで生きてきた中で図鑑や、テレビ、実物で「カブトムシ」を見てきた。
- 脳の中で「角があるから」「足が6本あるから」「茶色だから」などの特徴を抽出し、「カブトムシ」と記憶した。
- この画像を見たときにこれまで学んだ特徴を照らし合わせ、とっさに近いものを関連付け「カブトムシ」と判断した。
このように脳内の神経回路網とそのプロセスを模倣したのが「ニューラルネットワーク」という機械学習ロジックであり、これを多層にして組み合わせたもの、この総称を「Deep Learning」(ディープラーニング)と呼びます。
本稿では、数あるDeep Learningのロジックの中から、主に画像解析を目的に使用されリクルートグループにおいても積極的に活用されている「Convolutional Neural Net」について解説します。
Deep Learningが求められた背景
筆者がデータ解析に従事し始めた2010年ごろ、Deep Learningという言葉は一部のアカデミックな分野では流行していましたが、ユーザー企業でその言葉を聞くことはあまりありませんでした。
今あらためて、Deep Learningの歴史をひも解いてみると、その歴史は決して明るいものではなかったことが分かります。Deep Learningの構成要素である、ニューラルネットワークとそれを単純に多層に組み合わせたものに関しては、それこそ1980〜1990年代前後から盛んに研究されていました。しかし、その精度や処理量の問題から、同じく分類推定モデル構築によく利用される機械学習ロジックである「ベイジアンネットワーク」「サポートベクターマシン」の裏に隠れてしまい、冬の時代が長く続くことになったのです。
再び脚光を浴びるようになったのは2000年代に入ってから。2006年にDeep Learningが発表され、その後2012年にトロント大学のHinton氏が「ImageNet」と呼ばれる画像セットを用いた画像識別コンペティションでDeep Learningを用いて2位以下を大きく引き離す精度を記録したことがきっかけです。このあたりからグーグルをはじめ、マイクロソフトやフェイスブックなどが注目し、ビッグデータのブームやGPUサーバーなどのハードウエア面の進化も伴ってDeep Learningは広くデータ解析者に広がっていきました。
Deep Learningの最大のウリは何といっても、「人手で特徴量を抽出する必要がない」という点です。
そもそも機械学習は、大きく二つのフェーズに分けられます。データから特徴を抽出するフェーズと、それを学習し予測・分類を行うフェーズです。両者のうち、今日、リクルートグループ内で多く活躍する「データサイエンティスト」と呼ばれる人々が毎日その手腕を発揮しているのは主に前項のフェーズ「特徴抽出」に当たります。
例えば、アイテムのレコメンド機能を開発する場合、「サイトを訪れたユーザーのデータから何を用いてアイテムの推薦を行うか?」「閲覧履歴なのか?」「閲覧時間なのか?」「ユーザーのデモグラ情報なのか?」「アイテムの情報なのか?」「これらの組み合わせなのか?」あるいはクチコミ情報を分類する例にした場合、「クチコミ文から重要語を抜き出してカウントしたものを使うのか」はたまた「単語と単語の関係性と特徴として使うのか」――こういった作業をいくつかの試行錯誤を繰り返しながら定めていき、精度の良い機能を開発していく「職人技」に近い業務を行っているのです。
画像解析においても、これまで「SIFT(Scale Invariant Feature Transform)」「SURF(Speed Up Robust Features)」「HOG(Histograms of Oriented Gradients)」などさまざまな特徴抽出アルゴリズムが人手により設計・構築されてきましたが、これらの特徴抽出の職人技による精度やスピード向上のボトルネックと効率化に向けた自動化の目的から、データから特徴抽出に人手を介さず機械に抽出させる手法であるDeep Learningが注目されたのです。
Convolutional Neural Netとは
画像から特徴を抽出する際に、筆者が所属するリクルートテクノロジーズが用いているのが、「Convolutional Neural Net」と呼ばれる手法です。この手法は、「画像データ全体から受け取れる意味は、これを構成する小さなパーツそれぞれが表す意味の組み合わせである」という概念に基付いています。そして「これらのパーツの中から元のデータをよく表すパーツ群・組み合わせを導き出す」=「特徴抽出を行う」ことが、まさにConvolutional Neural Netの基礎です。
Convolutional Neural Netは主に下記の二つのフェーズを繰り返すことにより特徴抽出を行います。
- Convolutional層
- Pooling層
1のConvolutional層は、下記の図のように画像から一定の大きさのパッチ(フィルター)を形成し、これらスライドさせてパッチごとに複数の特徴を抽出していくような処理のことです。
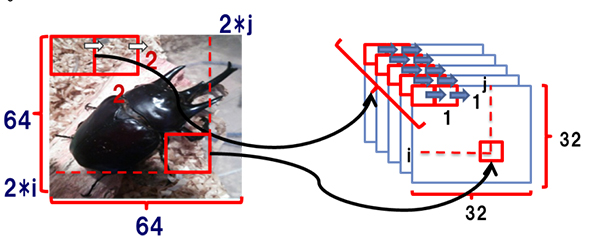 Convolutional層(64×64の画像上で2×2のパッチを2pixelずつ滑らせ、各パッチから5つの特徴量を取り出す)
Convolutional層(64×64の画像上で2×2のパッチを2pixelずつ滑らせ、各パッチから5つの特徴量を取り出す)その後2のPooling層で、1で得られた周辺の特徴量をまとめ上げ、新たな特徴量として再設計することで次元圧縮を行い計算量を削減させています。
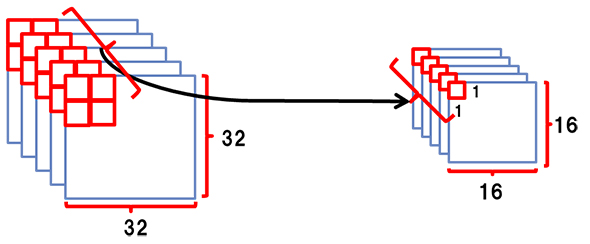 Pooling層(Convolutional層の次の処理。2×2の特徴量をまとめる)
Pooling層(Convolutional層の次の処理。2×2の特徴量をまとめる)これらの処理を何度も繰り返し、特徴を抽出し、得られた全特徴を用いて多層のニューラルネットやSVM(Support Vector Machine)を用いて予測を行うことになります。この一連の特徴抽出の過程がConvolutional Neural Netです。
入力に近い層ではエッジや線などの単純なパーツが抽出され、それらがPoolingとConvolutional層を繰り返すことで特徴同士がまとめ上げられ、顔や物などの複雑で抽象的な特徴量が出来上がることになるわけです。
リクルートグループにおけるDeep Learning活用例
リクルートグループでは、データ解析を2010年から本格的に推進してきました。しかし、これまで盛んに行われてきたデータ解析といえば、データベースに格納できるようなきれいなデータ(=構造化データ)を利用した施策が大半を占めていました。
構造化データの例としては、カスタマーのデモグラフィックな情報、「いつ、誰が、どのアイテムを見たか」の行動履歴データ、値段や商品説明などのアイテム情報などが挙げられます。しかしながら、これらのデータはリクルートグループ内に存在するデータのほんの一部でしかありません。リクルートグループには、多種多様なメディア・サービスが存在し、さらに元は紙媒体から始まったメディアも多いため、膨大なテキストデータ、画像データが数多く存在しているからです。
一方で、これらの、ユーザーに与える情報量が多い割に機械的な解釈が難しいデータ(=非構造データ)は、活用されないままハードディスクの隅に漫然と蓄積されている状態でした。この非構造データに脚光を当て、施策に結び付けるという意味でDeep Learningはまさに画期的な手法であり、その原動力となっていったのです。
リクルートグループにおける画像データとDeep Learningの活用の第一弾は、リクルートライフスタイルが提供する「ホットペッパービューティ」のネイルデザインの類似画像判別である「似ているデザインから探す機能」、カラー抽出の手法である「カラーから探す機能」でした。
その後、同じくリクルートライフスタイル提供のキュレーションメディアである「ギャザリー」の内部でアダルト、グロテスク画像の校閲機能などに実装され、現在も数多くの案件が並行で進んでいる状態であり、リクルートグループ内部で積極的に活用されるようになりつつあります。
これらは、主に画像のラベル付けなど、人が本来行ってきた作業の「代替」の性質を持っており、これまでのレコメンデーションによるアクション数改善といった施策と性質が大きく異なっていることが大きな特徴です。この点でリクルート内において新たなデータ活用の道を切り開くことになった火付け役といってもよいでしょう。
これらの施策の詳細に関しては連載第3回で取り上げます。
関連記事
 グーグルの人工知能を利用できるWebインターフェースが登場
グーグルの人工知能を利用できるWebインターフェースが登場
オズミックコーポレーションとイントロンワークスは7月7日、グーグルの人工知能アルゴリズム「Deep Dream」を利用できるWebインターフェースを公開した。 顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成――デザイナー/クリエイターが茫然自失で拍手喝采な最先端技術動画11連発
顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成――デザイナー/クリエイターが茫然自失で拍手喝采な最先端技術動画11連発
アドビ システムズは、2015年10月6日(現地時間)に開催した「Adobe MAX 2015 Sneak Peeks」で、11の新技術を披露。顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成naなど、今回もデザイナー/クリエイターのみならず、日常的にデジカメやスマホで写真を撮る人でも欲しくなるような機能が多数見られた。 米AlpacaDBがDeep-Learningを使った金融プラットフォームを開発へ
米AlpacaDBがDeep-Learningを使った金融プラットフォームを開発へ
Deep-Learning技術による画像認識プラットフォームを展開してきたAlpacaDBが、資金調達に成功し、金融系の事業領域に本格進出する。 セキュリティ対策に数学の力を――機械学習は先行防御の夢を見るか?
セキュリティ対策に数学の力を――機械学習は先行防御の夢を見るか?
どうしても攻撃者の後手に回りがちなセキュリティ対策。ここに機械学習を活用することで、先手を打った対策を実現できないか――そんな取り組みが始まろうとしている。 個人と対話するボットの裏側――大衆化するITの出口とバックエンド
個人と対話するボットの裏側――大衆化するITの出口とバックエンド
マシンラーニング、ディープラーニングなど、未来を感じさせる数理モデルを使ったコンピューター実装が注目されている。自ら学習し、機械だけでなく人間との対話も可能な技術だ。では、コンピューターはどのように人間との対話を図ればよいのだろうか。コンピューターの技術だけでなく、そこで実装されるべきインターフェースデザインを考えるヒントを、あるコンシューマーアプリ開発のストーリーから見ていく。 自動車を制御するロボットの思考と行動の仕組み――Google Carが現実世界を認識する際の3つのアルゴリズムと実用化への課題
自動車を制御するロボットの思考と行動の仕組み――Google Carが現実世界を認識する際の3つのアルゴリズムと実用化への課題
本連載では、公開情報を基に主にソフトウエア(AI、アルゴリズム)の観点でGoogle Carの仕組みを解説していきます。今回は、制御AIの思考と行動のサイクル、位置推定の考え方「Markov Localization」における3つのアルゴリズムと、その使い分け、現実世界の認識における課題などについて。 バンナム、スクエニ、東ロボ、MS――人工知能や機械学習はゲーム開発者に何をもたらすのか
バンナム、スクエニ、東ロボ、MS――人工知能や機械学習はゲーム開発者に何をもたらすのか
8月26日に開催されたゲーム開発者向けイベントの中から、バンナム、スクエニ、東ロボ、MSなどによる人工知能や機械学習、データ解析における取り組みについての講演内容をまとめてお伝えする。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。