5分で絶対に分かるオブジェクトストレージ:5分で絶対に分かる(2/5 ページ)
2分――大量データ時代、従来型ストレージの問題点とは?
では早速ですが、なぜ従来型のストレージでは大量データをうまく扱うことが難しいのでしょうか? 一言で言えば、“RAID(Redundant Arrays of Inexpensive Disks)頼りのアーキテクチャ”だからです。
これまでのストレージは、複数のHDDを組み合わせて仮想的に1つのHDDとして認識させるRAID技術を使ったアーキテクチャが広く採用されてきました。目的は「万一ディスクが故障しても問題ないようデータの冗長性を担保する」ことです。また、「状況に応じて容量を拡大する」「処理性能を向上させる」という目的もあります。
簡単におさらいすると、データを複数のディスクに書き込む「ストライピング」(RAID 0)、1つのディスクデータを別のディスクにコピーする「ミラーリング」(RAID 1)、「パリティ」と呼ばれる冗長コードを別のディスクにも保存することで故障時に記録データを修復可能にする「パリティ分散」(RAID 5)など、RAIDには重視する目的に応じた複数のパターンがあります。とはいえ、どの構成を組むにしても最大の目的は「HDDの信頼性を補う」ためです。
参考リンク:RAIDレベルを理解しよう(@IT)
ただ、RAIDのレベルが上がったりHDDの数が増えたりすれば、それだけ故障の確率も上がります。HDDが数えられる程度で、扱うデータ量も限定的なら十分にHDDの信頼性を補うことができます。しかし大量のHDDを使ってペタバイト級のデータ量を扱うとなれば、そうはいきません。確率的に言って、エラーレートが無視できないレベルになってしまいます。
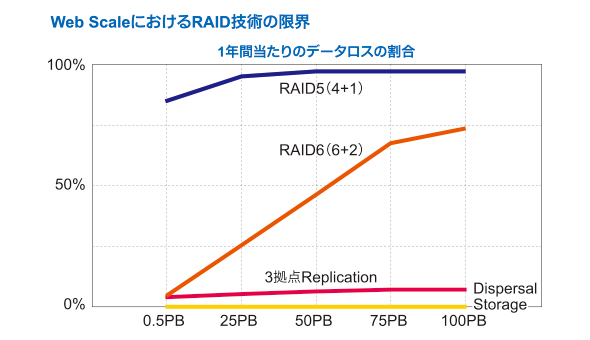 RAIDのレベルが上がったり、HDDの数が増えたりすれば、それだけエラーレートも上がってしまう。グラフ中のRAIDレベルについてはRAIDレベルを理解しよう(@IT)を参照してほしい(出展:日本アイ・ビー・エム)
RAIDのレベルが上がったり、HDDの数が増えたりすれば、それだけエラーレートも上がってしまう。グラフ中のRAIDレベルについてはRAIDレベルを理解しよう(@IT)を参照してほしい(出展:日本アイ・ビー・エム)また、データ保護処理の負荷が高まることから、障害が起きた際、RAIDを再構築する時間がいたずらに長くなる、再構築中に他のディスクも故障してデータが消えてしまうといったリスクも高まります。つまり、RAIDベースのアーキテクチャはペタバイト級のデータ管理には向かないのです。
コスト面でも問題があります。従来型ストレージは、万一のリスクに備えてバックアップの仕組みを併用するのが一般的です。従って、大量データに対応するためには、メインのストレージとともに、バックアップ/ミラー用のストレージも追加しなければなりません。しかも業務要件を守るためには、ただストレージを追加すればよいわけではなく、バックアップシステムの容量、ネットワーク帯域幅など、「バックアップの仕組み」そのものを再設計する必要もあります。そのためには多大な時間とコストがかかることは言うまでもありません。つまりRAIDベースの従来型ストレージでは、データ量の増加に無駄なく柔軟に対応していくことも難しいのです。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。