なぜデータ基盤を作ったのか?「ゼクシィ縁結び・恋結び」で必要になった理由:開発現場に“データ文化”を浸透させる「データ基盤」大解剖(1)(2/2 ページ)
なぜデータ基盤が必要になったのか
このように、一口に「データ活用」といってもさまざまな用途があります。これらの中にはDBのデータを定期的に見るだけで済むようなものもあります。では、あえて「データ基盤」と呼ばれるものが必要になるのは、なぜなのでしょうか。
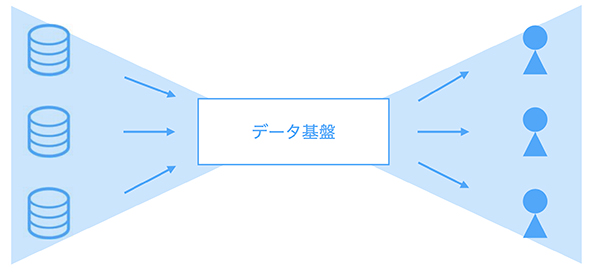
データ基盤とは「データソースと利用者をリボンのように結び付けるもの」だと筆者は解釈しています。データソースや利用者がお互い1つのときは、直接参照するだけで要求は実現できるでしょう。
しかしプロダクト成長や体制拡大によって、リボンの両側は多様になっていきます。そうなると、結び付ける役割のデータ基盤が必要になるのです。
実際に「ゼクシィ縁結び」「ゼクシィ恋結び」でも、体制や施策の拡大に伴って、システムが複雑化しました。

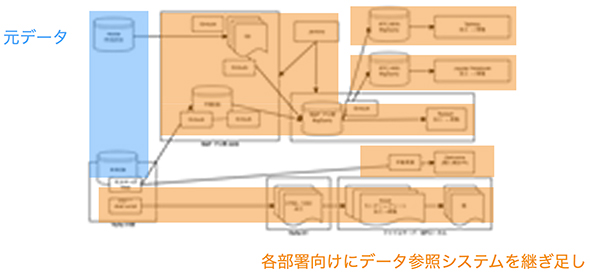
最初はエンジニアが直接データを出力したり、定期的にCSVを出力したりする簡素なバッチジョブを設けていました。しかしビジネスの成長に伴って、体制や施策が増えてくると、要件も多様になり、さまざまな部署からエンジニアにデータ出力依頼が寄せられるようになりました。大量の依頼が寄せられているので、1つ1つへの対応は遅くなってしまいます。
この事態を受けて、データ連携を依頼する側は、少しでもエンジニアの負担を減らそうと工夫します。「疎通ツールや加工ロジックは依頼する側で用意するから、本番環境にツールを置くだけでいい」といった具合です。結果として部署ごとに違うツール・ロジックが用意されることになりました。

すると、部署ごとに加工ロジックや見ているデータが徐々にズレていき、最終的に「売上」という言葉で表現されるものが全く違う数字になるという状況が生まれてしまいました。
「売上」と一言で言っても、考え方や用途によって定義はいくらでも変わりますし、さまざまな計算方法が考えられます。
「消費税を含むのか」「割引分はどこで差し引くのか」「年間契約プランは月次で案分するのか」「案分する場合は途中解約をどこに計上するのか」「返金は後で一括で差し引くのか、購入時にさかのぼって差し引くのか」「モバイルアプリの課金はAppleやGoogleへの決済手数料を含むのか」「用途は財務会計か管理会計か」……。
あるチームは自分たちの施策によってKPIが大幅に上がったと主張しても、別のチームからは何の参考にもならない数字に見えるのです。どのデータが正しいのか誰も分からないので、横断での意思決定や調整が困難になりました。まさに「システムを設計する組織は、その構造をそっくりに“まね”した構造の設計を生み出してしまう」(コンウェイの法則)弊害が生じました。

そして、新しい機能を追加したり、不具合を修正したり、システムは日々変わります。システムから生成されるデータ仕様も日々変わります。非エンジニアにとっては同じ挙動のように見えても、実は処理のタイミングやレコード反映の順序が微妙に変わっていて、集計方法に影響を与えていたことがありました。
そうなってくるとデータ仕様については、プロダクトを直接開発しているエンジニアに聞かざるを得ません。そこで非エンジニアは「このレコードが追加されるタイミングが最近変わったのか?」といった質問を投げ掛けることになります。エンジニアはその質問を受けて、変更履歴を調査することになります。
このようにしてエンジニアの時間が取られるようになります。
さらに、エンジニアの時間を取らないようにと、ディレクターが独自に設定したBI(Business Intelligence)ツールの数字がずれたこともありました。ディレクターからすると、「元のデータがおかしいのか」「自分のデータの取り方がおかしいのか」について原因を判断し切れません。実際にシステム不具合やパッチ当てによってオリジナルのデータ自体に欠損や不整合が生じている可能性もあるからです。
推論だけで解決することもありますが、そうでない場合はプロダクトを直接開発しているエンジニアに聞くことになります。しかしエンジニアからすれば、「他人が勝手に立てたBIツールがどういう仕組みになっているのか」について慣れないものを調べるところから始めなければいけません。
このようにしてエンジニアの時間がさらに取られるようになります。

これは構造の問題です。一人一人の判断が悪かったわけではありません。ディレクターが施策を打つときにはデータを基に企画を詰める必要があります。これは極めてまっとうです。エンジニアの時間を取らずに直接データを抽出できるようにしようとBIツールを導入するのは自然なことです。
しかし、体制が拡大して、さまざまな立場の人が独自にデータを使おうとすると、データの流れが複雑になり、必然的に混乱が生じてしまうのです。データに基づいて意思決定を行いたいのに、肝心のデータが信頼できなくなってしまう。これではデータドリブンを実現することはできません。
だからこそ関係者全員が安心して多様なデータソースを扱うためのデータ基盤が必要となりました。
データソースと利用者をリボンのように結び付ける基盤の構築は、複雑性との地道な戦いとなります。
- 整合性の取れたデータの受け渡しができるシステム
- 関係者一人一人に安心してもらうためのプロセス
- これまでデータを使いこなせていなかった人々でもデータを活用しようと思えるカルチャー
これら全てに配慮することでようやく「使われるデータ基盤」を構築できるのです。以降の連載では、「システムやプロセス、そしてカルチャーをいかにエンジニアリングしたか」を紹介します。
参考
筆者紹介
横山翔
リクルートテクノロジーズ プロダクトエンジニアリング部所属
途上国から限界集落まで各地放浪、ベンチャーキャピタルから投資を受けての起業や会社経営、リクルートグループ会社における複数の新規事業の立ち上げを経て、現職。
現在は急成長プロダクトを対象に、システムアーキテクチャの再構築やエンジニアチームの立ち上げ、立て直しに従事。
関連記事
 ネット広告のデータ分析プロジェクトはどのように行われるのか
ネット広告のデータ分析プロジェクトはどのように行われるのか
広告宣伝費を各宣伝媒体へのコスト配分を調整することで効率化したいという事業部の課題に対してデータ分析のプロジェクトはどう進められるものなのか。筆者の経験を基に紹介する。 CVRをあと10%アップする、ビッグデータ分析とアダプティブUXの使い方
CVRをあと10%アップする、ビッグデータ分析とアダプティブUXの使い方
ABテストを利用したサイト改善の限界にぶつかっている人たちに向けて、リクルートグループ内で実践している改善ノウハウをお伝えする連載。今回は、中古車販売サイト「カーセンサー」を例に「検討フェーズ」を軸とした個別最適化やビッグデータ分析の有効な生かし方について解説する。 Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み
Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。今回は、ログデータの分析および可視化の基盤を構成する5つの主なOSSや集計データを活用したキーワードサジェストの事例を紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。