「Gensim」による機械学習を使った自然言語分析の基本――「NLTK」「潜在的ディリクレ配分法(LDA)」「Word2vec」とは:Pythonで始める機械学習入門(9)(1/2 ページ)
最近流行の機械学習/Deep Learningを試してみたいという人のために、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説する連載。今回は機械学習を使った自然言語分析のライブラリ「Gensim」について解説します。
プログラミング言語「Python」は機械学習の分野で広く使われており、最近の機械学習/Deep Learningの流行により使う人が増えているかと思います。一方で、「機械学習に興味を持ったので自分でも試してみたいけど、どこから手を付けていいのか」という話もよく聞きます。本連載「Pythonで始める機械学習入門」では、そのような人をターゲットに、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説しています。
連載第1回の「Pythonで機械学習/Deep Learningを始めるなら知っておきたいライブラリ/ツール7選」では、ライブラリ/ツール群の概要を説明しました。連載第3回から第1回で紹介した各種ライブラリを使う具体的なコードを例示していますが、Jupyter Notebook形式で書いています。
今回は「Gensim」を使った自然言語処理の基本を説明します。Gensimは言語処理でよく使われるアルゴリズムを含むライブラリです。GensimのWebサイトには「topic modelling for humans」というキャッチフレーズが書いてありますが、つまり「トピックモデル」というものを使いやすくするために作られたものです。
 Gensim
GensimGensimには、さまざまなアルゴリズムが含まれていますが、本稿では「潜在的ディリクレ配分法(LDA:Latent Dirichlet Allocation)」「Word2vec」を使って実験してみます。
なお本稿では、Pythonのバージョンは3.x系であるとします。
データのダウンロードと前処理
オープンなデータセット「Reuters-21578」
自然言語処理の実験ではよく使われるオープンなデータセットとして、「Reuters-21578」があります。Reutersの古い金融関連ニュース記事を集めたものです。研究目的に限って自由に使っていいことになっています。
これを使って実験するために、まずはデータを読み込むところから始めます。
「NLTK(Natural Language ToolKit)」とは
データのダウンロードには「NLTK(Natural Language ToolKit)」というライブラリを使います。NLTKは自然言語処理について、実験用のデータセットやよく利用されるツールを集めたライブラリです。
NLTKでダウンロード
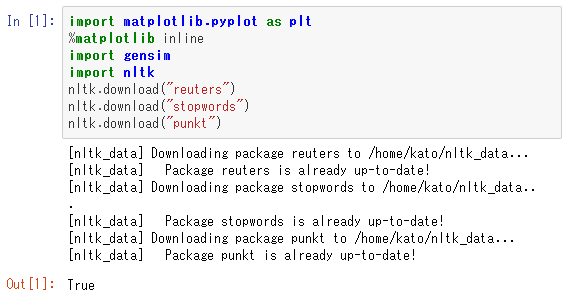
ここで3つ続いている「nltk.download」は、今後の処理に必要なデータをダウンロードしていることを表しています。「nltk.download("reuters")」は、Reuters-21578データセットの読み込みです。他の2つのnltk.downloadは後ほど使うデータをダウンロードします。ここでダウンロードされたファイルはローカルの適当なディレクトリ内に保存しておきましょう。
※注
著者の環境ではNLTKに不具合があって、reutersについてはダウンロード後のファイル解凍が行われないことがありました。その場合、「~/nltk_data/corpora」にダウンロードされるファイル「reuter.zip」を手動で解凍する必要があります。
データを読み込んで変数に格納

ここではファイルからReuters-21578のデータを読み込み、変数「reuters」に格納しています。
reutersにはオブジェクト型としてさまざまな情報が含まれていますが、その中で特にニュース記事の文章の情報は「paras」メソッドで取得します。ここでparasには「文字列のリストのリストのリスト」が格納されます。つまりparas[i]がi番目の記事を意味し、それぞれの記事が文のリストという形で、各文は単語のリストという形をしています。
試しに、最初の記事にある最初の文の20語だけを見てみましょう。
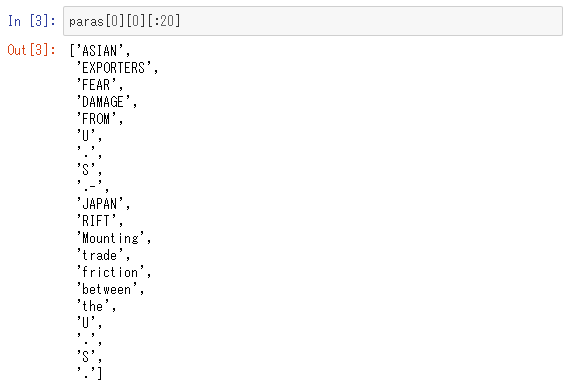
Gensimでは文書を「bag of words」(直訳すると「単語の袋」)という形式として利用します。bag of words形式とは、単語の並びなどを忘れて、単純に文書内にそれぞれの単語が何回出現したかという出現回数の情報だけを保持するデータ形式です。
ストップワードの除去
以下データを分析していきますが、1点だけ確認しておきましょう。一般的に自然言語処理では前処理として「ストップワードの除去」というのが行われます。ストップワードというのは、頻繁に使われていてあまり文章の解釈に影響を与えないような単語です。英語の場合では、例えば冠詞の「a」「an」「the」や、前置詞の「in」「on」「at」などがあります。これらは人間が英文を読むときには重要な情報になりますが、bag of words形式で扱うことを前提にすると語順は全く考慮されないので、無駄な情報ということになります。
では、NLTKに含まれている英語のストップワードを読み込んでいきます。
ここで、先ほどnltk.downloadを使ってダウンロードされたデータを読み込んでいます。ダウンロードしていない状態でこれを実行すると、エラーになり、ダウンロードするように促すメッセージが表示されます。読み込んだストップワードをアルファベット順に10個表示すると次のようになります。

データを「単語の並び」に変換
次に、今後の処理のために、文書のデータを「文字列のリストのリスト」に変換します。言い換えると、各記事が「文字列のリストのリスト」であった元データを「文字列のリスト」に変換します。つまり、各記事に「段落-文」という構造があったものを単純に「単語の並び」に変換するということです。
ここでは、変数「reuters_texts」に「文字列のリストのリスト」に変換されたものが入れられていて、それに対してストップワードの除去が行われたものが「reuters_texts_filtered」です。ここでは、ストップワードだけではなくて、1文字だけからなる単語も全て除去しています。
「コーパス」形式に変換
次に、Gensimで処理できるような「コーパス」形式に変換します。コーパスというのは自然言語処理でよく出てくる用語ですが、一般には文章などを処理しやすいように構造化したものとして定義されます。特にGensimで必要とされるコーパスはbag of words形式ですので、それに合わせてデータを変換します。

ここで、「gensim.corpora.Dictionary」という型は、各単語に数値が割り当てられた構造を意味します。この型を使うことで、単語から数値、数値から単語、それぞれの変換が簡単にできます。それを使ってbag of words形式のコーパスを作っているのが2行目です。「reuters_corpus」の中から、最初の文書の10単語を見てみます。

ここで、「(0,1)」「(1,6)」は、0番の単語が1回出現し、1番の単語が6回出現しているという意味です。
ここまでが前処理に当たる部分で、ここからやっと機械学習を使った分析を行います。
関連記事
 Intel、Xeon上での「TensorFlow」使用時向けにDNNモデルコンパイラ「nGraph」の性能を強化
Intel、Xeon上での「TensorFlow」使用時向けにDNNモデルコンパイラ「nGraph」の性能を強化
Intelは、「Intel Xeonスケーラブルプロセッサー」上で「TensorFlow」を使用するデータサイエンティスト向けに、フレームワーク非依存のディープニューラルネットワークモデルコンパイラ「nGraph Compiler」のパフォーマンスを高めるブリッジコードを提供開始した。 NVIDIAとGoogle、「TensorRT」と「TensorFlow 1.7」を統合
NVIDIAとGoogle、「TensorRT」と「TensorFlow 1.7」を統合
「NVIDIA TensorRT」とオープンソースソフトウェアの機械学習ライブラリの最新版「TensorFlow 1.7」が統合され、ディープラーニングの推論アプリケーションがGPUで実行しやすくなった。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。