Facebook、オンライン音声認識に使用可能な推論フレームワークをオープンソース化:完全畳み込みアコースティックモデルを採用
Facebook AI Researchは、オンライン音声認識に使用可能な推論フレームワーク「wav2letter@anywhere」を開発し、オープンソースソフトウェアとして公開した。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
Facebook AI Researchは2020年1月13日(米国時間)、音声をリアルタイムでテキストに変換するプロセスであるオンライン音声認識に使用可能な推論フレームワーク「wav2letter@anywhere」を開発し、オープンソースソフトウェアとして公開したと発表した。
wav2letter@anywhereは、Facebook AI Researchのオープンソース音声認識ツールキット「wav2letter」「wav2letter++」をベースにしている。ライブ動画キャプション作成やオンデバイス音声テキスト変換のようなアプリケーションで重要となる、音声入力からテキスト出力までのレイテンシの短縮ニーズに対応して開発された。
ほとんどの既存のオンライン音声認識ソリューションは、「再帰型ニューラルネットワーク(RNN)」のみをサポートするが、Facebook AI Researchはwav2letter@anywhereで、「完全畳み込みアコースティックモデル」を採用。これにより、特定の推論モデルでスループットが3倍に向上し、ASR(自動音声認識)用音声コーパス「LibriSpeech」で高パフォーマンスを実現したという。
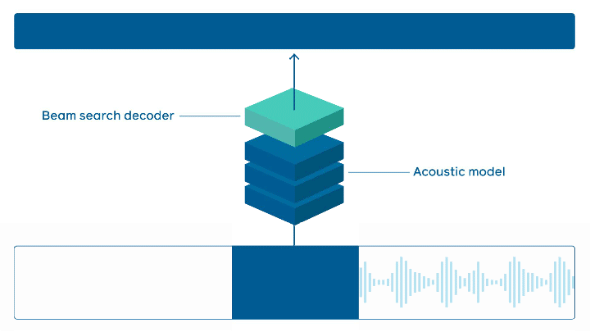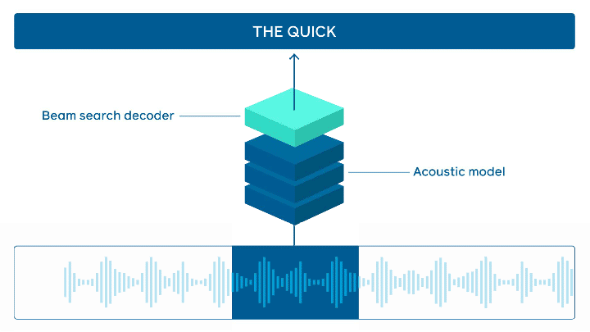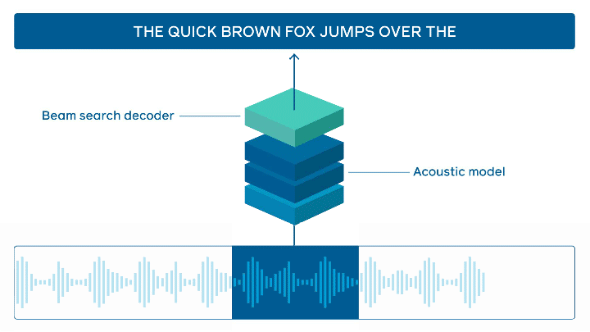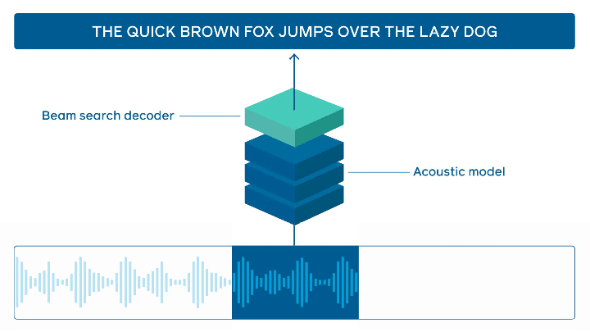 オンラインシステムが音声を処理する方法(出典:Facebook AI Research)音声の各チャンクは最初に音響モデルに送られ、単語モデルのスコアが計算される。これらのスコアは、「軽量ビーム検索デコーダー」を介して言語モデルと組み合わされ、入力シーケンスと選択された言語モデルに基づいて最も可能性の高い単語のシーケンスが出力される
オンラインシステムが音声を処理する方法(出典:Facebook AI Research)音声の各チャンクは最初に音響モデルに送られ、単語モデルのスコアが計算される。これらのスコアは、「軽量ビーム検索デコーダー」を介して言語モデルと組み合わされ、入力シーケンスと選択された言語モデルに基づいて最も可能性の高い単語のシーケンスが出力される推論プラットフォーム
wav2letter++リポジトリに含まれるwav2letter@anywhereは、オンライン音声認識に使用でき、以下の目的で開発された。
- ストリーミングAPI推論は効率的であるとともに、さまざまな音声認識モデルを扱えるだけのモジュール性を備えていなければならない
- 同時音声ストリームをサポートしなければならない。これは、本番規模でタスクを実行する際に高スループットを提供するために必要になる
- APIは、PC、iOS、Androidといった各種プラットフォームで簡単に使えるだけの柔軟性を備えていなければならない
wav2letter@anywhereは、Facebook AI ResearchのモジュラーストリーミングAPIのおかげで、RNNや「畳み込みニューラルネットワーク(CNN)」などさまざまなモデルをサポートする。C++で作成されていて、スタンドアロン。どこにでも組み込めるという。「FBGEMM(Facebook General Matrix-Matrix Multiplication)」のような効率的なカーネルライブラリや、iOSおよびAndroidの特定のルーティンも使用されている。汎用(はんよう)推論パイプラインに依存する他の技術とは異なり、ストリーミングを考慮して開発されており、その結果として効率的なメモリ割り当て設計が実装されている。
Facebook AI Researchはwav2letter@anywhereで、完全畳み込みアコースティックモデルを「コネクショニスト時間分類(CTC)」基準とともに提唱している。これらを採用したシステムは、デプロイ効率が非常に高い上に、ワードエラーレート(WER)も改善され、レイテンシも低減されるとしている。
低レイテンシアコースティックモデリング
wav2letter@anywhereの重要なビルディングブロックとして、「時間深度分離可能(TDS)畳み込み」が挙げられる。これにより、精度を維持しながら、モデルサイズの大幅な縮小や計算時間の短縮が可能になる。またFacebook AI Researchは、全ての畳み込みに非対称パディングを使用し、入力の開始近くでパディングをさらに増やした。その結果、アコースティックモデルが将来見るコンテキストが減少し、レイテンシの低減につながったという。

関連記事
 音声認識とは?
音声認識とは?
用語「音声認識」について説明。人に言われた言葉の内容を認識することを指す。 CNN(Convolutional Neural Network: 畳み込みニューラルネットワーク)とは?
CNN(Convolutional Neural Network: 畳み込みニューラルネットワーク)とは?
用語「CNN」について説明。ネットワーク内部に畳み込みとプーリングの層を持つ、ディープニューラルネットワークのアルゴリズムの一種を指す。 RNN(Recurrent Neural Network: 再帰型ニューラルネットワーク)とは?
RNN(Recurrent Neural Network: 再帰型ニューラルネットワーク)とは?
用語「RNN」について説明。ネットワーク内部に再帰構造を持つ、ディープニューラルネットワークのアルゴリズムの一種を指す。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。