ディープフェイク検出システムをすり抜ける攻撃手法を実証、米国の研究チーム:敵対的サンプルでAIのミスを誘発
カリフォルニア大学サンディエゴ校の研究チームは、AIをだます新しい手法とその実証結果を発表した。実際の映像を改変操作したディープフェイク動画を検出するAIが対象だ。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
カリフォルニア大学サンディエゴ校のコンピュータサイエンスの研究チームは、2021年1月5〜9日にオンラインで開催されたカンファレンス「WACV 2021」で、AIをだます新しい手法とその実証結果を発表した。実際の映像を改変操作した動画であるディープフェイクの検出システムが対象だ。
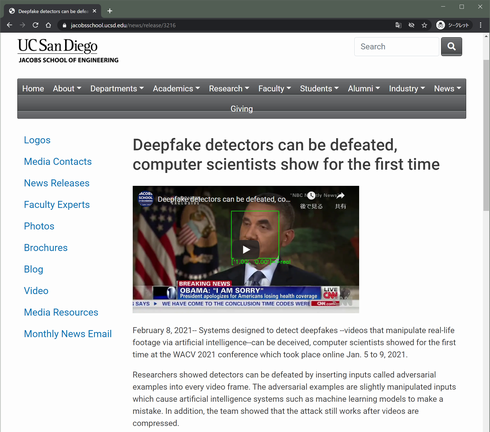
研究チームの手法は「敵対的サンプル」を全ての動画フレームに挿入するというもの。敵対的サンプルとは、機械学習モデルなどのAIシステムにミスをさせるようにわずかに改変された入力を指す。今回の研究では敵対的サンプルを動画に挿入後、その動画を圧縮した後であっても、AIをだますことができた。
同校でコンピュータエンジニアリングを専攻する博士課程の学生で、WACV 2021で発表された論文の筆頭共著者であるシェジーン・フセイン氏は、こう語る。「われわれの研究は、ディープフェイク検出システムをだます攻撃が、実世界で脅威になり得ることを示している」
ディープフェイクでは、全く起こっていないイベントについてもっともらしい映像を作るために、被写体の顔を改変する。そのため、DNN(ディープニューラルネットワーク)を用いたディープフェイク検出システムは、冒頭の写真内にあるように、まず動画内の顔部分を追跡し、収集する。その後、動画が本物かフェイクかを判断するニューラルネットワークに顔データを渡す。
ニューラルネットワークはさまざまな特徴を調べる。例えば、まばたきはディープフェイクではうまく再現できないため、目の動きにフォーカスする。最新鋭のディープフェイク検出システムは、ほぼ全てDNNに依存しており、このようにしてフェイク動画を特定する。
最近では、ソーシャルメディアプラットフォームを通じてフェイク動画が広く拡散し、全世界で大きな懸念を呼んでいる。こうした状況は、特にデジタルメディアの信頼性を損なうと、研究チームは指摘している。「攻撃者が検出システムに関する知識を持っていると、彼らはその盲点を突き、検出システムをすり抜ける入力を設計できてしまう」(同校のコンピュータサイエンスの学生で、上記論文のもう1人の筆頭共著者であるパース・ニーカラ氏)
どうやってすり抜けたのか
研究チームは、動画フレーム内の全ての顔画像について敵対的サンプルを作成した。動画の圧縮やサイズ変更といった一般的な編集処理を施すと、通常、敵対的サンプルは画像から取りのぞかれてしまうが、研究チームが作成した敵対的サンプルは、これらのプロセスに耐えられるように設計されている。
攻撃アルゴリズムは検出側の挙動を推測してその裏をかく。ディープフェイク検出システムが一連の入力変換において、どのように画像を本物あるいはフェイクと分類するのかをまず推測する。次にその推測に基づいて、敵対的画像が圧縮や伸長の後も有効であり続けるように、顔画像を変換する。
このプロセスを動画内の全ての動画フレームに挿入していくことで、検出できないディープフェイク動画が完成する。この攻撃は、顔の収集データだけでなく、動画フレーム全体を踏まえて動作する検出システムにも応用できる。
99%以上、すり抜ける場合も
研究チームは、今回考案した攻撃手法を2つのシナリオでテストした。
第1のシナリオは、顔抽出パイプラインや分類モデルのアーキテクチャとパラメーターなどを含むディープフェイク検出モデルに対して、攻撃者が完全にアクセスできるシナリオ。
この場合、非圧縮動画を使った攻撃の成功率は99%以上だった。圧縮動画であっても84.96%と高かった。
第2のシナリオは、機械学習モデルへクエリを送り、フレームが本物またはフェイクと分類される確率を調べることができるシナリオだ。
結果は非圧縮動画での攻撃の成功率が86.43%、圧縮動画では78.33%だった。
研究チームはこのような高い確率を達成したことで、最新鋭のディープフェイク検出システムに対する攻撃が成功することを初めて実証したことになるという。
研究チームは、悪用を防ぐために、今回の研究で使用したソースコードを公開していない。
関連記事
 Microsoft、ディープフェイク検出技術「Microsoft Video Authenticator」などを発表
Microsoft、ディープフェイク検出技術「Microsoft Video Authenticator」などを発表
Microsoftは、写真や動画が改変されている可能性をパーセントで表示するディープフェイク検出技術「Microsoft Video Authenticator」を発表した。コンテンツが改変されていないことを保証する技術も併せて公開した。 ディープラーニングで生成された「ディープフェイク画像」を周波数領域で見破る ルール大学
ディープラーニングで生成された「ディープフェイク画像」を周波数領域で見破る ルール大学
ルール大学の研究チームが、ディープラーニング技術を用いて生成されたフェイク画像を識別する方法を開発した。 2021年の「AI/機械学習」はこうなる! 5大予測
2021年の「AI/機械学習」はこうなる! 5大予測
2020年は、自然言語処理(NLP)のTransformer技術に基づくBERT/GPT-3や、画像生成のディープフェイクが大注目となる一方で、倫理に関する問題がさまざまな方面でくすぶり続けた。2021年の「AI/機械学習」界わいはどう変わっていくのか? 幾つかの情報源を参考に、5個の予測を行う。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。