拞妛丒崅峑悢妛偱僆僀儔乕偺兞偺嬤帡抣傪媮傔傞僾儘僌儔儈儞僌丗悢妛亊Python僾儘僌儔儈儞僌擖栧乮2/2 儁乕僕乯
4. 壜張暘強摼偺慜擭搙斾傪媮傔傞僒儞僾儖僾儘僌儔儉
丂偙偙傑偱丄憤榓乮椵寁乯傗屄悢傪媮傔傞偨傔偺僾儘僌儔儈儞僌偵偮偄偰偞偭偲尒偰偒傑偟偨丅儕僗僩偲孞傝曉偟張棟偼乽憡惈乿偑偄偄偺偱丄懡偔偺柺搢側寁嶼傪帺摦壔偡傞偺偵栶棫偪傑偡丅偨偩丄堄偺傑傑偵僾儘僌儔儈儞僌偡傞偵偼孞傝曉偟偺惂屼曄悢傗儕僗僩偺僀儞僨僢僋僗偺憖嶌偵姷傟傞昁梫偑偁傝傑偡丅
- 惂屼曄悢丗 for i in range(0, n)偺i偵偁偨傞曄悢
- 儕僗僩偺僀儞僨僢僋僗丗 data[i]偺i偵偁偨傞曄悢
丂側偍Python偱偼丄僀儞僨僢僋僗傪巊傢側偔偰傕for x in data偲偄偆宍幃偱丄data偺屄乆偺抣傪曄悢x偵戙擖偟側偑傜孞傝曉偟張棟偟偨傝丄僀儞僨僢僋僗偑昁梫側応崌偼丄for i, x in enumerate(data)偺傛偆側宍幃偱丄僀儞僨僢僋僗i偲屄乆偺抣x傪庢摼偟側偑傜孞傝曉偟張棟偟偨傝偱偒傑偡丅偟偐偟崱夞偼僀儞僨僢僋僗偺憖嶌偵偮偄偰妛傇偨傔偵丄for i in range(0, n)偺傛偆偵偟偰僀儞僨僢僋僗偩偗傪庢摼偟側偑傜孞傝曉偟張棟偡傞僐乕僪傪彂偄偰傒傞偙偲偵偟傑偡丅
丂偝偰丄偙傟傑偱偺僒儞僾儖僾儘僌儔儉偼孞傝曉偟張棟偩偗偱偱偒傞傕偺偽偐傝偱丄僀儞僨僢僋僗傪巊偭偰儕僗僩傪憖嶌偡傞椺偼偁傝傑偣傫偱偟偨乮昿搙昞偺嶌惉偱彮偟怗傟傑偟偨偑乯丅僾儘僌儔儈儞僌偺擖栧彂側偳偵偼丄崌寁傪媮傔偨傝丄暯嬒傪媮傔偨傝偡傞僾儘僌儔儉傪椺偵丄僀儞僨僢僋僗傪巊偭偰儕僗僩傪憖嶌偡傞椺偑傛偔偁傝傑偡丅埲壓偺傛偆側僒儞僾儖僾儘僌儔儉傪偛棗偵側偭偨曽傕懡偄偱偟傚偆丅
def average(x):
sum = 0
for i in range(0, len(x)):
sum += x[i]
return sum / len(x)
data = [67, 85, 78, 72]
average(data)
# 弌椡椺丗75.5
乽慡偰偺榓偺憤榓傪媮傔偰丄屄悢偱妱傞乿偲偄偆丄悢妛偱偺暯嬒抣偺媮傔曽偵増偭偰慺捈偵彂偔偲偙偺傛偆側僐乕僪偵側傞丅偨偩偟丄忋偱傕婰偟偨傛偆偵屄乆偺抣傪庢摼偡傞彂偒曽乮儕僗僩3偱傕徯夘偟偨彂偒曽乯偺曽偑Python偱偼堦斒揑丅傑偨丄暯嬒抣傪媮傔傞偩偗側傜丄崌寁傪媮傔傞sum娭悢偲儕僗僩偺挿偝傪媮傔傞len娭悢傪巊偊偽丄sum(x)/len(x)偲偄偆1峴偺僐乕僪偱嵪傓丅幚嵺偺僾儘僌儔儈儞僌偱偼丄婛偵嶌傜傟偰偄傞傕偺偑偁傟偽偦傟傪棙梡偡傞偺偑摼嶔偩偑丄偙偙偱偼丄僀儞僨僢僋僗偺摥偒傪偍偝傜偄偡傞偨傔偵丄偁偊偰忋偺傛偆側乮忕挿側乯僐乕僪傪帵偟偨丅側偍丄偙偙偱偼sum傪曄悢柤偲偟偰巊偭偰偄傞偑丄sum娭悢偲摨偠柤慜側偺偱丄摨偠娭悢掕媊側偳偺拞偱偦傟傜傪摨帪偵巊偆偲僄儔乕偵側傞偙偲偵拲堄丅
丂偟偐偟丅偟偐偟丄偱偡丅偙偺掱搙偺僾儘僌儔儉側傜棟夝傕偱偒傞偟丄娙扨偵嶌傞偙偲傕偱偒傞偺偵丄暿偺栤戣傪帺暘偱僾儘僌儔儈儞僌偟傛偆偲偡傞偲搑曽偵曢傟偰偟傑偆丄偲偄偆恖傕懡偄傛偆偱偡丅堦懱側偤偱偟傚偆丅偦傟偼丄嫲傜偔惂屼曄悢偲僀儞僨僢僋僗偺懳墳偑暋嶨偵側偭偨応崌偵偁傑傝姷傟偰偄側偄偐傜偩偲巚偄傑偡丅儕僗僩9偺僾儘僌儔儉偩偲惂屼曄悢i偑偦偺傑傑儕僗僩偺僀儞僨僢僋僗偲偟偰巊偊偨偺偱丄偦傟傜偺懳墳偵偮偄偰怺偔峫偊側偔偰傕傛偐偭偨偐傜偱偡丅
丂偦偙偱丄惂屼曄悢偲儕僗僩偺僀儞僨僢僋僗偺懳墳傪峫偊傞椺傪捠偟偰丄偦傟傜偺憖嶌偵姷傟傞偙偲偵偟傑偟傚偆丅偄偐偵傕悢妛揑側椺偽偐傝偑懕偄偰偄傞偺偱丄偪傚偭偲婥暘傪曄偊傞偨傔偵丄擔忢惗妶偵娭傢傝偺怺偄僨乕僞傪巊偭偰傒傑偡丅
丂埲壓偺僨乕僞偼丄2007擭偐傜2020擭傑偱偺嬑楯幰悽懷偺壜張暘強摼偺悇堏偱偡乮弌揟偼憤柋徣摑寁嬊)丅
 恾2丂嬑楯幰悽懷偺壜張暘強摼偺悇堏
恾2丂嬑楯幰悽懷偺壜張暘強摼偺悇堏2018擭乣2019擭偵側偭偰傛偆傗偔2008擭偺悈弨偵栠傝丄偦傟埲崀偼忋徃偺孹岦偑尒傜傟傞丅偟偐偟丄僨乕僞偑乽慡悽懷乿偱偼側偔乽嬑楯幰悽懷乿偱偁傞偙偲傗丄偙偙偵偼帵偝傟偰偄側偄偑徚旓巟弌偑尭彮偟偰偄傞偙偲側偳偐傜丄堦奣偵宨婥偑傛偔側偭偰偄傞偲偼敾抐偱偒側偄偙偲偵拲堄丅
丂偙偺僨乕僞偑埲壓偺傛偆側儕僗僩偲偟偰昞偝傟偰偄傞傕偺偲偟傑偡丅
income = [402116, 402932, 383960, 389848, 380863, 383851, 380966, 381929, 381193, 376576, 382434, 400964, 416980, 431992]
丂椺偊偽丄income[0]偑2007擭偺壜張暘強摼偺抣乮偮傑傝402116乯偱偡丅
丂偙偺僨乕僞傪婎偵丄懳慜擭搙斾乮亾乯傪嵟嬤偺抣偐傜弴偵媮傔偨儕僗僩incr傪嶌偭偰傒傑偟傚偆乮娭悢偵偟側偔偰傕峔偄傑偣傫乯丅偮傑傝丄尦偺僨乕僞偲弴彉偑媡偵側傞傢偗偱偡丅愭偵寢壥傪帵偟偰偍偒傑偡丅
incr
# 弌椡椺丗[103.6, 104.0, 104.8, 101.6, 98.8, 99.8, 100.3, 99.2, 100.8, 97.7, 101.5, 95.3, 100.2]
嵟嬤偺抣偐傜偺儕僗僩側偺偱丄incr[0]偼2020擭偺抣/2019擭偺抣*100偲側傞丅偮傑傝丄incr[0] = income[13]/income[12]*100偲側傞丅幚嵺偵寁嶼偟偰傒傞偲丄431992亐416980亊100亖103.6偲側傞丅
丂懳慜擭搙斾乮亾乯偼埲壓偺悢幃偱昞偝傟傑偡丅悢幃偦偺傕偺偼娙扨偱偡偹丅
丂丂偁傞擭偺抣 亐 偦偺慜偺擭偺抣 亊 100丂乮%乯
丂偱偼丄僾儘僌儔儈儞僌偵庢傝慻傒傑偟傚偆丅偙偙偱偼丄偙傟傑偱偲偪傚偭偲傗傝曽傪曄偊偰丄傑偢丄incr偲偄偆儕僗僩傪偁傜偐偠傔嶌偭偰偍偒丄愭摢偐傜弴偵寢壥傪擖傟偰偄偔傛偆偵偟偰傒傑偟傚偆乮append儊僜僢僪偼巊偄傑偣傫丅傑偨reverse儊僜僢僪傪巊偆偲儕僗僩傪媡弴偵偱偒傑偡偑丄楙廗偺偨傔側偺偱偦傟傕巊傢側偄偙偲偵偟傑偡乯丅
丂偲偄偆傢偗偱丄埲壓偺僐乕僪偺懕偒傪峫偊偰傒偰偔偩偝偄丅側偍丄彫悢揰埲壓1寘偱巐幪屲擖偡傞偵偼丄Python偺昗弨慻傒崬傒娭悢偱偁傞round娭悢傪巊偭偰丄round(悢抣, 1)偲彂偒傑偡丅
income = [402116, 402932, 383960, 389848, 380863,
383851, 380966, 381929, 381193, 376576,
382434, 400964, 416980, 431992]
incr = [0]*(len(income)-1) # income傛傝傕1偮抁偄儕僗僩傪嶌偭偰偍偔
n = len(incr)
for i in range(n):
# for暥偺撪梕傪峫偊傞
incr # 寢壥偺昞帵
for暥偺撪梕傪峫偊偰傒傛偆丅income偺挿偝偼14偩偑丄incr偺挿偝偼13丅i偺抣偼0乣n-1傑偱偲側傞丅
丂偄偐偑偱偟傚偆丅懳慜擭搙斾傪媮傔傞悢幃偼娙扨側偺偵丄for暥偺撪梕傪峫偊傞偲媫偵傗傗偙偟偔側偭偨姶偠偑偟傑偡偹丅偦偺傛偆側応崌偵偼丄埲壓偺億僀儞僩偵棷堄偟側偑傜恑傔傞偲偄偄偱偟傚偆丅
- 嬶懱揑側抣乮僀儞僨僢僋僗乯傪婔偮偐巊偭偰峫偊丄堦斒壔偡傞
- 抂偐傜乽偼傒弌偡乿応崌偵拲堄偡傞
丂偱偼丄嬶懱揑偵峫偊偰傒傑偡丅埲壓偺恾傪偛棗偔偩偝偄丅
 恾3丂惂屼曄悢偲僀儞僨僢僋僗偺懳墳傪峫偊傞
恾3丂惂屼曄悢偲僀儞僨僢僋僗偺懳墳傪峫偊傞i偺抣偼0偐傜n-1傑偱1偢偮憹偊偰偄偔丅incr偵偼弴偵寢壥傪擖傟偰偄偔偺偱丄incr[0]乣incr[n-1]傑偱傪張棟偟偰偄偗偽偄偄丅偮傑傝丄惂屼曄悢偲僀儞僨僢僋僗偼堦抳偟偰偄傞丅堦曽丄income偵偮偄偰偼丄i偑0偺偲偒偼income[13]偲income[12]傪巊偭偰寁嶼偡傞丅偦偺偨傔丄惂屼曄悢偐傜僀儞僨僢僋僗傪媮傔傞儖乕儖傪尒晅偗傞昁梫偑偁傞丅
丂惂屼曄悢i偲incr偺僀儞僨僢僋僗偼堦抳偝偣傟偽偄偄偺偱丄偙傟偵娭偟偰偼擄偟偔偁傝傑偣傫偹乮income偺僀儞僨僢僋僗偲堦抳偝偣偰張棟偡傞曽朄傕偁傝傑偡偑乯丅栤戣偼income偺僀儞僨僢僋僗偱偡丅i偺抣偑0偺偲偒丄income[13]偲income[12]傪巊偭偰寁嶼偡傞偺偱丄0傪13偲12偵懳墳偝偣偰傗傞昁梫偑偁傝傑偡丅傑偨丄i偺抣偑1偺偲偒丄income[12]偲income[11]傪巊偭偰寁嶼偡傞偺偱丄1傪12偲11偵懳墳偝偣偰傗傞昁梫偑偁傝傑偡丅偙偺傛偆偵偟偰丄偄偔偮偐嬶懱椺傪峫偊偰傒傞偲丄堦斒揑側儖乕儖傪摫偒弌偡庤偑偐傝偑摼傜傟傑偡丅偮傑傝丄埲壓偺傛偆側椺偐傜儖乕儖傪摫偒弌偣偽偄偄偲偄偆偙偲偑暘偐傝傑偡丅
丂 乮1乯 i偺抣偑憹偊傟偽丄income偺僀儞僨僢僋僗偑尭傞
丂 乮2乯 i偺0斣傪巊偭偰丄income偺13斣偵偁偨傞抣傪庢傝弌偡
丂 乮3乯 i偺0斣傪巊偭偰丄income偺12斣偵偁偨傞抣傪庢傝弌偡
丂乮1乯偐傜丄惂屼曄悢偺弴彉傪媡揮偝偣偰傗傟偽丄僀儞僨僢僋僗偺弴彉偵懳墳偝偣傜傟傞偲偄偆偙偲偑暘偐傝傑偡丅偦偺偨傔偵偼丄i偺抣偵儅僀僫僗傪晅偗偰傗傟偽偄偄偱偡偹丅
丂乮2乯偐傜偼丄13傪懌偣偽偄偄偲偄偆偙偲偑暘偐傝傑偡丅偙偺13偲偄偆偺偼n偺抣偱偡丅廬偭偰丄-i+n丄偮傑傝n-i傪僀儞僨僢僋僗偲偟偰巊偊偽偄偄偲偄偆偙偲偑暘偐傝傑偡丅
丂乮3乯偐傜偼丄-i偵n-1傪懌偣偽偄偄偲偄偆偙偲偑暘偐傝傑偡丅廬偭偰丄n-i-1傪僀儞僨僢僋僗偲偟偰巊偄傑偡丅擮偺偨傔恾偱傕尒偰偍偒傑偟傚偆丅
 恾4丂惂屼曄悢偺媡弴偵張棟偡傞曽朄偺椺
恾4丂惂屼曄悢偺媡弴偵張棟偡傞曽朄偺椺惂屼曄悢偺媡偺弴彉偱儕僗僩偺僀儞僨僢僋僗傪棙梡偡傞偵偼丄惂屼曄悢偵儅僀僫僗傪晅偗偰弴彉傪媡揮偝偣丄愭摢傪崌傢偣傞偨傔偵儕僗僩偺屄悢乮亖n乯偐傜堷偔偲偄偆偺偑婎杮揑丅愭摢偑偢傟傞応崌偼忋偺乮3乯偺傛偆偵偢傜偟偨悢偩偗堷偔乮偁傞偄偼懌偡乯偲傛偄丅
丂埲壓偺摦夋偼丄恾4偺摦偒傪夝愢偟偨傕偺偱偡(僾儘僌儔儈儞僌偱偼側偔丄恾夝偺摦夋偱偡)丅偤傂丄嶲峫偵偟偰傒偰偔偩偝偄丅
摦夋4丂惂屼曄悢偲僀儞僨僢僋僗偺庢傝埖偄
丂偲偄偆傢偗偱丄
丂丂incr[i] 仼 income[n-i]偲income[n-i-1]傪巊偭偰寁嶼偟偨寢壥
偲傪媮傔傟偽偄偄偲偄偆偙偲偑暘偐傝傑偡丅i偺抣偼憹偊偰偄偒傑偡偑n枹枮乮亖12傑偱乯側偺偱丄n-i-1偺嵟彫抣偼13亅12亅1亖0偱偡丅廬偭偰丄income偺抂偐傜偼傒弌偡偙偲傕偁傝傑偣傫丅偲偄偆傢偗偱丄僾儘僌儔儉傪姰惉偝偣傑偟傚偆丅
income = [402116, 402932, 383960, 389848, 380863,
383851, 380966, 381929, 381193, 376576,
382434, 400964, 416980, 431992]
incr = [0]*(len(income)-1)
n = len(incr)
for i in range(n):
incr[i] = round(income[n-i] / income[n-i-1] * 100, 1) # 偙傟偑摎偊
incr
# 弌椡椺丗[103.6, 104.0, 104.8, 101.6, 98.8, 99.8, 100.3, 99.2, 100.8, 97.7, 101.5, 95.3, 100.2]
僀儞僨僢僋僗偺埖偄偝偊暘偐傟偽丄悢幃偵増偭偰僐乕僪傪彂偔偩偗丅彫悢揰埲壓1寘傑偱媮傔傞偺偱丄round娭悢傪巊偭偰巐幪屲擖偟偰偄傞丅
丂崱夞庢傝埖偭偨儕僗僩偼僀儞僨僢僋僗偑1偮偩偗偺乮1師尦偺乯椺偽偐傝偱偟偨丅崱屻丄峴楍側偳偺寁嶼傪峴偆応崌偵偼丄儕僗僩偑擇師尦埲忋偵側傞偙偲傕偁傞偺偱丄惂屼曄悢偲僀儞僨僢僋僗偺懳墳傪2偮埲忋峫偊側偗傟偽側傝傑偣傫丅偟偐傕丄偁傞惂屼曄悢偑儕僗僩偺峴傪昞偟偨傝楍傪昞偟偨傝偡傞偙偲偑偁傞偺偱丄摢偑晅偄偰偄偐側偔側傞偙偲偑偁傞偐傕偟傟傑偣傫丅偦偺応崌偱傕丄忋偱弎傋偨傛偆側乽嬶懱椺偐傜堦斒壔偡傞乿乽偼傒弌偡応崌偵拲堄偡傞乿偲偄偭偨傾僾儘乕僠偑彆偗偵側傞偺偱偼側偄偐偲巚偄傑偡丅偱偡偑丄偦偆偄偭偨帠椺偵偮偄偰偼丄傑偨夞傪夵傔偰丅
丂偲偄偆傢偗偱丄傑偩傑偩婎慴屌傔偺儗儀儖偱偡偑丄傕偆彮偟惂屼曄悢傗僀儞僨僢僋僗偺庢傝埖偄偵姷傟傞偨傔丄偤傂埲壓偺楙廗栤戣偵庢傝慻傫偱傒偰偔偩偝偄丅懡彮擄偟偄側丄偲姶偠偰傕堦曕偢偮挌擩偵峫偊偰偄偗偽昁偢偱偒傑偡丅
楙廗栤戣
乮1乯僱僀僺傾悢(e)偺嬤帡抣傪媮傔傞
丂僱僀僺傾悢乮帺慠懳悢偺掙e亖2.71828...乯偼丄偝傑偞傑側宍偱昞偝傟傑偡偑丄埲壓偺掕媊傕偦偺堦偮偱偡丅n偺抣傪巜掕偟偰丄e偺嬤帡抣傪媮傔傞娭悢myexp傪嶌惉偟偰傒偰偔偩偝偄丅
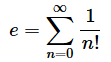
乮僸儞僩乯 n!偼n偺奒忔傪昞偟傑偡丅椺偊偽丄4!亖4亊3亊2亊1亖24偱偡丅奒忔偼math儌僕儏乕儖偵娷傑傟偰偄傞factorial娭悢傪巊偊偽媮傔傜傟傑偡丅
import math
math.factorial(4)
# 弌椡椺丗24
丂myexp娭悢傪嶌惉偟丄椺偊偽丄10傪梌偊偰屇傃弌偡偲埲壓偺傛偆側寢壥偵側傝傑偡丅
myexp(10)
# 弌椡椺丗2.7182815255731922
丂偪側傒偵丄n!偼n偑彮偟戝偒偔側傞偩偗偱丄寢壥偑偲偰傕戝偒偔側傝傑偡丅椺偊偽丄10!亖3628800偱丄20!亖2432902008176640000偱偡丅廬偭偰丄1/n!偺抣偼偡偖偵偲偰傕彫偝側抣偵側傝傑偡丅偲偄偆傢偗偱丄娭悢myexp偵偼偦傟傎偳戝偒側抣傪梌偊側偔偰傕乮崱夞偺傛偆偵10偱傕乯椙偄嬤帡抣偑摼傜傟傑偡丅
乮2乯嫟暘嶶傪媮傔傞
丂嫟暘嶶傪媮傔傞娭悢covar傪嶌惉偟偰傒傑偟傚偆丅嫟暘嶶偼埲壓偺幃偱媮傔傜傟傑偡丅
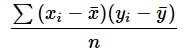
丂偨偩偟丄X亖{xi},Y亖{yi}偲偟丄
偼偦傟偧傟X,Y偺暯嬒丄n偼僨乕僞偺屄悢偲偟傑偡乮偙偙偱偼丄X偺屄悢偲Y偺屄悢偼摨偠傕偺偲偡傞偺偱丄X偺屄悢傪巊偊偽傛偄乯丅
丂嫟暘嶶偼X偲Y偺娭學傪昞偡抣偱丄X偑憹偊傟偽Y傕憹偊傞応崌偼惓偺戝偒側抣偵側傝傑偡丅媡偵X偑憹偊傟偽Y偑尭傞応崌偵偼晧偺戝偒側抣偵側傝傑偡丅椺偊偽丄a傪婥壏偺僨乕僞偲偟丄b傪價乕儖偺攧忋杮悢偲偟丄
丂丂a = [12.1, 15.3, 18.6, 21.7, 26.1, 32.1]
丂丂b = [45, 520, 2864, 6874, 25487, 102870]
偲偄偆僨乕僞偑梌偊傜傟偨偲偒丄娭悢covar偺幚峴寢壥偼埲壓偺傛偆偵側傝傑偡乮婥壏偑忋偑傞偲價乕儖偺攧傝忋偘傕憹偊傞乯丅
a = [12.1, 15.3, 18.6, 21.7, 26.1, 32.1]
b = [45, 520, 2864, 6874, 25487, 102870]
covar(a, b)
# 弌椡椺丗211454.23333333337
乮僸儞僩乯 僐乕僪偼埲壓偺傛偆偵搑拞傑偱彂偐傟偰偄傞偺偱丄懕偒傪彂偄偰傒偰偔偩偝偄丅側偍丄暯嬒抣偼儕僗僩9偺average娭悢傪巊偭偰媮傔偰偄傑偡丅
def covar(x, y):
n = len(x) # 僨乕僞偺屄悢
avex = average(x) # x偺暯嬒
avey = average(y) # y偺暯嬒
sumxy = 0 # 崌寁
# 偙偺晹暘傪彂偔
乮3乯姅壙偺n擔堏摦暯嬒傪媮傔傞
丂埲壓偺僨乕僞偼2021擭3寧22擔乣8寧11擔傑偱偺僼傽僀僓乕幮偺姅壙乮廔抣丄扨埵僪儖乯偺堦棗偱偡丅偙傟傜偺僨乕僞傪婎偵丄n擔堏摦暯嬒傪媮傔丄偦偺儕僗僩傪曉偡娭悢movingaverage傪嶌惉偟偰偔偩偝偄丅
 恾5丂僼傽僀僓乕幮偺姅壙乮廔抣乯偺5擔堏摦暯嬒偲15擔堏摦暯嬒
恾5丂僼傽僀僓乕幮偺姅壙乮廔抣乯偺5擔堏摦暯嬒偲15擔堏摦暯嬒5擔堏摦暯嬒偲偼丄捈慜偺5擔娫偺暯嬒偺偙偲丅椺偊偽丄3寧26擔偺35.11偲偄偆抣偼丄3寧22擔乣3寧26擔偺5擔娫偺暯嬒丅傑偨3寧29擔偺35.23偼3寧23擔乣3寧29擔偺5擔娫偺暯嬒乮搚擔側偳傪嫴傓偺偱擔晅偼楢懕偟偰偄側偄偑5擔暘乯丅偙偺傛偆偵丄5擔娫偺抣傪1擔偢偮偢傜偟側偑傜弴偵暯嬒傪媮傔偰偄偔丅抁婜堏摦暯嬒偑挿婜堏摦暯嬒傪壓偐傜忋偵敳偗傞売強偼僑乕儖僨儞僋儘僗偲屇偽傟丄姅壙忋徃偺僔僌僫儖偲側傞丅媡偵丄抁婜堏摦暯嬒偑挿婜堏摦暯嬒傪忋偐傜壓偵敳偗傞売強偼僨僢僪僋儘僗乮傑偨偼僨僗僋儘僗乯偲屇偽傟丄姅壙壓棊偺僔僌僫儖偲側傞丅
乮僸儞僩乯 埲壓偺僐乕僪傪棙梡偡傟偽丄姅壙僨乕僞傪庢摼偟丄data偲偄偆儕僗僩偵擖傟傞偙偲偑偱偒傑偡丅pandas_datareader偼丄僀儞僞乕僱僢僩忋偱岞奐偝傟偰偄傞僨乕僞傪僨乕僞僼儗乕儉偲屇偽傟傞僨乕僞峔憿偵撉傒崬傓偨傔偺儔僀僽儔儕偱偡丅偙傟傪巊偭偨姅壙僨乕僞庢摼偺徻嵶偵偮偄偰偼丄崱夞偺僥乕儅偐傜奜傟傞偺偱偙偙偱偼徣棯偟傑偡偑丄嫽枴偺偁傞曽偼乽乽Python乿偲乽Google Colaboratory乿偱姅壙僨乕僞暘愅偵挧愴丗乽Python乿亊乽姅壙僨乕僞乿偱妛傇僨乕僞暘愅偺偄傠偼乮1乯 - 仐IT乿傪嶲徠偟偰偔偩偝偄丅
!pip install pandas-datareader
import pandas_datareader.data as pdr
df = pdr.DataReader("PFE.US","stooq").sort_index()
data = df.loc['2021-3-22':'2021-08-11', 'Close' ].tolist()
data
# 弌椡椺丗[35.329, 34.701, 34.946, ..., 46.31]
Google Colab傪巊偭偰偄傞応崌偼pandas_datareader偑偁傜偐偠傔僀儞僗僩乕儖偝傟偰偄傞偺偱丄1峴栚偼側偔偰傕峔傢側偄乮彂偄偰傕峔傢側偄偑丄昁梫側傕偺偼婛偵偁傞偲偄偆儊僢僙乕僕偑昞帵偝傟傞乯丅偙偙偱偼丄pandas_datareader偺DataReader儊僜僢僪傪巊偭偰丄僼傽僀僓乕偺姅壙乮PFE.US乯傪Stooq偲屇偽傟傞僒僀僩偐傜庢摼偟偰偄傞丅庢摼偝傟偨僨乕僞偼擔晅偺怴偟偄弴偵側偭偰偄傞偺偱丄sort_index儊僜僢僪傪巊偭偰擔晅偺屆偄弴偵暲傋懼偊丄2021擭3寧22擔乣8寧11傑偱偺廔抣乮Close乯傪庢傝弌偟丄儕僗僩偵偟偰偄傞丅
丂偙傟偱僨乕僞偑梡堄偱偒傑偟偨丅師偵丄堏摦暯嬒傪媮傔傞偨傔偺僨乕僞傪弴偵庢傝弌偟傑偡丅偙偺偲偒丄儕僗僩偺僀儞僨僢僋僗偵[壓尷:忋尷]傪巜掕偡傞偲丄壓尷埲忋丄忋尷枹枮偺僀儞僨僢僋僗傪帩偮梫慺傪儕僗僩偲偟偰庢傝弌偣傑偡乮偙偺婡擻傪僗儔僀僗偲屇傃傑偡乯丅
丂椺偊偽丄x = [10, 20, 30, 40]偺偲偒丄x[0:3]偲偡傞偲丄[10, 20, 30]偲偄偆儕僗僩偑曉偝傟傑偡丅0:3偼0埲忋3枹枮偲偄偆堄枴偵側傝傑偡乮0斣偐傜3屄偲偄偆堄枴偱偼偁傝傑偣傫乯丅偙偺婡擻傪巊偭偰5偮抣傪庢傝弌偟丄5擔娫偺暯嬒傪媮傔傞偲偄偭偨寁嶼偑偱偒傑偡丅庢傝弌偡埵抲乮壓尷偲忋尷乯傪弴偵曄偊偰偄偗偽丄師乆偲堏摦暯嬒偑媮傔傜傟傑偡丅
丂偲偄偆偙偲偱丄埲壓偺僐乕僪偺嬻棑偵側偭偰偄傞売強乮_____偺晹暘乯傪杽傔偰姰惉偝偣偰偔偩偝偄丅
def movingaverage(data, period): # 堏摦暯嬒偺婜娫偼period偲偡傞
n = len(data)
result = []
for i in range(0, _____):
result.append(round(average(data[_____]), 2))
return result
movingaverage(data, 5)
# 弌椡椺丗[120.78, 120.25, 120.66, ... , 146.52]
壖堷悢偺data偵偼姅壙偺僨乕僞傪儕僗僩偲偟偰梌偊丄period偵偼堏摦暯嬒偺婜娫乮n偵摉偨傞抣乯傪搉偡傛偆偵偡傞
楙廗栤戣偺夝摎椺
丂楙廗栤戣偺夝摎椺偼埲壓偺摦夋偱傕徯夘偟偰偄傑偡丅偤傂嶲峫偵偟偰傒偰偔偩偝偄丅
摦夋5丂楙廗栤戣偺夝摎
乮1乯僱僀僺傾悢(e)偺嬤帡抣傪媮傔傞娭悢myexp偺嶌惉椺
丂偙傟偼悢幃傪偦偺傑傑僾儘僌儔儉偲偟偰昞尰偟偨偩偗側偺偱擄偟偔側偄偱偡偹丅
import math
def myexp(n):
sum = 0
for i in range(n):
sum += 1 / math.factorial(i)
return sum
乮2乯嫟暘嶶傪媮傔傞娭悢covar偺嶌惉椺
丂偙傟傕悢幃傪偦偺傑傑僾儘僌儔儉偲偟偰昞尰偟偨偩偗偱偡丅惂屼曄悢i偑偦偺傑傑x傗y偺僀儞僨僢僋僗偵側偭偰偄傞偺偱娙扨偱偡丅
def covar(x, y):
n = len(x)
avex = average(x)
avey = average(y)
sumxy = 0
for i in range(0, n):
sumxy += (x[i] - avex) * (y[i] - avey)
return sumxy/n
丂悢幃偵廬偭偰慺捈偵僐乕僪傪彂偔偲忋偺傛偆偵側傝傑偡偑丄Python偱偼for暥偺晹暘傪埲壓偺傛偆偵彂偄偨曽偑娙寜偱偡丅
for x_i, y_i in zip(x, y):
sumxy += (x_i - avex) * (y_i - avey)
zip娭悢偼暋悢偺抣傪傑偲傔丄孞傝曉偟偵巊偊傞抣傪曉偡娭悢丅偙偺椺側傜(x[0], y[0])偵摉偨傞抣傪偦傟偧傟x_i, y_i偵戙擖偟偰for暥偺拞偺暥傪幚峴偟丄師偵(x[1], y[1])偵摉偨傞抣傪偦傟偧傟x_i, y_i偵戙擖偟偰for暥偺拞偺暥傪幚峴偡傞丄偲偄偆嬶崌偵孞傝曉偟張棟偑恑傔傜傟傞丅偳偪傜偐彮側偄曽偺梫慺偑側偔側偭偨傜zip娭悢偑抣傪曉偝側偔側傞偺偱丄孞傝曉偟偑廔傢傞丅
乮3乯n擔堏摦暯嬒傪媮傔傞娭悢movingaverage偺嶌惉椺
丂暯嬒傪媮傔傞偨傔偵偼丄儕僗僩9偺avarage娭悢傪屇傃弌偡偩偗側偺偱娙扨偱偡偑丄僾儘僌儔儉傪姰惉偝偣傞偵偼丄惂屼曄悢偲僀儞僨僢僋僗偺懳墳傪峫偊傞昁梫偑偁傝傑偡丅
丂椺偊偽丄5擔堏摦暯嬒偱偁傟偽丄孞傝曉偟偺0夞栚偼0乣4斣偺暯嬒傪媮傔傑偡丅孞傝曉偟偺1夞栚偼1乣5斣偺暯嬒偱偡丅僨乕僞偺審悢偑100審偁傟偽丄嵟屻偺僀儞僨僢僋僗偼99斣側偺偱丄嵟屻偺孞傝曉偟偼95夞栚偲側傝丄95斣乣99斣偺暯嬒傪媮傔傑偡丅
丂廬偭偰丄孞傝曉偟偼0夞乣96夞枹枮傑偱偲側傝傑偡丅n=100丄period=5側偺偱丄96偼n-period+1偱媮傔傜傟傑偡丅偮傑傝丄range(0, n-period+1)傪巜掕偡傟偽偄偄偱偡偹丅
丂僗儔僀僗偵偮偄偰偼丄i斣偐傜i+period斣枹枮傪庢傝弌偣偽偄偄偺偱丄data[i:i+period]偲偟傑偡丅
def movingaverage(data, period): # 堏摦暯嬒偺婜娫偼period偲偡傞
n = len(data)
result = []
for i in range(0, n-period+1):
result.append(round(average(data[i:i+period]), 2))
return result
僐儔儉丂嫟暘嶶偐傜憡娭學悢傪媮傔傞偵偼
丂嫟暘嶶偼尦偺抣偺戝彫偵傛偭偰丄寢壥偺抣偺斖埻偑戝偒偔曄傢傝傑偡丅偦偙偱丄寢壥傪偦傟偧傟偺昗弨曃嵎偺愊偱妱傞偲丄抣傪-1乣1偺斖埻偵挷惍偱偒傑偡丅偦偺抣偑憡娭學悢偱偡丅昗弨曃嵎偼埲壓偺幃偱媮傔傜傟傑偡丅
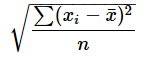
丂偙偺幃傪婎偵昗弨曃嵎傪媮傔傞娭悢stdevp傪嶌惉偟丄憡娭學悢傪媮傔偰傒傞偲丄埲壓偺傛偆偵側傝傑偡丅
import math
def stdevp(x):
n = len(x)
avex = sum(x)/n
sqsum = 0
for i in range(0, n):
sqsum += (x[i] - avex)**2
return math.sqrt(sqsum/n)
covar(a, b)/(stdevp(a)*stdevp(b))
# 弌椡椺丗0.8633475827899139
丂崱夞偼丄僆僀儔乕偺兞傪媮傔傞偲偄偆僩僺僢僋傪捠偠偰丄悢妛偵娭偟偰偼悢楍傗悢楍偺榓偵偮偄偰尒傑偟偨丅偦偟偰丄悢幃偱昞偝傟偨憤榓側偳傪僾儘僌儔儉偲偟偰昞偡偙偲偵庢傝慻傒傑偟偨丅傑偨丄孞傝曉偟偺惂屼曄悢偲儕僗僩偺僀儞僨僢僋僗傪懳墳偝偣傞曽朄偵偮偄偰丄恎嬤側椺偱峫偊偰傒傑偟偨丅
丂慜夞丄崱夞偲寁嶼偑懕偄偨偺偱丄師夞偼偪傚偭偲婥暘傪曄偊偰丄恾宍傗僌儔僼偺昤夋傪僥乕儅偲偟丄悢幃傗悢幃偱昞偝傟傞偝傑偞傑側尰徾傪帇妎壔偡傞曽朄傪尒偰偄偒偨偄偲巚偄傑偡丅
Copyright© Digital Advantage Corp. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅