愊暘朄偺悢抣寁嶼傪僾儘僌儔儈儞僌偟偰傒傛偆丗悢妛亊Python僾儘僌儔儈儞僌擖栧乮3/5 儁乕僕乯
栚昗3丗 儌儞僥僇儖儘朄偵傛傝掕愊暘偺嬤帡寁嶼傪峴偆
丂愊暘側偳偺嬤帡寁嶼傪峴偆応崌偵偼丄棎悢傪棙梡偟偨儌儞僥僇儖儘朄偲屇偽傟傞曽朄傕巊傢傟傑偡丅摨偠椺偽偐傝偱戅孅偐傕抦傟傑偣傫偑丄寢壥偑娙扨偵妋擣偱偒傞偺偱丄偙偙偱傕丄
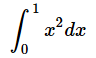
偱峫偊偰傒傑偟傚偆丅
丂儌儞僥僇儖儘朄偺峫偊曽偼嬌傔偰僔儞僾儖偱偡丅偙偺応崌偱偁傟偽丄0 ≤ x < 1, 0 ≤ y < 1 偺斖埻偱棎悢偺儁傾(x,y)傪嶌傝傑偡丅偦偺儁傾偱昞偝傟傞揰偵偼埲壓偺傛偆側2捠傝偺応崌偑偁傝傑偡丅嬶懱椺偱尒偰傒傑偟傚偆丅
- (x, y) 亖 (0.7, 0.2)偺応崌
丂丂仺 x2亖0.49側偺偱丄偙偺揰偺y嵗昗偼x2偺嬋慄傛傝傕壓偵偁傞
丂丂丂丂 仺 傾儈僇働偺晹暘偵擖偭偰偄傞 - (x, y) 亖 (0.4, 0.8)偺応崌
丂丂仺 x2亖0.16側偺偱丄偙偺揰偺y嵗昗偼x2偺嬋慄傛傝傕忋偵偁傞
丂丂丂丂仺 傾儈僇働偺晹暘偵偼擖偭偰偄側偄
丂偙偺2偮偺揰傪僌儔僼忋偵昤夋偟偨偺偑恾4偱偡丅
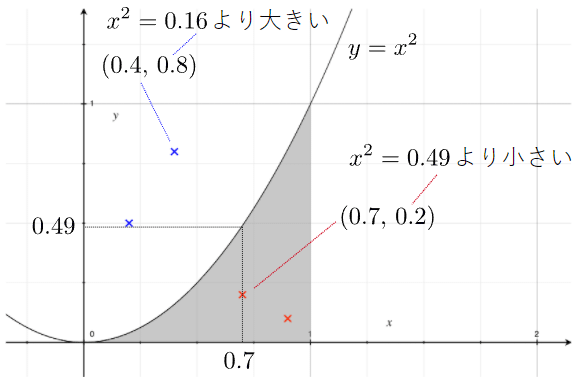 恾4丂儌儞僥僇儖儘朄偵傛傝柺愊傪媮傔傞偨傔偺峫偊曽
恾4丂儌儞僥僇儖儘朄偵傛傝柺愊傪媮傔傞偨傔偺峫偊曽丂偙偺傛偆偵偟偰丄懡悢偺棎悢傪嶌偭偰偄偒丄傾儈僇働偺晹暘偵擖偭偨屄悢傪悢偊丄慡懱偺屄悢偱妱傟偽丄傾儈僇働偺晹暘偺妱崌偑暘偐傝傑偡丅偮傑傝丄乽y < x2側傜丄僇僂儞僩傪憹傗偡乿偲偄偆張棟傪孞傝曉偡傢偗偱偡*2丅偙偺椺偱偼0 ≤ x < 1, 0 ≤ y < 1 偺巐妏偄斖埻偺柺愊偑1側偺偱丄傾儈僇働偺晹暘偺妱崌偑偦偺傑傑柺愊偲側傝傑偡丅

*2丂偙偙偱棙梡偡傞棎悢偼丄斖埻撪偺偳偺抣傕摨偠掱搙偺妋偐傜偟偝偱尰傟傞乽堦條棎悢乿偱偡丅
丂偙傟偼丄0 ≤ x < 1, 0 ≤ y < 1偺巐妏偄揑偵岦偐偭偰丄僟乕僣偺栴傪悢懡偔搳偘偰丄傾儈僇働偺晹暘偵撍偒巋偝偭偨屄悢傪悢偊傞偺偲帡偰偄傑偡乮偦偆偄偆忬嫷傪擼棤偵巚偄晜偐傋偰傒偰偔偩偝偄乯丅僟乕僣偺栴偼儔儞僟儉偵搳偘傑偡偑丄昁偢巐妏偄斖埻偺偳偙偐偵撍偒巋偝傞傕偺偲偡傟偽丄乽傾儈僇働偺晹暘偵撍偒巋偝偭偨栴偺悢亐慡懱偺栴偺悢乿偑丄傾儈僇働偺晹暘偺妱崌偵嬤偔側傞偲偄偆傢偗偱偡丅
3. 儌儞僥僇儖儘朄偵傛傞愊暘傪僾儘僌儔儈儞僌偡傞
丂偱偼丄僾儘僌儔儈儞僌偵庢傝偐偐傝傑偟傚偆乮儕僗僩12乯丅棎悢偼random儌僕儏乕儖傪巊偭偰嶌惉偡傞偙偲傕偱偒傑偡偑丄NumPy偺random儌僕儏乕儖偱傕嶌惉偱偒傞偺偱乮偦偺曽偑壗偐偲曋棙側偺偱乯丄偦偪傜傪棙梡偟傑偡丅
import numpy as np
def monte(n):
count = 0
for i in range(n):
x = np.random.random() # 0埲忋1枹枮偺棎悢傪嶌惉偡傞
y = np.random.random()
if y < x**2:
count += 1
return count / n
堷悢n偵偼丄敪惗偝偣傞棎悢偺儁傾偺屄悢傪巜掕偡傞丅NumPy偺random.random娭悢偼0埲忋1枹枮偺堦條棎悢傪嶌惉偡傞偨傔偺娭悢丅x2傛傝傕y偺抣偑彫偝偗傟偽丄擇師嬋慄傛傝傕壓偵偁傞偺偱丄屄悢count傪憹傗偡丅嵟屻偵count傪慡懱偺屄悢n偱妱偭偨抣傪曉偡丅
丂幚峴椺偼埲壓偺捠傝偱偡丅
print(monte(1000))
# 弌椡椺丗0.335
print(monte(10000))
# 弌椡椺丗0.3382
print(monte(100000))
# 弌椡椺丗0.33369
棎悢傪巊偭偰偄傞偺偱丄寢壥偼枅夞曄傢傞偑丄10枩夞偺孞傝曉偟偱0.33369偲側偭偨丅
丂棎悢偼枅夞堎側傞傕偺偑巊傢傟傞偺偱丄寢壥偼幚峴偡傞偨傃偵堎側傝傑偡丅枅夞摨偠寢壥傪摼偨偄偺偱偁傟偽丄seed傪寛傔偰偍偄偰傗傞偲偄偄偱偟傚偆丅seed乮庬乯偲偼棎悢傪嶌惉偡傞嵺偺弶婜愝掕偺偨傔偵巊傢傟傞抣偺偙偲偱偡乮seed傪巜掕偟側偄応崌偼僔僗僥儉偺帪崗偑巊傢傟傞偺偱丄枅夞堎側傞暲傃偺棎悢偑嶌傜傟傑偡乯丅埲壓偺僐乕僪傪丄儕僗僩12偺count=0偺師偵彂偄偰傒偰偔偩偝偄丅
np.random.seed(0)
丂偙偺傛偆偵彂偄偰偍偗偽丄枅夞摨偠棎悢偑嶌惉偝傟傑偡乮抣偼儔儞僟儉偱偡偑丄抣偺暲傃偼枅夞摨偠偵側傞偲偄偆偙偲偱偡乯丅偦偺応崌偺幚峴椺偼埲壓偺傛偆偵側傝傑偡丅
print(monte(1000))
# 弌椡椺丗0.327
print(monte(10000))
# 弌椡椺丗0.3336
print(monte(100000))
# 弌椡椺丗0.33347
棎悢偺seed傪屌掕偡傞偲丄枅夞摨偠寢壥偑媮傔傜傟傞丅僒儞僾儖僾儘僌儔儉偲摨偠寢壥偵側傞偐摦嶌妋擣偡傞応崌側偳偵曋棙丅
儌儞僥僇儖儘朄偺壜帇壔
丂偣偭偐偔側偺偱丄傾儈僇働偺晹暘偵擖偭偨揰傪壜帇壔偟偰偍偒傑偟傚偆丅 y < x2偺偲偒偵1偮偢偮揰傪懪偮偲張棟偵帪娫偑偐偐傞偺偱丄y < x2偲側傞慡偰偺揰傪Python偺儕僗僩偵婰榐偟偰偍偒丄偦偺儕僗僩傪巊偭偰嶶晍恾傪嶌惉偟傑偡丅儕僗僩15偺娭悢monte_mkdata偼丄傾儈僇働偺晹暘偵擖傞慡偰偺揰偺嵗昗傪曉偡娭悢偱偡丅
import numpy as np
def monte_mkdata(n):
np.random.seed(0)
px = []
py = []
for i in range(n):
x = np.random.random()
y = np.random.random()
if y < x**2:
px.append(x)
py.append(y)
return px, py
堷悢n偵偼孞傝曉偟悢傪巜掕偡傞丅y < x2偲側傞x偲y傪偦傟偧傟px丄py偵捛壛偟偰偄偔丅曉傝抣偼px偲py丅偙偺娭悢偼僨乕僞傪嶌惉偡傞偩偗偱丄柺愊偺嬤帡抣偼媮傔偰偄側偄丅
丂娭悢monte_mkdata傪巊偭偰僨乕僞傪嶌惉偟丄嶶晍恾傪昤偄偰傒傑偟傚偆乮儕僗僩16乯丅
import matplotlib.pyplot as plt
# 嶶晍恾傪昤偔
plt.scatter(*monte_mkdata(10000), s=1, c="red")
# y=x**2偺僌儔僼傪廳偹偰昤偔
xrange = np.arange(0, 1, 0.01)
plt.plot(xrange, xrange**2)
plt.show()
scatter娭悢偺嵟弶偺堷悢偑monte_mkdata偵傛偭偰嶌惉偟偨揰偺嵗昗丅s=1偼揰偺僒僀僘傪1偲偡傞偲偄偆巜掕丅c="red"偼揰偺怓偺巜掕丅y亖x2偺僌儔僼傕崌傢偣偰昤偄偰偍偄偨丅
丂偙偙偱偼丄monte_mkdata(10000)偺慜偵彂偐傟偰偄傞*偵拲堄偟偰偔偩偝偄丅偙傟偼丄儕僗僩傗僞僾儖偺梫慺傪揥奐偡傞偲偄偆堄枴偱偡丅偮傑傝丄monte_mkdata(10000)偑曉偟偨(x, y)偲偄偆僞僾儖傪屄暿偺梫慺偱偁傞x偲y偵暘偗丄plt.scatter偺堷悢偲偟偰x偲y傪偦傟偧傟巜掕偡傞偙偲偵側傝傑偡丅幚峴椺偼埲壓偺捠傝偱偡丅
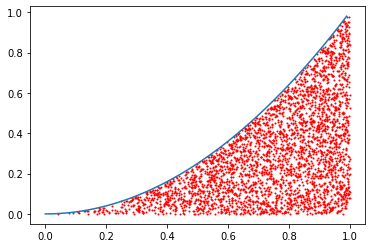 恾5丂儌儞僥僇儖儘朄偵傛偭偰嶌惉偝傟偨揰傪僾儘僢僩偡傞
恾5丂儌儞僥僇儖儘朄偵傛偭偰嶌惉偝傟偨揰傪僾儘僢僩偡傞僐儔儉丂NumPy偺婡擻傪妶梡偟偰孞傝曉偟張棟傪攔彍偡傞
丂NumPy偺random.random娭悢偵堷悢傪巜掕偡傞偲丄巜掕偟偨屄悢偺棎悢傪NumPy偺攝楍乮ndarray乯偲偟偰嶌惉偟偰偔傟傑偡丅偦偺婡擻傪棙梡偡傟偽丄孞傝曉偟張棟傪巊傢偢偵僐乕僪傪彂偔偙偲傕偱偒傑偡乮儕僗僩17乯丅
import numpy as np
def monte_np(n):
np.random.seed(0)
x = np.random.random(n) # n屄偺棎悢
y = np.random.random(n)
result = y < x**2 # True偐False偐偺攝楍偑曉偝傟傞
return np.count_nonzero(result) / n # True偺屄悢傪慡懱偺屄悢偱妱傞
傑偢n屄偺棎悢傪嶌惉偟丄偦傟傪x偲偡傞丅師偵n屄偺棎悢傪嶌惉偟丄偦傟傪y偲偡傞丅result偵偼丄y < x**2偺慡偰偺寢壥乮True傑偨偼False乯偑攝楍偲偟偰曉偝傟傞丅True偺悢傪悢偊傞偵偼丄count_nonzero娭悢偑曋棙丅偙偺娭悢偼僛儘偱側偄抣偺屄悢傪悢偊傞傕偺偩偑丄False偼僛儘偲尒側偝傟傞偺偱丄True偺屄悢偑悢偊傜傟傞丅
丂偨偩偟丄孞傝曉偟張棟傪巊偭偨椺乮儕僗僩13乯偱偼丄棎悢傪丄
丂丂x偺抣丄y偺抣丄師偺x偺抣丄師偺y偺抣乧乧
偲偄偆弴偵嶌惉偟偰偄傑偟偨偑丄忋偺僐乕僪偱偼丄
丂丂x偺抣傪n屄嶌惉偟偨屻丄y偺抣傪n屄嶌惉偟偰偄傞
偺偱丄幚峴寢壥偼堎側傝傑偡乮椺偊偽丄monte_np(1000)傪幚峴偡傞偲丄寢壥偼0.331偵側傝傑偡乯丅儕僗僩13偺幚峴椺乮儕僗僩14乯偲姰慡偵摨偠寢壥乮0.327乯偑梸偟偗傟偽丄儕僗僩18偺傛偆偵丄棎悢傪2n屄嶌惉偟丄嬼悢斣栚傪x偵丄婏悢斣栚傪y偵戙擖偡傞偲偄偄偱偟傚偆丅
import numpy as np
def monte_np(n):
np.random.seed(0)
data = np.random.random(2*n) # 2n屄偺棎悢傪堦婥偵嶌傞
x = data[0::2] # 0斣偐傜憹暘抣2偱弴偵庢傝弌偡
y = data[1::2] # 1斣偐傜憹暘抣2偱弴偵庢傝弌偡
result = y < x**2
return np.count_nonzero(result) / n
NumPy偺攝楍偱偼丄[start:stop:step]偺宍幃偱丄晹暘攝楍傪庢傝弌偡偙偲偑偱偒傞乮僗儔僀僗婡擻偲屇偽傟傞乯丅start傪徣棯偡傞偲0偑巜掕偝傟偨傕偺偲尒側偝傟丄stop傪徣棯偡傞偲枛旜傑偱偑巜掕偝傟偨傕偺偲尒側偝傟傞丅step傪徣棯偡傞偲1偑巜掕偝傟偨傕偺偲尒側偝傟傞丅
丂偲偼偄偊丄杮棃偺栚揑偼慡偔摨偠寢壥傪摼傞偙偲偱偼側偔丄偁偔傑偱傕嬤帡抣傪摼傞偙偲側偺偱丄摿抜偺棟桼偑側偗傟偽丄儕僗僩17偺傑傑偱峔偄傑偣傫丅傑偨丄儕僗僩18偱x = data[0:n]; y = data[n:]偲偟偰慜敿偺棎悢傪x偵戙擖偟丄屻敿偺棎悢傪y偵戙擖偟偰傕峔偄傑偣傫丅
丂儌儞僥僇儖儘朄傕娙扨偱偟偨偹丅偱偼丄暿偺娭悢傪巊偭偨椺傕尒偰傒傑偟傚偆丅師偼愊暘偲偄偆傛傝偼丄巜掕偝傟偨暘晍偵廬偭偰僨乕僞傪庢傝弌偡乮僒儞僾儕儞僌偡傞乯偙偲傪栚揑偲偟偨椺偱偡丅傕偪傠傫丄僒儞僾儕儞僌偝傟偨僨乕僞傪巊偭偰丄柺愊乮妋棪乯傪媮傔傞偙偲傕偱偒傑偡丅
Copyright© Digital Advantage Corp. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅