TensorFlow 2+Keras(tf.keras)入門
機械学習の勉強はここから始めてみよう。ディープラーニングの基盤技術であるニューラルネットワーク(NN)を、知識ゼロの状態から概略を押さえつつ実装。さらにCNNやRNNも同様に学ぶ。これらの実装例を通して、TensorFlow 2とKerasにも習熟する連載。
TensorFlow 2+Keras(tf.keras)入門:
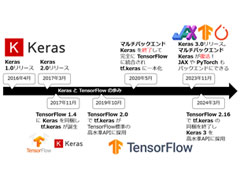
TensorFlow+Kerasの最新情報として、Keras 3.0のリリースに伴い、TensorFlowから独立し、TensorFlow 2.16以降でKeras 3がデフォルトとなったことについて紹介します。また、Keras 3(TensorFlowバックエンド)での書き方や、今後のディープラーニングライブラリの選び方についても私見を示します。

TensorFlow 2+Keras(tf.keras)入門:
分類問題で使える主要な評価関数をまとめ、使い分け指針を示す。具体的には二値分類用の「LogLoss」「AUC」「PR-AUC」を、さらに多クラス分類用の「正解率」「LogLoss」を説明する。
TensorFlow 2+Keras(tf.keras)入門:
二値分類問題で使える基礎的な評価関数をまとめ、使い分け指針を示す。具体的には正解率、適合率、再現率/感度、特異度、F値/F1スコア、重み付きF値/Fβスコアを説明する。
TensorFlow 2+Keras(tf.keras)入門:
回帰問題や時系列予測で使える代表的な評価関数をまとめ、使い分け指針を示す。平均絶対誤差(MAE)、平均二乗誤差(MSE)とその平方根(RMSE)、平均二乗対数誤差(MSLE)とその平方根(RMSLE)、平均絶対パーセント誤差(MAPE)、平均二乗パーセント誤差の平方根(RMSPE)を解説。回帰分析用の決定係数にも触れる。
TensorFlow 2+Keras(tf.keras)入門:
回帰問題の次は、分類問題の基礎をマスターしよう。二値分類/多クラス分類の場合で一般的に使われる活性化関数や損失関数をしっかりと押さえる。また過学習問題の対処方法について言及する。
TensorFlow 2+Keras(tf.keras)入門:
基本的なDNNの知識だけでも、さまざまな問題を解決できる。今回は「回帰問題」を解いてみよう。ディープラーニングの基本部分はワンパターンで、全く難しくないことが体感できるはずだ。
TensorFlow 2+Keras(tf.keras)入門:
Kerasの公式サイト「keras.io」が完全リニューアル。Kerasのインストール方法やkerasモジュールのインポート方法に関する説明が変わった。「tf.kerasに一本化」とはどういうことなのかを解説する。
TensorFlow 2+Keras(tf.keras)入門:
TensorFlow 2.0以降では「サブクラス化」という基本パターンに従って簡単にカスタマイズができる。その全カスタマイズ方法を紹介し、最後にtf.estimator高水準APIについても言及する。

TensorFlow 2+Keras(tf.keras)入門:
TensorFlow 2.x(2.0以降)時代のモデルの書き方として、tf.keras.Modelサブクラス化モデルの書き方を詳しく解説。@tf.functionやAutoGraph、勾配テープといったTensorFlow 2.0の新機能についても触れる。

TensorFlow 2+Keras(tf.keras)入門:
TensorFlow 2.x(2.0以降)では、モデルの書き方が整理されたものの、それでも3種類のAPIで、6通りの書き方ができる。今回は初心者〜初中級者にお勧めの、SequentialモデルとFunctional APIの書き方、全3通りについて説明する。
TensorFlow 2+Keras(tf.keras)入門:
いよいよ、ディープラーニングの学習部分を解説。ニューラルネットワーク(NN)はどうやって学習するのか、Pythonとライブラリではどのように実装すればよいのか、をできるだけ簡潔に説明する。
TensorFlow 2+Keras(tf.keras)入門:
ニューラルネットワーク(NN)の基礎の基礎。NNの基本単位であるニューロンはどのように機能し、Python+ライブラリでどのように実装すればよいのか。できるだけ簡潔に説明。また、活性化関数と正則化についても解説する。
TensorFlow 2+Keras(tf.keras)入門:
機械学習の勉強はここから始めてみよう。ディープラーニングの基盤技術であるニューラルネットワーク(NN)を、知識ゼロの状態から概略を押さえつつ実装してみよう。まずはワークフローを概観して、データ回りの処理から始める。
TensorFlow 2+Keras(tf.keras)入門:
「スタンドアロンKerasとtf.kerasは何が違うのか?」「tf.kerasが、将来的にTensorFlowから削除される可能性はあるのか?」など、TensorFlow 2.0時代のKerasに関する一般的な疑問と、それへのTensorFlowチームメンバーからの回答をまとめる。
注目のテーマ

![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。