もしも、コンパイラ専門書が読めたなら……:Javaでコンパイラの基礎を理解する(6)(1/4 ページ)
前回は字句解析について解説し、字句解析プログラムをいくつか作成しました。今回は、字句解析の結果取得できる字句リストを解析して構文木を生成する構文解析と、その結果を使ってオブジェクトコードを生成する方法について解説をします。
「構文解析」とは、いったい何なのか?
連載第4回で、プログラミング言語S1sはBNFを使って次のように定義しました。
<program> ::= main '{' <expression> '}'
<expression> ::= <term>{ <opeas> <term> }
<term> ::= <factor>{ <opemd> <factor> }
<factor> ::= <number>|( <expression> )
<number> ::= <digit>{<digit>}
<opeas> ::= + | -
<opemd> ::= * | /
<digit> ::= 0|1|2|3|4|5|6|7|8|9
構文解析では、与えられたプログラムのソースコードが、S1sのBNFから生成できるかどうかをチェックし、生成できる場合には構文木を生成します。
 図1 構文解析の位置付け
図1 構文解析の位置付け構文木とは?
生成する構文木は言葉のとおり、木構造のデータになります。連載第2回のコラムで算術式と木構造について説明をしましたが、同じようなものです。
例えば、それぞれ図1〜3のような構文木となります。文法構造は、このように木構造で表しておくことがよくあります。
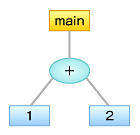 図2 main { 1+2 }の構文木
図2 main { 1+2 }の構文木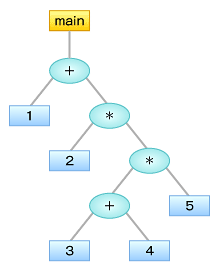 図3 main { 1+2*(3+4)*5 }の構文木
図3 main { 1+2*(3+4)*5 }の構文木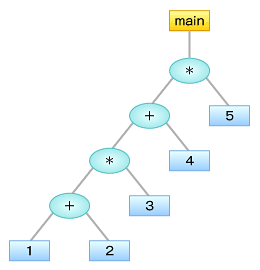 図4 main { ((1+2)*3+4)*5 }の構文木
図4 main { ((1+2)*3+4)*5 }の構文木構文解析によって、字句のリスト構造から、構文を表現する木構造のデータへ変換する必要があることは分かったと思うのですが、具体的にはどのような処理を書けばいいのでしょう?
この処理を実現する構文解析法にはいくつか種類があるのですが、ここでは「下向き構文解析法」という方法を使うことにします。
注意!
なお、変数などを使えるように文法を定義している場合は、このときに名前表というものも生成するのですが、本連載では短い時間でコンパイラの基本的な原理を理解してもらうために、それらの処理については言及しません。ほかにも細かい話はいくつかありますが、それらについては次のステップとし、コンパイラ専門書に譲ることにします。
下向き構文解析法とは?
では、「下向き構文解析法」の説明に入ります。この方法は、与えられた字句リストがBNFで定義されている文法と一致していると仮定し、開始記号から生成される記号列のパターンと照らし合わせながらチェックと構文木の作成をします。説明では分かりにくいのですが、プログラムの流れを見ると、簡単だということが分かるはずです。
与えられた字句リストtokensが最初の生成規則である「 <program> ::= main '{' <expression> '}'」の文法を満たしているかを確認するためには、次のような処理の流れとなります。流れ図として表現すると分かりますが、文法で表現されている記号列について、終端記号はそのまま単純にチェックし、非終端記号については同様にしてチェック用の処理を用意すればよいということが分かります。
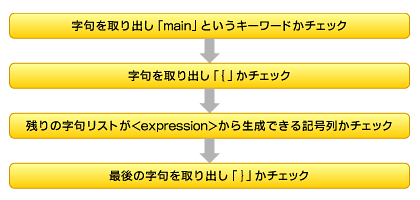 図5 <program>チェックの流れ図
図5 <program>チェックの流れ図拍子抜けするほど簡単に感じた読者も多いと思いますが、BNFで文法を表現したり、字句解析で字句リストを準備しておくことで、構文解析の処理を簡単に実現するための下準備をしていた点を忘れないでください。それらの準備があったからこそ、これからの処理が簡単になるのです。
記号列が字句に分解されていない場合は、区切り文字などについても考慮した処理が必要になりますが、それらは字句解析の時点で行われているので、構文解析では考慮する必要がありません。
バックトラッキングとは?
このように、構文解析の処理は文法の生成規則に従って処理を書くだけなので、簡単に実現できますが、実際に各生成規則について確認してみるといくつかの注意事項が出てきます。
中でも重要な注意事項としては、一度読み込んだ字句について、読み込まなかったことにして処理を続ける場面が出てくるというものがあります。このような後戻り処理のことをバックトラッキングといいますが、次に読み込む字句が何かによって処理の流れが変わることがあるため、この処理が必要なのです。
バックトラッキングの必要性については、「<program> ::= main { <expression> }」をチェックするプログラムの処理の流れだけでは分かりにくいのですが、「残りの字句リストが<expression>から生成できる記号列かチェック」するという処理についてちょっと考えてみると、分かります。
この処理では、内部で最後の字句「}」を読み込んだ時点で処理を終了しますが、読み込んだ字句をそのままにしておくと、「<program> ::= main { <expression> }」をチェックするプログラムで利用できません。ですから、「残りの字句リストが<expression>から生成できる記号列かチェック」するという処理では、最後の字句「}」については終了判定のために読み込みますが、処理の終了時には読み込まなかった状態にして終了する必要があるのです。
実際の構文解析プログラムを紹介する前に重要な点について説明をしましたが、分かりにくい点も多いと思います。実際のコードを見ると、分かってくると思いますから、そこで疑問点は解消するということでも構わないと思います。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。